AprilTagを利用した仮想物体の画像表示 (Augmented Reality)
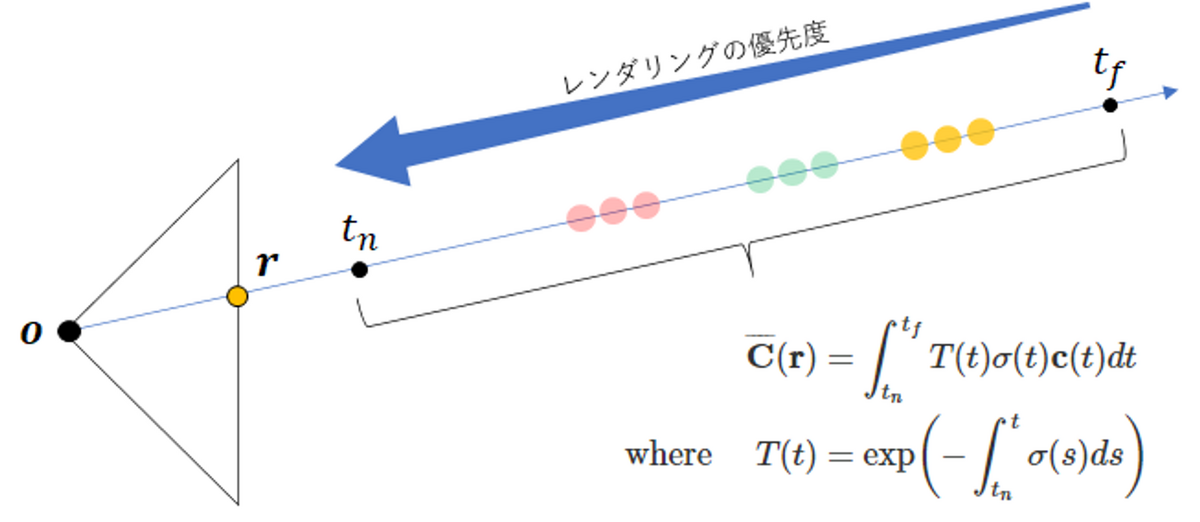
1. はじめに
本記事では、以下の画像のように、画像中のARマーカーを検出する方法についてまとめます。
まず、画像処理によってAprilTagを自動検出します。そして、そのAprilTagを底面とする立方体を可視化するために、カメラの位置や向きを自動的に計算します。
 このような処理を動画の各フレームごとに行うことで、AprilTagを検出しながらカメラの位置を予測し、その位置に立方体を可視化することができます。
このような処理を動画の各フレームごとに行うことで、AprilTagを検出しながらカメラの位置を予測し、その位置に立方体を可視化することができます。

また、カメラの内部パラメータや外部パラメータの計算方法については、カメラキャリブレーションによって求めることができます。内部パラメータはあらかじめ計算しておき、外部パラメータはAprilTagやそのパーツの位置情報を利用して推定します。
以上のように、画像処理やカメラキャリブレーションによって、AprilTagを検出し、カメラの位置や向きを計算して立方体を可視化することができます。2章以降で、その詳細やコードについて説明します。
また、本内容は以下のスライドにもまとめています。
XRミーティング 2023/08/16 #XRMTG
にて発表した資料になります。
2. AprilTagを含む画像から立方体を可視化するための手順について
2.1. 概要
具体的なプロセスは以下の通りです。2.2以降で補足説明を行います。
1 カメラの内部パラメータをチェッカーボードなどを利用して求めておく:
内部パラメータを計算する方法については以前のブログの記事でも紹介しています。よろしければこちらの記事の6.1をご覧ください。
2 AprilTagを自動的に検出する:
以下の画像のように、画像中からAprilTagを自動的に検出します。ここではTagの種類(family)や大きさを事前情報として与えています。

AprilTagの自動検出のより詳しい説明については以下のページをご覧ください。
3 カメラの位置と向きを推定する(外部パラメータの推定):
2にて求めたAprilTagやそのパーツの位置情報を利用してカメラの位置と向きを推定します。詳しくは、以前のブログの記事でも紹介しています。よろしければこちらの記事をご覧ください。
外部パラメータを計算する方法については以前のブログの記事でも紹介しています。よろしければこちらの記事の6章をご覧ください。
4 ワールド座標系で定義される、画像で表示したい物体の座標を用意する:
上の例では、AprilTagを底面とする立方体を可視化したい場面について話していました。その立方体の頂点の座標は、AprilTagを原点として、(1, 0, 0), (0, 0, 0), (-1, 0, 0) …のように表すことができます。上の例では、この立方体の頂点である、8つの座標の値を準備しました。
5 外部パラメータを利用して、ワールド座標系の対象の物体の座標をカメラ座標系に変換する
3で求めた外部パラメータを利用して、ワールド座標系の立方体の8つの頂点が、カメラ座標系ではどのような値になるかを計算します。これにより、AprilTagを原点としたワールド座標系にある立方体の頂点がカメラの光学中心を原点とした、カメラ座標系に変換されます。別の言い方をすると、それらの頂点は(1, 0, 0), (0, 0, 0), (-1, 0, 0) …のような値ではなく、カメラの光学中心から見たときにどのような位置にあるかに変換します。
5~7の処理を以下に図示します。

6 内部パラメータを利用して、カメラ座標系の対象の物体の座標を画像座標に変換する
5では、カメラの光学中心を原点とした、カメラ座標系に変換しましたが、冒頭のデモ動画のような見せ方をするためには、実際の2Dの動画(の各フレームである画像)のどのピクセルに各頂点が位置するかを計算する必要があります。カメラの焦点距離 (focal length) やスキュー (skew)、画像中心 (image center)などをあらかじめ求めておけば幾何的に解くことができます。
7 画像に表示する
6の計算により、カメラ座標系で表される立方体の頂点が、画像平面上でどのピクセルに位置するのかを知ることができます。この計算を立方体の8つの頂点に対して行い、それらの頂点を結ぶことで、画像上に立方体を描画することができます。
8 1~7のプロセスを繰り返す
以上のプロセスを繰り返すことで、動画全体に対して処理を行うことができます。ただし、各フレームにおいて、AprilTagが検出される必要があります。
2.2. ワールド座標系の点の画像座標への変換について
2.1では、ワールド座標系、カメラ座標系、画像座標(系)にて定められる3つの座標が出てきました。これらについて補足を行います。
ワールド座標系は、対象の物体が存在する座標系のことで、ここではAprilTagを原点とします。カメラ座標系は、カメラの光学中心を原点として、z軸をカメラの光軸と一致させたものです。図中の正規化画像座標は焦点距離を1としたもので、焦点距離fの情報などを利用して画像座標と相互に変換が可能です。
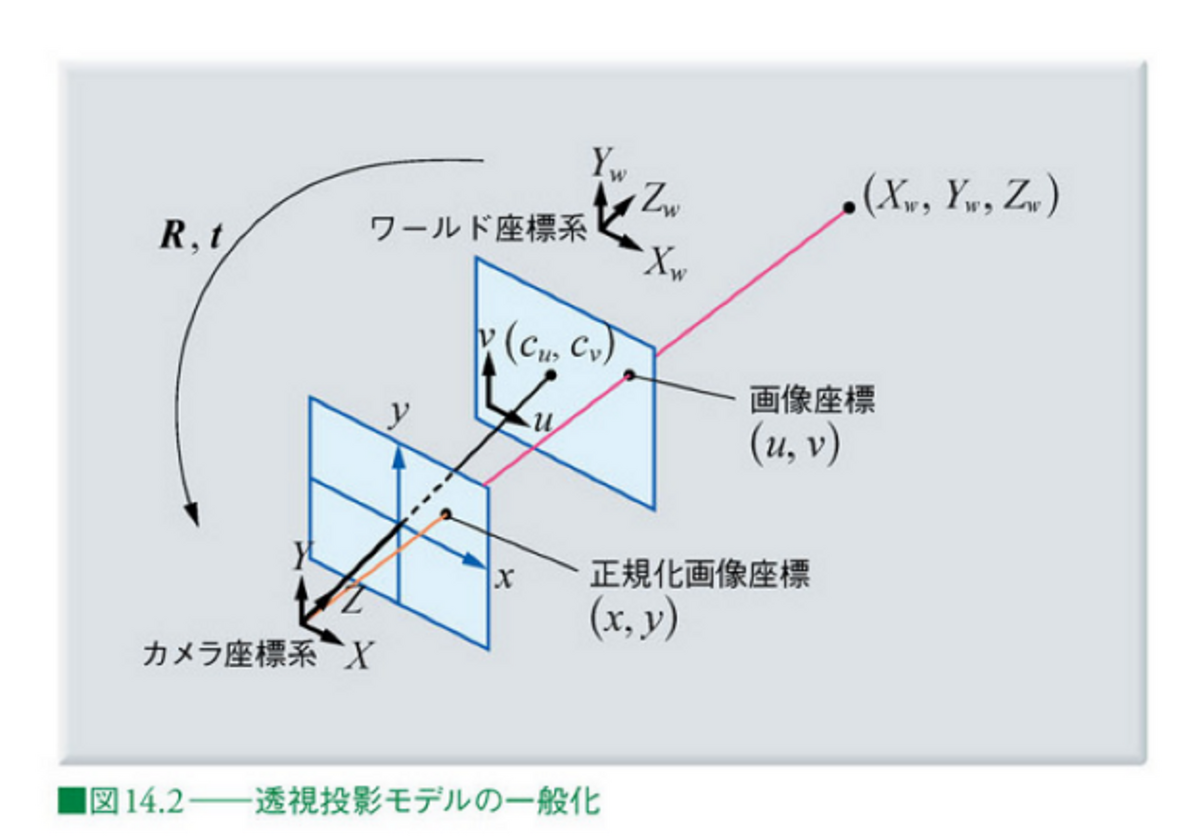
画像出典: ディジタル画像処理 Kindle版 14章
カメラの内部パラメータおよび外部パラメータについては、それぞれ以下の記事が参考になります。
このように、カメラの内部パラメータおよび外部パラメータを利用することで、画像中のARマーカーを検出し、カメラの位置や向きを推定することができます。
2.1の内容と上の記事からそれらの操作を数式で表すと以下のようになることがわかると思います。

...(1)
以下の部分で、ワールド座標系をカメラ座標系に変換し、さらに、

以下の行列と掛け合わせることで、画像座標への変換を行うことができます。

3. ワールド座標系からの画像座標への変換
3章では、2章の流れを実装します。コード全体はgithubにアップロードしているのでそれを参照してください。
まずは、以下に、メインの変換の部分を説明します。以下の点に留意してください。
- あらかじめカメラキャリブレーションをしているため、カメラの内部パラメータは既知である。
- 上の式(1)の、sの値はZcの値と等しくなる。そのため、u, vの値をもとめるためには、計算された値を再度、Zcの値で割ることで求まる
- MATLABコードは以下のとおり
上のプロセスや数式に比べて非常にシンプルに実装することができました。
vertice1 = cuboidVertices(1,:); camCord = tagPose.R*vertice1'+tagPose.Translation'; intrinsicParameters = [intrinsics.FocalLength(1),intrinsics.Skew,intrinsics.PrincipalPoint(1), 0; ... 0, intrinsics.FocalLength(2),intrinsics.PrincipalPoint(2), 0; ... 0, 0, 1, 0]; temp = intrinsicParameters*[camCord;1]; tempNorm = temp/temp(3);
また、立方体の頂点の8点のみでなく、任意の数の点の変換を行えば、画像上に任意の物体を可視化することができます。例えば、ナスの3次元点群に対して同様の処理を行うと、以下のような結果になります。

色々な角度から見たときのナスの様子が可視化されていて楽しいです。 以下に全体の処理についてのコードです。詳細については各コメントアウトを参照してください。
%% Load Video
% Download the video file into a present working directory. Use downloadVideo
% function at the end of this script.
clear;clc;close all
videoFilename = downloadVideo(pwd);
%%
% Load the video to read the first frame.
reader = VideoReader(videoFilename);
I = readFrame(reader);
%%
% Display the first frame.
figure;imshow(I)
%% Load Camera Intrinsics
% Load the camera intrinsics. The intrinsic parameters can be estimated using
% the <docid:vision_ug#btxr8c_-1 Camera Calibrator> app.
data = load("arCameraCalibrationParameters.mat");
intrinsics = data.cameraParams.Intrinsics;
%% Estimate AprilTag Pose
% Specify the size of the AprilTag in millimeters to match the units used during
% camera calibration.
tagSize = 27.7813; % in mm
%%
% Specify the AprilTag family.
tagFamily = "tag36h11";
%%
% Estimate the AprilTag pose.
[~, ~, tagPose] = readAprilTag(I, tagFamily, intrinsics, tagSize);
%%
% The X, Y, and Z axes are represented by red, green, and blue lines, respectively.
annotatedImage = helperInsertXYZAxes(I, tagPose, intrinsics, tagSize);
figure
imshow(annotatedImage)
%%
%
%
% Apply a rotation to the estimated tag pose that rotates the y-axis by 180
% degrees to flip the z-axis.
rotationAngles = [0 180 0];
tform = rigidtform3d(rotationAngles, [0 0 0]);
updatedR = tagPose.R * tform.R;
tagPose = rigidtform3d(updatedR, tagPose.Translation);
%%
% Display the updated world coordinate axes.
annotatedImage = helperInsertXYZAxes(I, tagPose, intrinsics, tagSize);
figure
imshow(annotatedImage)
%% Define Virtual Content
% Define a 3-D cuboid to project onto the top of the AprilTag. The cube is centered
% on the AprilTag and defined to have the same size as the tag.
[cubeWidth, cubeHeight, cubeDepth] = deal(tagSize);
vertices = [ cubeWidth/2 -cubeHeight/2;
cubeWidth/2 cubeHeight/2;
-cubeWidth/2 cubeHeight/2;
-cubeWidth/2 -cubeHeight/2 ];
cuboidVertices = [vertices zeros(4,1);
vertices (cubeDepth)*ones(4,1)];
% Activate the code below to display the egg plant instead of the cube
% pt = pcread('nasu.ply');
% loc = pt.Location - mean(pt.Location);
% loc(:,3) = loc(:,3) - min(loc(:,3));
% colMap = squeeze(label2rgb(round(normalize(pt.Location(:,3),1,"range")*100)));
% cuboidVertices = loc*3;
%% Add Virtual Content to Image
% Use <docid:vision_ref#mw_69af89ba-6463-4387-a15c-7c8e1fa5579f |world2img|>
% to project the virtual cuboid vertices into the image coordinate system.
projectedVertices = world2img(cuboidVertices, tagPose, intrinsics);
%%
% Use <docid:vision_ref#btppvxj-1 |insertShape|> to augment the image with the
% virtual content.
figure
augmentedImage = insertShape(I, "projected-cuboid", projectedVertices, ...
Color="green", LineWidth=6);
% augmentedImage = insertMarker(I, projectedVertices, "circle", "Color",pt.Color);
imshow(augmentedImage)
%%
% Implement world2img function from scratch. Use the first xyz value in the
% vertices.
vertice1 = cuboidVertices(1,:);
% Convert world coordinate into camera coordinate
camCord = tagPose.R*vertice1'+tagPose.Translation';
% Define intrinsic parameters
intrinsicParameters = [intrinsics.FocalLength(1),intrinsics.Skew,intrinsics.PrincipalPoint(1), 0; ...
0, intrinsics.FocalLength(2),intrinsics.PrincipalPoint(2), 0; ...
0, 0, 1, 0];
% Convert camera coordinate into xy value in the image coordinate
temp = intrinsicParameters*[camCord;1];
% As the scale factor is not defined, normalize the temp value using
imgCord = temp/temp(3);
disp('Confirm if the value is same as projectedVertices')
imgCord
%% Visualize Camera Pose in 3-D
% Use the estimated AprilTag pose and camera intrinsics to create a 3-D virtual
% representation of the scene corresponding to the image shown above.
figure;
ax = helperShowVirtualCuboid(cuboidVertices);
%%
% Next, use <docid:vision_ref#mw_4d90cc38-ac81-4889-930f-265305142218 |pose2extr|>
% to convert the tag pose to the camera extrinsics, which represent the camera
% orientation and location in world coordinates.
camExtrinsics = pose2extr(tagPose);
%%
% Finally, use <docid:vision_ref#bup3vo1-1 |plotCamera|> to visualize the camera
% in 3-D.
hold on
cam = plotCamera(AbsolutePose=camExtrinsics, Size=15, Parent=ax);
%% Add Virtual Content to Video and Visualize Camera Trajectory
% Repeat the steps above on the remaining video frames.
% Create a video player to display video content.
player = vision.VideoPlayer();
% if two outputs are placed vertically, set it true.
isDispVertically = false;
% Create an animated line to display camera trajectory.
camTrajectory = animatedline(ax, ...
camExtrinsics.Translation(1),...
camExtrinsics.Translation(2),...
camExtrinsics.Translation(3),...
Color="blue", ...
LineWidth=2);
videoObj = VideoWriter('renderingDemo', 'Uncompressed AVI');
open(videoObj);
% Loop over remaining video frames.
while hasFrame(reader)
% Read next video frame.
I = readFrame(reader);
% Estimate AprilTag pose.
[~, ~, tagPose] = readAprilTag(I, tagFamily, intrinsics, tagSize);
% Update the tag pose to have z-axis pointing out of the tag.
tagPose = rigidtform3d(tagPose.A*tform.A);
% Project cuboid vertices from the world to image.
projectedVertices = world2img(cuboidVertices, tagPose, intrinsics);
% Insert cuboid into video frame.
augmentedImage = insertShape(I, "projected-cuboid", projectedVertices, ...
Color="green", LineWidth=6);
% augmentedImage = insertMarker(I, projectedVertices, "circle", "Color",pt.Color);
% Display the augmented video frame.
player(augmentedImage)
% Update the camera position in the virtual scene.
camExtrinsics = pose2extr(tagPose);
cam.AbsolutePose = camExtrinsics;
% Update camera trajectory in the virtual scene.
addpoints(camTrajectory, ...
camExtrinsics.Translation(1),...
camExtrinsics.Translation(2),...
camExtrinsics.Translation(3));
f = getframe(gcf);
[h, w, ~] = size(f.cdata);
if isDispVertically==true
augmentedImage = imresize(augmentedImage,[nan, w]);
output = [f.cdata;augmentedImage];
else
augmentedImage = imresize(augmentedImage,[h, nan]);
output = [f.cdata,augmentedImage];
end
writeVideo(videoObj,output);
% Flush the graphics pipeline.
drawnow limitrate
end
% close the video object
close(videoObj);
% delete the video
delete(videoFilename)
参考ページ
MathWorks: Augmented Reality Using AprilTag Markers
ディジタル画像処理
COCOデータセットのダウンロード
1. はじめに
COCOデータセットをダウンロードする際に、ダウンロードリンクから直接ダウンロードできませんでした。
この記事は、wgetを利用したダウンロード方法についての備忘録です。

なお、CocoはGoogle Cloud Platform (GCP)に格納されており、gsutil ツールを利用してダウンロードすることが推奨されています。
2. Wgetを利用したCocoデータセットのダウンロード
ここでは、Windowsを利用します。
1. Wgetをインストールする
インストール方法については、以下のページがわかりやすかったです。
2. コマンドプロンプトにて以下のコマンドを実行する
なお、私は1でWgetのパスは通さず、直接
cd "C:\Program Files (x86)\GnuWin32\bin"
にてパスを移動しました。
wgetの -P オプションで保存先を指定することができます。
以下のコマンドで訓練データやアノテーションデータをダウンロードすることができます。
wget -P D:\ScanX\tools wget http://images.cocodataset.org/zips/train2017.zip
wget -P D:\ScanX\tools http://images.cocodataset.org/annotations/annotations_trainval2017.zip
ダウンロードが完了すると、指定したとおり、D:\ScanX\toolsにデータがダウンロードできました。

NeRFの仕組みを1からわかりやすくまとめたい
1. はじめに
NeRF (Neural Radiance Field) とは、複雑なシーンに対して、任意の視点からの3次元的なシーンを画像から再構成する技術です。以下の動画にあるように、物体に対して、様々な角度から見たときのシーンをキレイに再現することができます。反射に関しても、それぞれの角度から見たときの見え方が反映されており、角度によって同じ場所でも微妙に違う反射特性を見て取ることができます。この手法を利用して、例えば、地点AとBで画像を取得した場合、その中間地点の任意の角度から対象物体を見たときのシーンを生成可能です。
この記事では、このNeRFと呼ばれる技術と、それを実行するにあたって必要な周辺の技術について簡単にまとめたいと思います。以下に示す、NeRFの論文と照らし合わせてながら解説を行います。しかし、本記事では、NeRFを実行するまでの流れを示すため、各要素技術に関しては詳しく述べていません。それぞれに対して文献を調べやすくするように、主要な専門用語に関しては、英語の表記も併記するようにしています。
間違いやわかりにくい点があれば更新していきたいので、ぜひご意見などいただけますと幸いです。

Project Page www.matthewtancik.com
arxiv上のNeRFの論文
なお、本記事で利用したコードの一部や画像は以下のレポジトリにアップロードしています。何かの役に立てば幸いです。
また、本記事の内容をスライドにまとめたものは以下の通りです。
2. NeRFを実行するには
NeRFがどのような技術であるかを知るためには、自分で体験するとよいと思います。NeRFを自分で実行するためには、いくつか方法があります。ここではその例を挙げます。
2.1 LumaAI
lumaAIというiOSのアプリを利用して、NeRFを実行するのが簡単です。以下のページから、iPhoneやiPadにインストールすることができます。

自分でその場で対象物を撮影したり、すでに対象物を撮影済みの動画をアップロードすることもできます。
例えば、以下はひまわり畑をLumaAIにて処理した結果です。様々な視点からひまわりを見て取ることができます。GIFのファイルサイズの制限のため、少し粗い図になっています。

また、PCから、動画をアップロードすることもできます。PCでは同時に複数の動画を処理することもでき、それぞれでメリットがあります。うまく使い分けるとよいと思います。
2.2 NeRF studio
NeRF studioを利用することで、コードベースでNeRFを利用することができます。LinuxやWindowsにインストールすることができます。環境構築が大変そうであれば、Google Colabを利用することもできます。Docker環境も利用可能で、いろいろと試す方法があります。
2.3 各アルゴリズムのページのコードを実行する
NeRFやその派生形のアルゴリズムも多数あり、それぞれのコードがアップロードされているページ(例: github)にアクセスし、そこでコードをダウンロードすることも可能です。以下は、NeRFのコードが格納されいるgithubのページです。
3. 用語について
この章では、本記事でよく出てくる単語と、類似する単語の関係性について述べます。表記のゆれなどございましたら教えていただけますと幸いです。
訓練 (training):
NeRFではニューラルネットワークの学習が必要です。訓練の他に、学習や、トレーニングといった言葉がありますが、訓練で統一します。
ニューラルネットワーク (Neural Netork: NN):
ニューラルネットワークの他に、NeRFにおいてはニューラルネットワークを多層パーセプトロン(Multi-Layer Perceptron: MLP)と表現することもできます。また、利用するニューラルネットワークの層を深くした場合は、深層学習ネットワークとも表現できます。しかし、ここではそれらをニューラルネットワークにて統一します。
推論 (inference):
テストと同様の意味で使用します。本記事ではテストという用語は使用せず、推論という表記に統一します。例えば、NeRFのネットワークを学習して、新規の視点からの色情報や密度情報を得たい場合に、”推論する”と表現します。
Structure-from-Motion (SfM):
本記事では、対象を複数の視点から画像撮影し、その撮影した時のカメラの位置と向きを求めるために、SfMを利用します。SfMを利用することで、対象の3次元点群を得ることができますが、ここで得られる点群は扱いません。
なお、SfM (Structure from Motion) の意味合いについて、織田らの論文では以下のように述べられています。
移動(Motion)するカメラから得られる画像から形状を復元するのが SfM(Shape from Motion)である。Structure from Motion(SfM)は Shape from Motionの別名である。ただし,Structure from Motionというと,画像に映った対象物の幾何学形状とカメラの動きを同時に復元する手法という意味合いが強くなる
https://www.jstage.jst.go.jp/article/jsprs/55/3/55_206/_pdf
主にロボットビジョンにて利用される、周囲の3次元構造と自己位置や向きを同時に推定する技術である SLAM(Simultaneous Localization and Mapping)や、画像を用いて同様のことを行う、Visual SLAM も関連した用語として存在します。しかし、SLAMは(後処理のループとじ込みなどもあるが)リアルタイムに計算を行うことが多く、後処理的に行うSfMとはニュアンスが異なります。
モデル:
主に3次元モデルの意味で利用します。しかし、NeRF中で、ニューラルネットワークが利用されており、そのネットワークのことをモデルと表現することもできます。この場合は、NeRFのモデルといったような表記をして、3次元モデルと混同しないように心がけています。
4. NeRFの技術的な概要
この章では、NeRFの概要を説明します。あくまで、NeRFのアルゴリズムが行う内容であり、画像から任意の視点のシーンを得るためには、SfMなどのその他のアルゴリズムも必要になります。
NeRFの入力は任意の方向の光線と対象とするその光線上の点の座標です。そして、NeRFのアルゴリズムにそれらを取得すると、その任意の点の色とその密度が返されます。もし、その指定した点に何もなく、何もない空間(点)を指定した場合は、その密度は0に近づきます。一方で、その指定した点が対象の物体の表面にあると、その密度は1に近づきます(密度を0から1に正規化してアルゴリズムを設計した場合)。

画像出典: https://www.youtube.com/watch?v=JuH79E8rdKc&t=15s
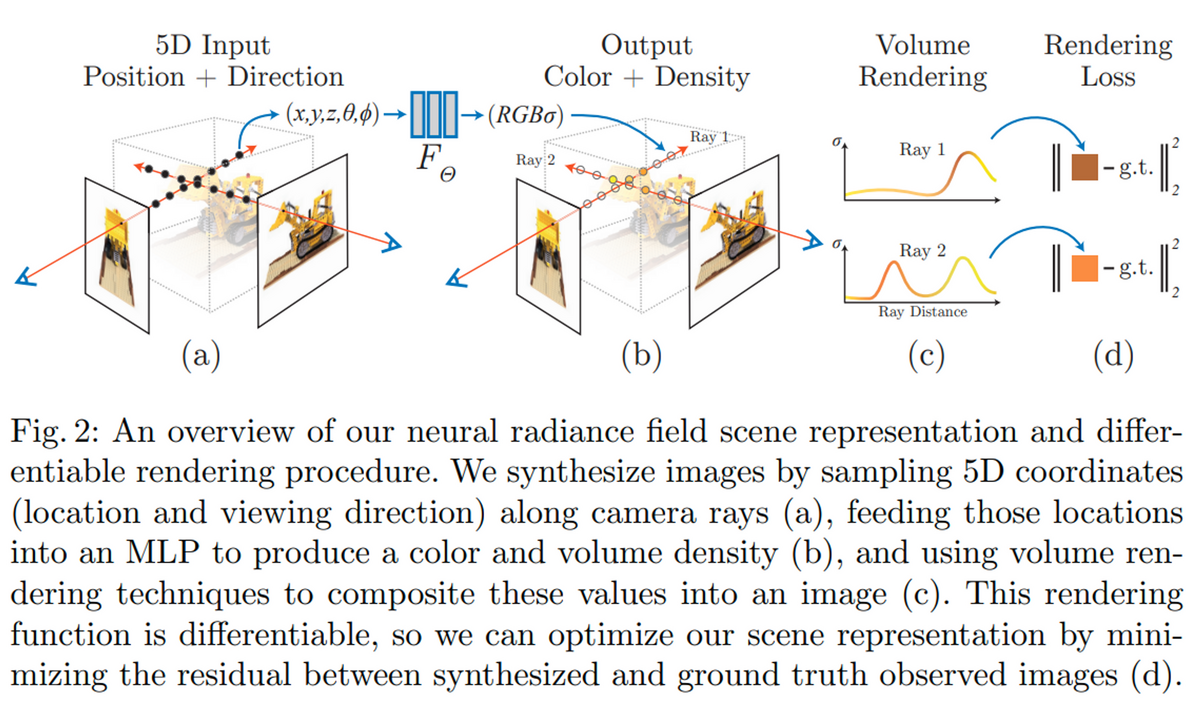
以下の図はNeRFの論文のFig.2です。キャプションにground truthと記載があるので、推論ではなく、訓練の過程であると思われます。(a)はカメラにて対象物を異なる角度から撮影し、ある点が2つのカメラの画像平面 (image plane)に到達しているときの様子です。訓練においては、各画像の中からランダムに画素を抽出し、その画素やその画素に到達する光線を利用します。(a)には2つの光線が描かれており、それぞれで7つの黒い点が描かれています。学習の過程では、この7つ(実際はもっと多い)の点に対して推論を行います。ここでは、訓練の過程におけるforwardの計算を推論と呼んでいます。そして、その推論の結果が(b)にあります。
さきほどの7つの点それぞれに対して、色と密度(存在の強さ度合い)が返されます。例えば、各光線のカメラ平面側の点には、対象のブルドーザーはなく、ただの透明な空間であるように見えます。その場合は、物体としての色は存在しないため、密度σは0に近い値が返されるはずです。一方、(b)の左側の画像に到達している光線で、カメラ側から数えて3、4つ目あたりでは、ブルドーザーの点がちょうど存在しているように見えます。この場合の密度は1に近い値になり、かつ色情報は黄色に近い値になるはずです。このように、カメラ側から光線をたどっていくと、その空間上(に点があった場合を想定した時)の点の色と密度があり、それをカメラ側から足し合わせていくとそのカメラの視点から見たときの色になるはずです。
(c)では、その7つの点の密度σを縦軸、カメラからの距離を横軸にして、かつ、その時の色を曲線の色で表しています。左側のカメラから伸びる光線1 (Ray1) では、上記の計算を行った結果茶色っぽい色になったとします。
(d)ではその光線上をたどった時の色と、実際のカメラの画素の色を比べています。差分が小さいほど、その推論は正しいことを意味します。今回は、図の面積の都合上、2つの光線に対して行っていますが、訓練の際は、画像から光線をランダムにサンプリングして(例 4096本)、それぞれらの光線に対する計算を行います。このような誤差(損失: Loss)を2乗誤差で定義し、その損失が最小化するように学習を行います。損失関数 (Loss Function) に現れる値は色のみです。完璧に何らかの形で訓練データ中の対象の周辺の3次元情報が得られると、密度情報の正確な値が得られるかもしれません。しかし、実際にそれらの値を計測することは困難で、密度の真値 (ground truth)を得ることは行いません。しかし、上記の色情報の損失関数を計算する過程では、密度σの値も含まれており、この色情報の損失が最小化されれば、うまく密度も学習できるはずです。
以下の図はNeRFの論文のFig.3です。見る角度に応じて見え方が実際のように異なって見える (view-dependent) ことを示しています。日常生活においても、同じ物体の同じ場所を見ていても、光の当たり具合などで光沢や、つやが異なって見えることがほとんどだと思います。レーザースキャナなどで対象の3次元モデルを作成しても、その座標に対する色情報が与えられるだけで、見る角度によってどう見え方が変わるか、ということはわかりません。一方で、NeRFでは任意の視点からのシーンを再現できます。
(a)と(b)で、2つの視点から見たときの様子を示しています。それぞれで2つの地点をピックアップしています。一つ目が船の左側のオレンジのところ、二つ目が海の上の青っぽいところです。
図(a)と(b)では、その反射具合をうまく反映して、それぞれ色が異なった形で表現されています。
(c)はいろいろな角度から(対象を網羅する半球状の任意の視点から)見たときにどのような色として見えるかを示しています。色がちょっとずつ変わっていて、別の言い方をすると、視点ごとに色が連続的に変化していることがわかります。一部例外を除いて、基本的には物体を異なる角度から見たときに色は徐々に変わるものだと思います。うまくNeRFのモデル(厳密には、NeRFにて定義するニューラルネットワーク)がうまく学習されていて、連続的にview-dependentな情報を返していることがわかります。
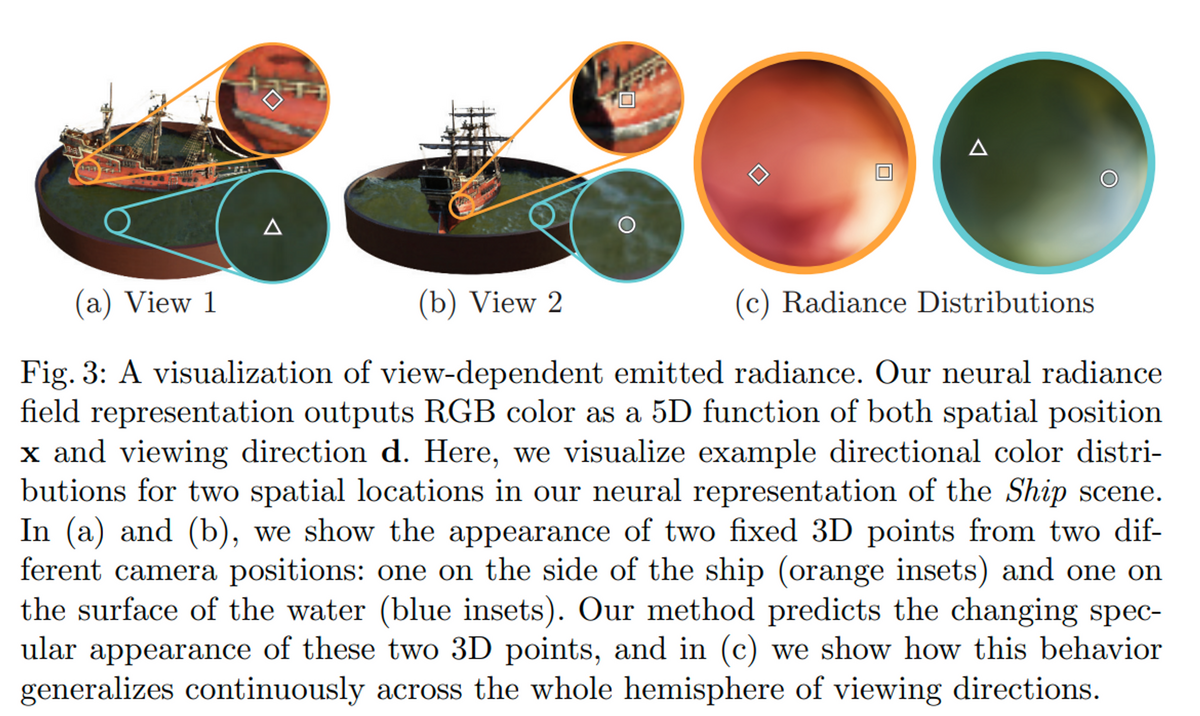
5. 大まかな手順
この章では、NeRFを実行するにあたって必要な前準備や、NeRFの処理についての大まかな手順を示します。次の章以降で、それぞれについて、より詳しく説明します。しかしより詳しく、かつ厳密な解説は、最後の Self-QAの章などで紹介している参考文献をご覧ください。
- カメラキャリブレーションを行い、焦点距離やレンズのゆがみの情報などの内部パラメータがわかっているカメラを用意する
- 周辺をカメラで撮影し、SfM (Structure from Motion) などの技術を利用して、各画像を撮影したそれぞれに対するカメラの自己位置と向きを推定する
- NeRFで利用するニューラルネットワークの訓練を行う
- 取得したデータ画像すべてを利用して訓練する
- ニューラルネットワークの訓練のために、画像から複数の画素(例: 4096)をピックアップする
- そのピックアップしたそれぞれの画素の光線の向きを考え、その仮想的な光線上の複数の点を得る(例: 64点)
- その光線上の複数の点(例: 64点)に対して色情報と密度(存在度合い)を求める
- その光線にそって、密度を加味しながら色を足し合わせていき、その光線がそのカメラから発せられた場合、その画素ではどのような色になるかを計算する(実際は、cからeの作業を2段階に行う)
- 実際のカメラ画像のその画素の色情報を取り出し、eで計算した値との差分(2乗誤差: Square Error)を計算する
- cからfのステップを繰り返し、訓練の1つのステップ(ミニバッチ: Mini Batch)とする
- gで得たミニバッチに対する誤差を最小化するために逆誤差伝搬法 (Backpropagation)にて重みやバイアスなどの最適化を行う
- 設定した回数だけ学習を行い、NeRFのためのニューラルネットワークを計算する
- 推論: 3で学習した、NeRFのネットワークを使用して任意の視点にてシーンの生成を行う
- カメラの内部パラメータを設定したうえで、新たなシーンを生成するための仮想的なカメラの位置と向きを設定する
- 焦点距離などの(仮想的な)カメラの内部パラメータを利用して、各カメラの画素とカメラ中心を結ぶ光線を生成する
- bの光線上で、複数の点を得る(例: 64点)
- cそれぞれの光線が任意の座標の点(または空隙)に当たった時にどのような色をしているか予測し、密度情報と合わせてその光線上から見たときの色情報を計算する
- bからdの操作を繰り返して、仮想的なカメラの画素全てに対して光線と、その光線上での点を得る。これにより任意の1枚の視点に対する1つの画像(のようなもの)が生成できる
- bからeを繰り返し、新たなシーンを生成するための(仮想的な)カメラすべてに対して同様の処理を行う
- 任意の視点でのシーンが生成される
以上の操作によって、NeRFによる任意の視点でのシーン生成が実行できます。次の章からはそれぞれの処理に関して説明を行います。
6. カメラの位置と向きの計算: Structure-from-Motion
カメラにて、対象物の画像を撮影したのちに、それぞれのカメラの位置と向き(外部パラメータ)を求める必要があります。以下の図を見てください。下部のグレーの平面が対象とする物体とします。これを撮影したカメラの位置と向きが可視化されています。たくさんのカメラがそれぞれ異なる位置と向きを有していることがわかります。NeRFを実行するためには、これらの情報をあらかじめ、求めておく必要があります。この章ではその計算方法について簡単に説明します。

本章の執筆にあたり、以下の書籍が参考になりました。
ディジタル画像処理 [改訂第二版] Kindle版
Amazon.co.jp: ディジタル画像処理 [改訂第二版] eBook : ディジタル画像処理編集委員会: 本
6.1 カメラの内部パラメータについて
本記事では、あらかじめカメラの内部パラメータがわかっていることを想定します。そのため、5.1で説明したカメラの内部パラメータの計算のための実験を事前に行っておく必要があります。カメラの内部パラメーターには、焦点距離、光学的中心、およびせん断係数が含まれます。これらのカメラの内部パラメーターは以下の行列で表すことができます。
fは焦点距離、cは光学的中心、sはせん断の係数を示します。
これらの計算は、以下の画像のように、チェッカーボードを様々な角度から撮影し、その白黒のパターンを自動的に認識することで行うことができます。以下の図はMATLABのカメラキャリブレーションのアプリでカメラキャリブレーションを行っているときの様子です。
自動的にチェッカーボードの角を検出し、さらに内部パラメータや外部パラメータを求めたのち、各点を再投影したときの誤差を計算しています。この誤差が小さいほど、カメラの内部パラメータや外部パラメータが正しく推定されており、質のよいカメラキャリブレーションが行えていると考えられます。
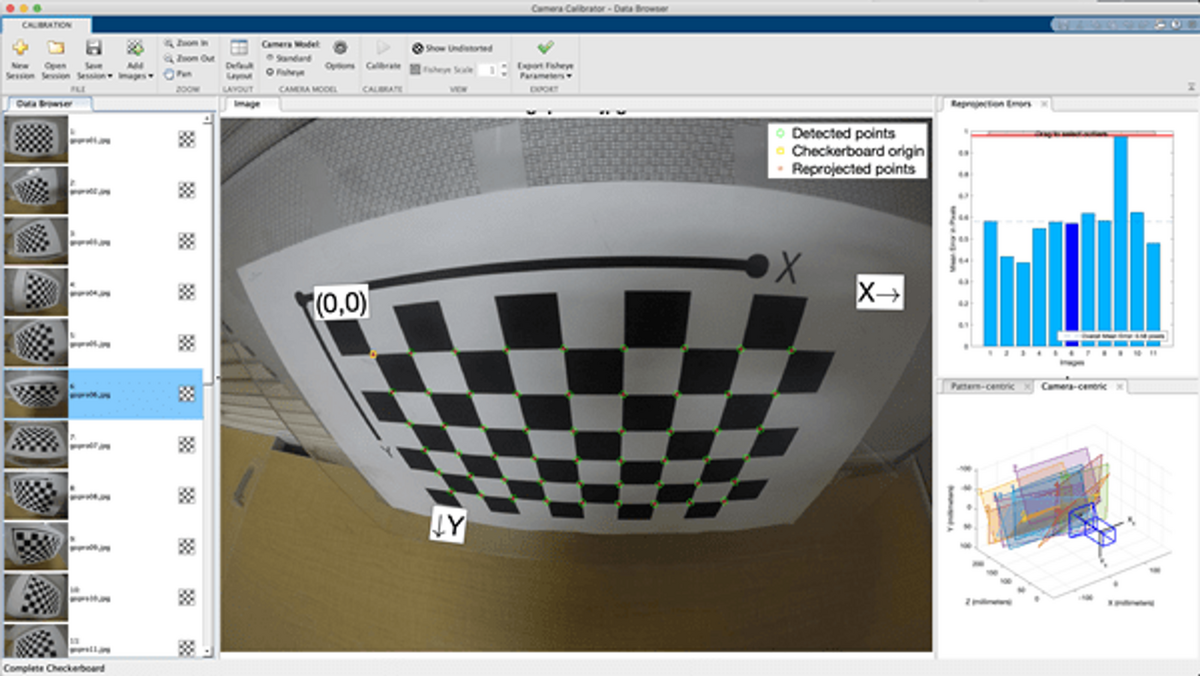
カメラの内部パラメータや外部パラメータに関しては、以下のページがわかりやすかったです。
実際にチェッカーボードの角の自動検出からどのようにパラメータの計算を行っているかは本記事では割愛します。ここで説明した、チェッカーボードを利用したカメラキャリブレーションについては、以下の論文にて提案されています。
2023年8月で、引用数約2万と非常に広く活用されています。
Zhang, Zhengyou. "A flexible new technique for camera calibration." IEEE Transactions on pattern analysis and machine intelligence 22.11 (2000): 1330-1334.
https://ieeexplore.ieee.org/document/888718
以下は、MATLABにてチェッカーボードのコーナーを自動的に検出しているときの例です。画像のタイトルにあるように、自動的に8×11個の白黒のパターンが読み取れていることがわかります。

clear;clc;close all % Read an image containing a checkerboard pattern. I = imread('./img/checkerBoard.jpg'); % Detect the checkerboard points. [imagePoints,boardSize] = detectCheckerboardPoints(I); % Display detected points. J = insertText(I,imagePoints,1:size(imagePoints,1)); J = insertMarker(J,imagePoints,'o','Color','red','Size',5); imshow(J);title(sprintf('Detected a %d x %d Checkerboard',boardSize));
6.2 カメラ座標系とワールド座標系
ここで、カメラ座標系 (Camera Coordinate System) とワールド座標系 (World Coordinate System) について説明します。以下の図のように、カメラの光学中心を原点とし、Z軸をカメラの光軸中心に一致させたものをカメラ座標系とします。一方で、カメラによって撮影される、適当な位置にあるそれぞれの点の座標系をワールド座標系といいます。

画像出典: ディジタル画像処理 Kindle版 14章
カメラ座標系での座標と、ワールド座標系での座標は、以下のように表されます。回転行列と平行移動のベクトルで、互いに変換することができます。
6.3 画像同士のマッチングについて
対象物を複数の角度から撮影をした後に、それぞれのカメラの位置と向きを求めることを目標としていました。そのためには、それぞれの画像をうまくつなぎ合わせる必要があります。例えば、ある物体を撮影し、少し横にずれた状態で再び画像を取得したとします。それらの画像を撮影したカメラの位置関係を求めるためには、画像中の物体から共通した部分を見つけて、対応付けることが重要です。
例えば、以下の画像を見て下さい。異なる角度から同じコップを撮影しています。また、赤色の矢印で示される箇所がそれぞれ対応した、同一の部分であることがわかります。このような対応点を目印にすると、これらのカメラの位置に関しては、右側の画像は、少しコップの右側に回り、上から下に向かって撮影したと考えられます。感覚的には、カメラの相対的な位置を予想することはできましたが、画像を解析し、自動的に行うにはどのようにすればよいでしょうか。

上の例で2つ目の画像を取得した時のカメラの位置や向きを予測するために、コップの絵柄などの、特徴的な個所を目印に、それぞれの対応関係を求め、その対応関係から、カメラの位置を類推しました。これらのことから、画像のペアから自動的に、その画像取得をした際のカメラの位置や向きを知るためには、第一に、それらの画像間で、共通して映っている、特徴的な点のペアを知ることが重要そうです。
それでは、画像の中の特徴的な点を自動的に抽出してみようと思います。以下の画像を見て下さい。パンケーキの画像の中で、特徴的な点を100点可視化しています。
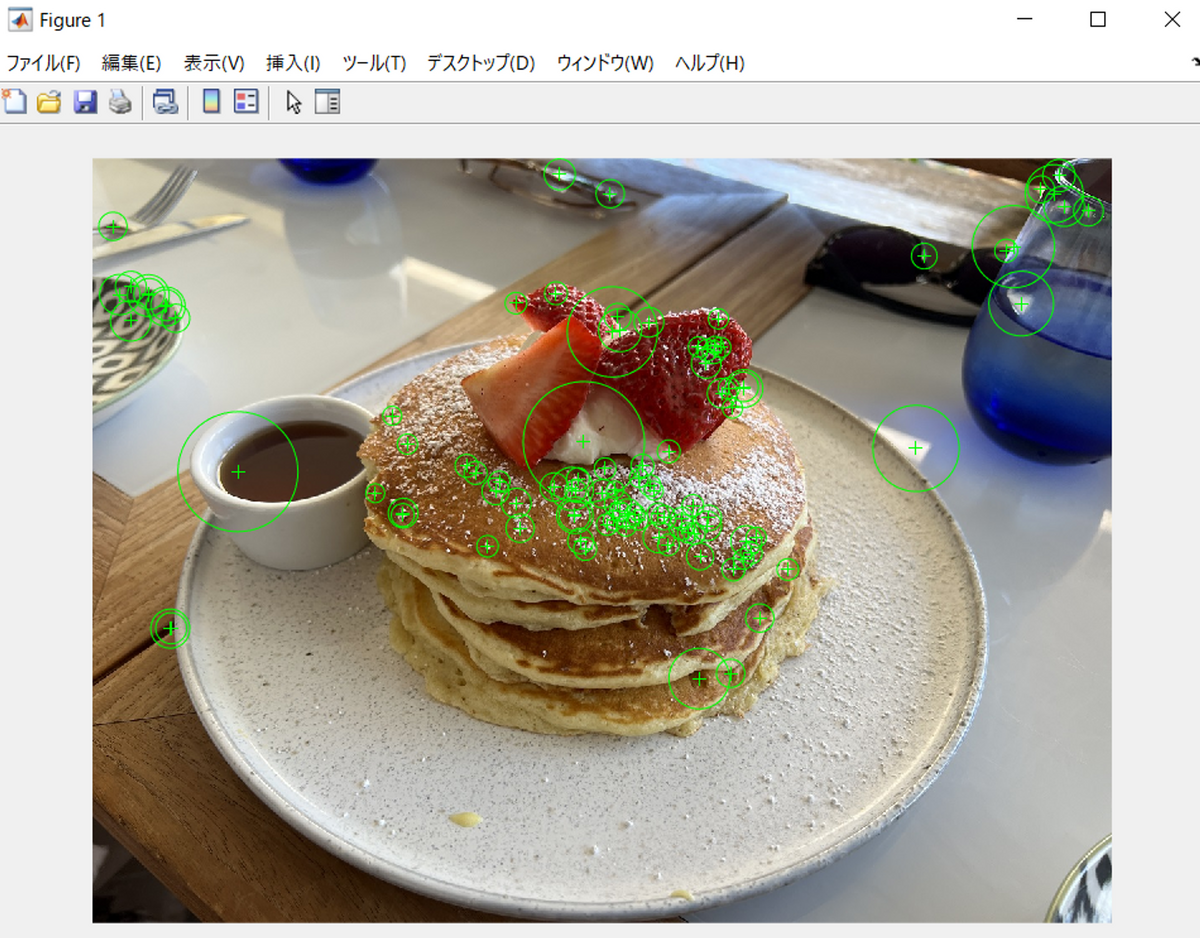
以下はこの画像を表示するためのMATLABコードです。
clear;clc;close all % Read in image. I = imread('./img/pancake.jpg'); I_gray = im2gray(I); % Detect SURF features. points = detectSURFFeatures(I_gray); % Display location and scale for the 10 strongest points. strongest = points.selectStrongest(100); imshow(I); hold on; plot(strongest);
近傍のピクセルとの輝度値の違いなどを利用して特徴的な点を(特徴点)を定義しています。この特徴的な点の定義は複数考えられます。どのような点を特徴的とするのかによって、特徴点の抽出の結果も変動します。また、特徴点を数学的にどのように定義するかということも考える必要があります。例えば、ここで利用したSURF特徴量は、以下のように、各点(ピクセル)に対する特徴量を64次元のベクトルにて表現します。2571個の特徴的な点がこの画像では発見されたことを意味しています。

SURF特徴量以外にも、いろいろと種類があります。SHIFTなども有名です。コーナー(角)の検出に強いものや、スケールが変わっても対応付けができるものなどあり、対象の画像や撮影方法に応じて使い分けする必要があります。さらに、物体の角のように特徴的であるか、または、真っ白で周辺に物体もなく、特に特徴的とはいえない、ということに関しても程度があります。その程度をどこで線引きをして、特徴点であると認識するか、という閾値の設定も必要です。
以下に、よく利用される特徴量(記述子)の種類と、それらの違いについての表を示します。それぞれの種類に対して、特徴点抽出のための閾値を設定可能です。詳しい内容については以下のリンクをご覧ください。
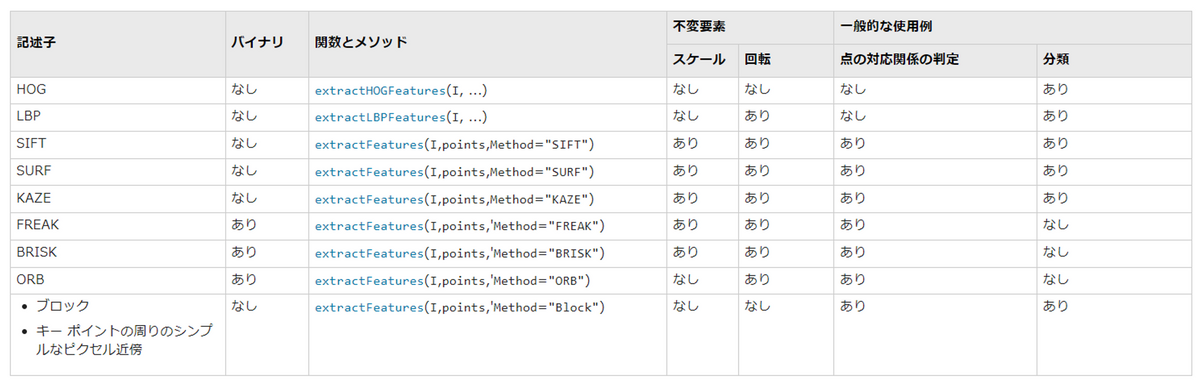
それでは、SURFやSHIFTを利用して、特徴量が定義でき、その中で顕著なものを複数、特徴点として採用したとします。それでは、2つの画像間の特徴点の対応付けはどのようにすればよいでしょうか。
以下の図で、画像I1の中央部に特徴点のx1があります。右図は、別の角度から同一の対象を撮影した時の画像です。右図には5つの特徴点が設置されています。感覚的には、y2がx1と同一であると思われます。しかし、これを自動的に判定するにはどうするとよいでしょうか。
上のSURF特徴量の例では64次元のベクトルで表現されていました。左図のx1に対応する点を探したい場合、右図の5つの特徴点に対する特徴量とのベクトルの差分を求めます。
そして、そのベクトルの差分(のユークリッドノルムなど)をdistとします。以下の図では、それぞれ5つのdistを求めています。35, 12, 58, 62, 87 と計算されていることがわかります。最も近しい、つまりdistが小さいものは12であり、ちょうど右図でも対象物の中央部の点になっています。つまり、特徴量の差分を計算し、その中で最も近いものを探すことで、対応している点を探索できそうであることがわかりました。
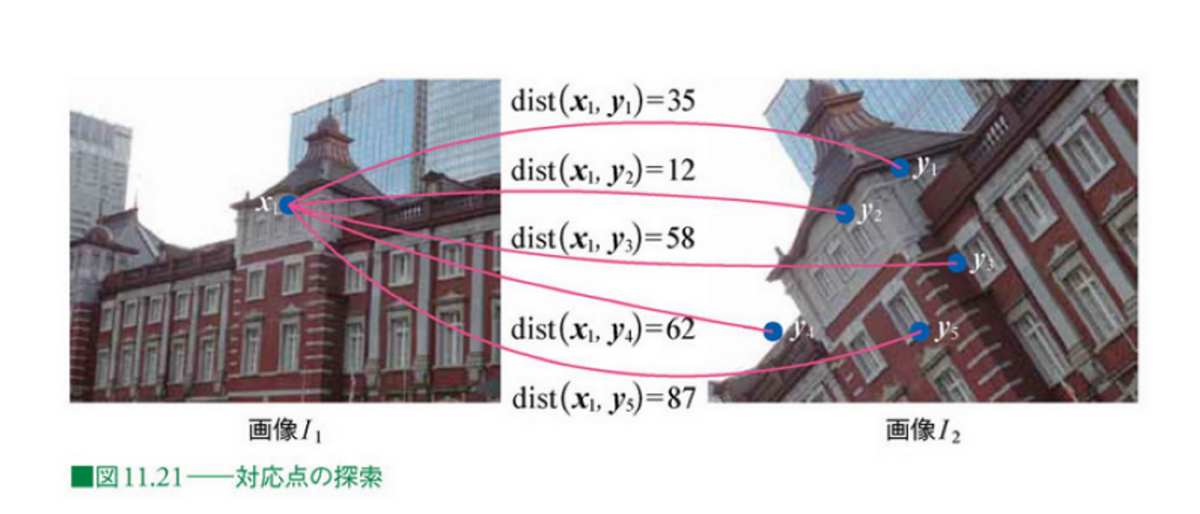
画像出典: ディジタル画像処理 Kindle版 11章
しかし、単に特徴量の差分だけを見ると、繰り返し似たパターンがあった場合や、ノイズがある場合は、正しく特徴点同士をマッチングすることができません。 例えば、以下の2つの画像は、同一のシーンをそれぞれ別の角度から撮影しています。

SURF特徴量を計算して、特徴点を算出し、それぞれの対応関係を可視化しました。おおよそ、うまく対応付けられていますが、クッキーの箱の上部と本のNの右側の部分などが誤ってマッチングしてしまっていることがわかります。この結果をもとに各カメラの位置や向きを推定すると、精度が低下することが考えられます。

なお、こちらの特徴量の計算やマッチング、可視化のためのMATLABコードは以下の通りです。
clear;clc;close all addpath('img\') I1 = imread("left.jpg"); I2 = imread("right.jpg"); figure;imshowpair(I1,I2,'montage') I1_gray = im2gray(I1); I2_gray = im2gray(I2); % Find the corners. points1 = detectSURFFeatures(I1_gray); points2 = detectSURFFeatures(I2_gray); % Extract the neighborhood features. [features1,valid_points1] = extractFeatures(I1_gray,points1); [features2,valid_points2] = extractFeatures(I2_gray,points2); % Match the features. indexPairs = matchFeatures(features1,features2,"MaxRatio",0.4,'Unique',true); % Retrieve the locations of the corresponding points for each image. matchedPoints1 = valid_points1(indexPairs(:,1),:); matchedPoints2 = valid_points2(indexPairs(:,2),:); % Visualize the corresponding points. You can see the effect of translation between the two images despite several erroneous matches. figure; showMatchedFeatures(I1,I2,matchedPoints1,matchedPoints2);
そのような誤ったマッチングを防ぐために、RANSAC (RANdom SAmple Consensus) と呼ばれる方法を用います(実際は上のデモでもRANSACを利用しているのですが、マッチングのミスが起こる様子を再現するために上のコードを利用しています)。ここでは、4点などの少数のマッチングした点をランダムに選択します。そして、そこで得られた点をもとに、変換式を求めて、再度投影を行います。その時の投影誤差を最小にするパラメータを最終的な結果とします。またどのように変換するかについては、次の節で説明します。
RANSACは、ロバスト推定のアルゴリズムの1つで、様々な用途に適用することができます。そのため、このような画像間のマッチングだけでなく、例えば、3次元点群からの地表面抽出に利用した例もあります。
また、以下の例では、3次元点群から、トンネルの中心点を求めています。
佐藤工業さま: トンネル計測管理における RANSAC 法の適用
http://library.jsce.or.jp/jsce/open/00035/2016/71-06/71-06-0931.pdf
RANSACの仕組みについては、以下のページなどがわかりやすかったです。
6.4 カメラの外部パラメータの推定について
6.3で述べたように2つの画像間で、複数の特徴点のペアが求まったとします。1つのカメラの位置を基準とし、それをワールド座標系とみなすことで、2つのカメラの位置と特徴点の位置の関係を9つの未知数をもって紐づけることができます。9つとは、もう片方のカメラの位置の6自由度と、特徴点のXYZ情報の3自由度のことです。6.2で述べたように、1つの固定されたカメラに対して、もう1つのカメラの相対的な位置は、回転行列と並行移動のベクトルで表すことができました。回転に関してはXYZ軸それぞれに対して、3つとXYZ軸にそれぞれ平行に移動するときの移動量の3つ分で、合計6つです。また特徴点はそのままXYZ座標の3つの未知数を求める必要があります。
再度、ディジタル画像処理14章にある式を掲載します。
...(ディジタル画像処理14.2)
...(ディジタル画像処理14.3)
2つのカメラと1つのマッチングした特徴量を結んだ図は以下の通りです。
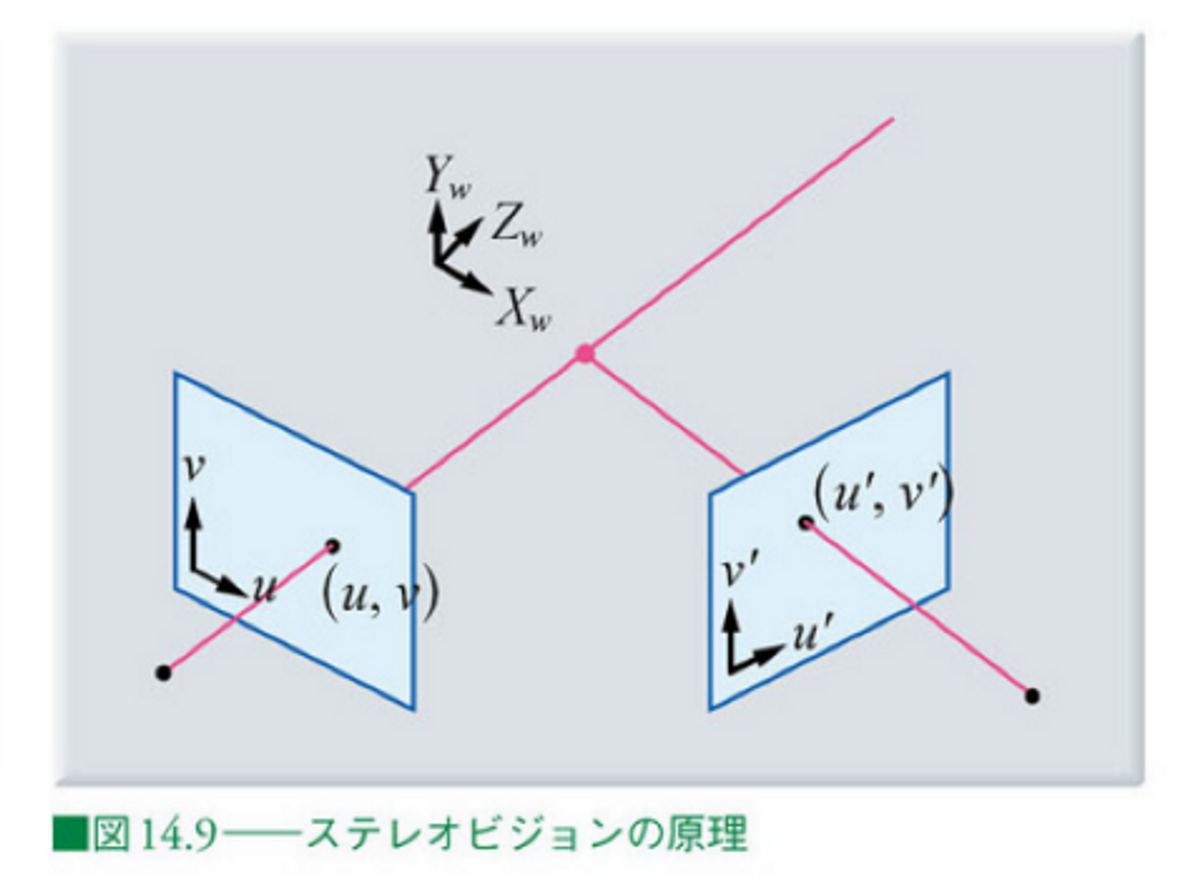
詳細は置いておいて、例えば、以下の式のようなイメージで、この幾何的に定まった関係を2つの式で表すことができます。これは、あるワールド座標系の点(上の画像ではピンク色の交点)と、カメラの投影点(上の画像ではu, vであらわされる)の関係式です。1つのカメラに対して、2つの式が得られます。これらの流れの詳細については、デジタル画像処理の14章をご参照ください。

上では、9つの未知数があると述べました。厳密には、スケールが不定なので、変数の数は8つになります。以下の図を見てください。こちらはカメラでイヤホンケースを撮影した時の様子です。カメラのレンズの周縁でのゆがみなどは考えないとすると、以下のように対象を撮影したとしても、それより等倍の大きなイヤホンケースがあったとして、それを撮影した場合もほぼ同じ画像が得られます。つまり、画像単体では、対象のスケール感を一意に定めることができません。

先述したように、14-5の式を利用して、1つのカメラに対して2つの方程式を得ることができるのでした。今はカメラが2つあるので、1つの特徴点のマッチングに対して、合計4つの方程式を得ることができます。
しかし、いま、変数が8つあるので、これだけではカメラの位置と向きを特定することができません。そこで、もう少しマッチングした特徴点の数を増やしてみることにします。さきほどは、1組の対応点のみを想定しましたが、M組の対応点のペアがあったとします。
カメラの位置と向きは変わらないため、対応点のワールド座標のXYZの3つが未知数として増加します。つまりM個のマッチングした対応点があるとすると、3M+5個の未知数があります。一方、1組の対応点に対して、合計4つの方程式を得ることができることをさきほど説明しました。そのため、M個の対応点のペアがあると、4M個の方程式を得ることができます。
これらをまとめると、
対応点がM個あった場合 未知数: 3M+5 方程式の数: 4M
方程式の数が未知数の数を上回るとカメラの位置と向きが求まるとよいので、
3M+5≦4M つまり、M≧5のとき、未知数を求めることが可能になります。 そのため、5つの対応点があればカメラや対応点の計算が最低限、できると考えられ、この解き方のことを5点アルゴリズム (five-point algorithm) と呼びます。
しかし、実際はこれだけの対応点では簡単に解くことができず、より多くの対応点のもとで、異なる解き方をすることが多いです(例: 8点アルゴリズム: eight-point algorithm)。しかし、本記事では、NeRFの仕組みを説明することを目的とするため、より詳しい解法については割愛いたします。
また、カメラの位置と向きが定まれば、以下の画像中の2つの光線の交点(XYZ)を幾何的に求めることができます。これにより、対応点のXYZ座標もわかるため、対象の3次元座標も求めることができます。しかし、このNeRFにおいてはその対応点のXYZ座標は直接的には利用しません。 本節で述べたように、2枚の画像を用いて、まずは、それらの位置と向きを定めることができました。さらに、画像を追加し、同様の処理を進めることで、複数枚の画像から、それぞれのカメラの位置と向きを順番に求めることができると考えられます。さらに、対応点のXYZ座標を計算し、疎な3次元点群を構成することができる。ここでは、対応点の数しかXYZの点を得ることができないため、疎な点群と表現している。さらに、順次求めた位置関係をもう一度全体をみて最適化させていく(バンドル調整: Bundle Adjustment)ことをすることで、カメラの位置と向きを最終決定することができます。
ここで得た複数のカメラの位置と向きの以下の図に示します。同一の対象を様々な角度から撮影していることがわかります。

論文中では、以下の、COLMAPを利用してカメラの位置と向きを求めています。Pythonなどで環境構築をし、コマンドラインで実行するのは大変そうですが、コマンドライン意外にもアプリのような形で画面操作でCOLMAPを利用することもできます。
以下のページに、GUIベースでCOLMAPを試す方法が紹介されています。
バンドル調整を実行してみたり、調整可能なパラメーターなどを確認したい場合は、以下のドキュメントがわかりやすいと思います。
補足ですが、SfMでは、対応点で作成した、疎な (sparse) 3次元点群が得られます。これを高密度 (dense) にする処理が、多眼ステレオ(Mulitiple View Stereo: MVS)です。下図のように、カメラの位置と向きが決まると、点Aが画像Aのどこに投影されるかは、画像Aのオレンジ色の線上に限られます。この線のことをエピポーラ線 (epipolar line) と呼びます。これにより、基準画像に映る点Bが、画像A上ではどこの位置にあるかを探索しやすくなります。また、以下の図のように、点Aは他の画像中にも映っている可能性があります。各画像で色情報などの差異が十分小さい場合、これらの点の一致が確認され、3次元上の点として再構成することができます。このような処理を繰り返せば、SfMの過程で同定した対応点に加え、より多くの点で3次元点群を生成できます。しかし、各点の一致を評価する信頼度や、一致していそうな点の候補を探すことが重要になります。
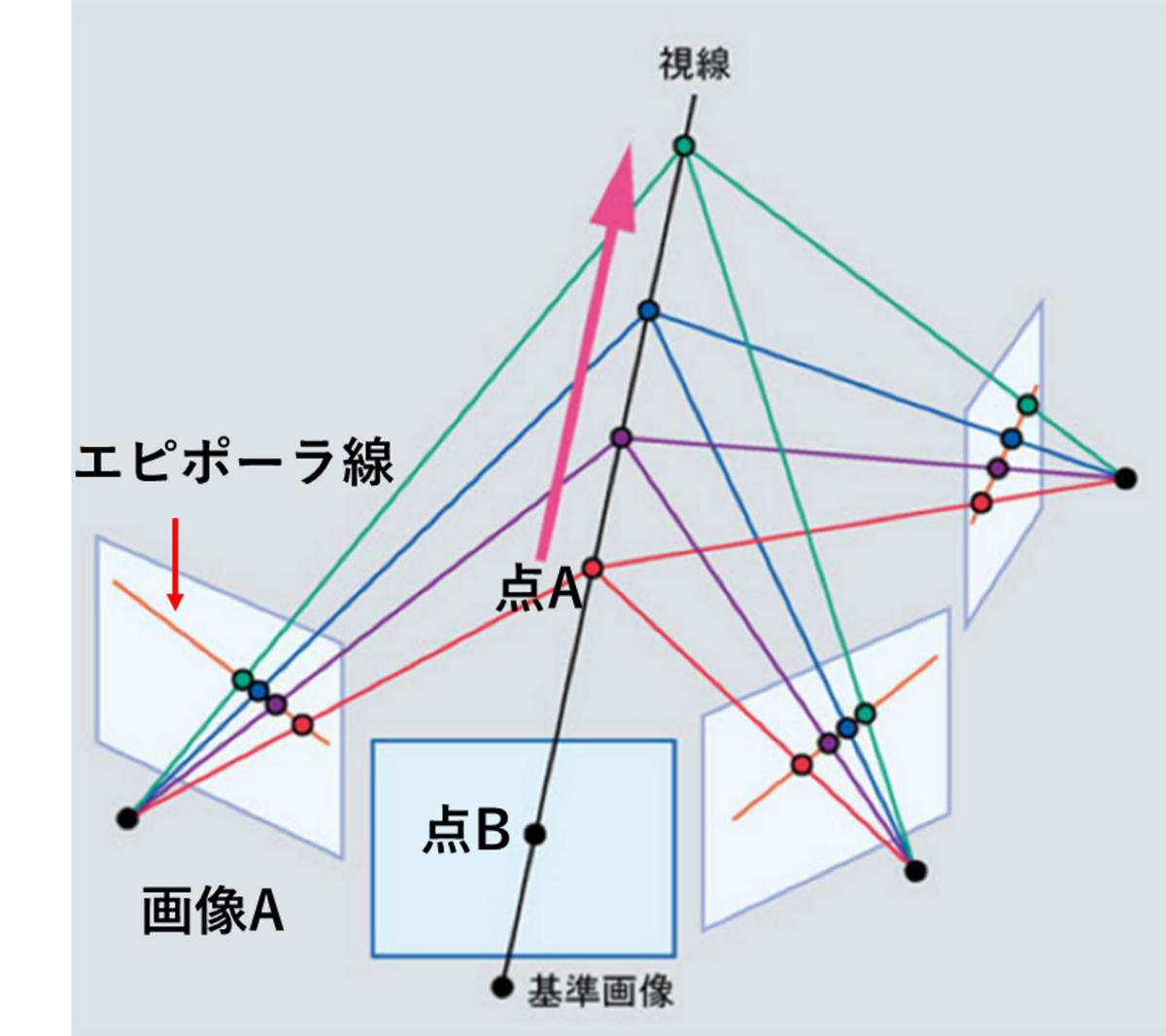
画像出典: ディジタル画像処理 Kindle版 14.17 をもとに作成
6.5 AprilTagを利用した、カメラの内部パラメータと外部パラメータの同時推定
本章では、対象物やその背景の特徴点を利用して、対応点をもとめ、それらをもとにカメラの位置や向きなどを求めていました。しかし、特徴点が十分にない場合はカメラの位置や向きが定まらないことや、画像の入力だけではスケールが一意に定まらないという課題があります。
以下の動画は、AprilTagを利用して、対象の動画を撮影した時の様子です。さらに、このAprilTagの各コードも同時に認識しています。動画フレームに対して、一貫して各コードは同じ色で認識されていることがわかります。また、このコードの位置関係などを利用して、カメラの内部パラメータと外部パラメータを同時に計算することができます。さらに、この各コードは正方形であり、この1辺の長さ(例: 2cm)を入力することで、ワールド座標系での実際の長さを知ることもできます。しかし、この場合は、AprilTagを用意したり、それが十分に動画に収まる形で撮影をする必要があったりと、多くの制約もあります。

より長く、高品質な動画は以下の投稿をご覧ください。
イヤホンケースの動画中のマーカー(#AprilTag) を自動的に認識し、カメラの自己位置推定を行いました。この結果を利用して、#カメラキャリブレーション や、3次元再構成 (#SfM_MVS) 、#NeRF の入力 にも利用することができます。#MATLAB にて実装しています。 pic.twitter.com/7sFO17dqId
— Kenta@ScanX 開発部 (@dev_kenta) 2023年7月27日
7. NeRFについて
7.1 NeRFで利用されるニューラルネットワークについての概要
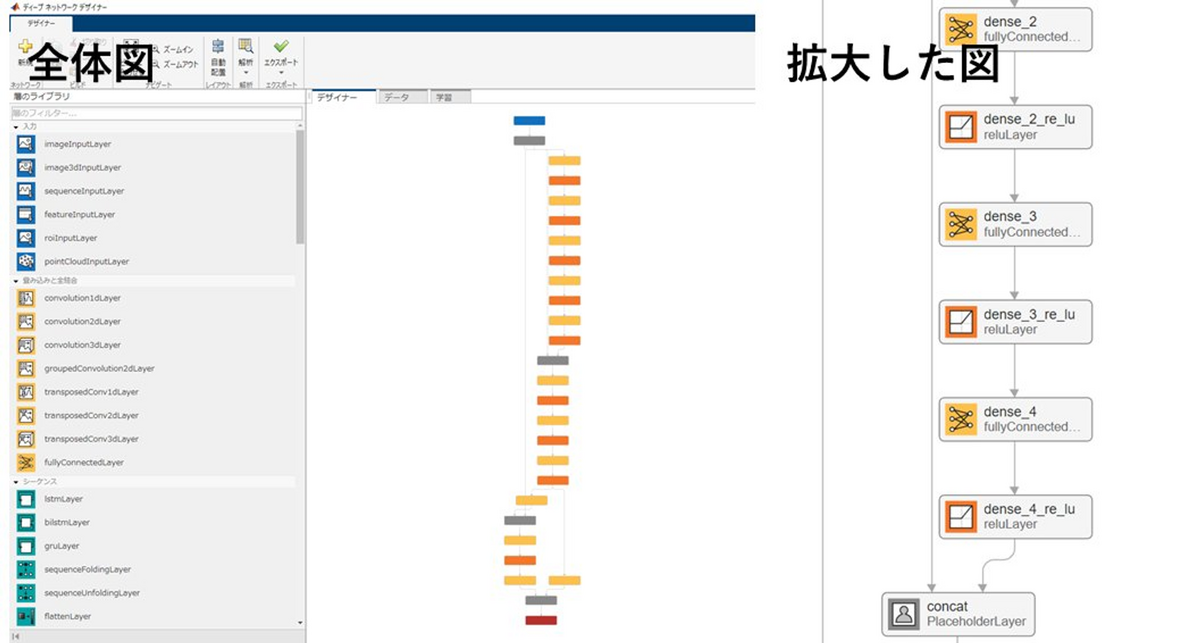
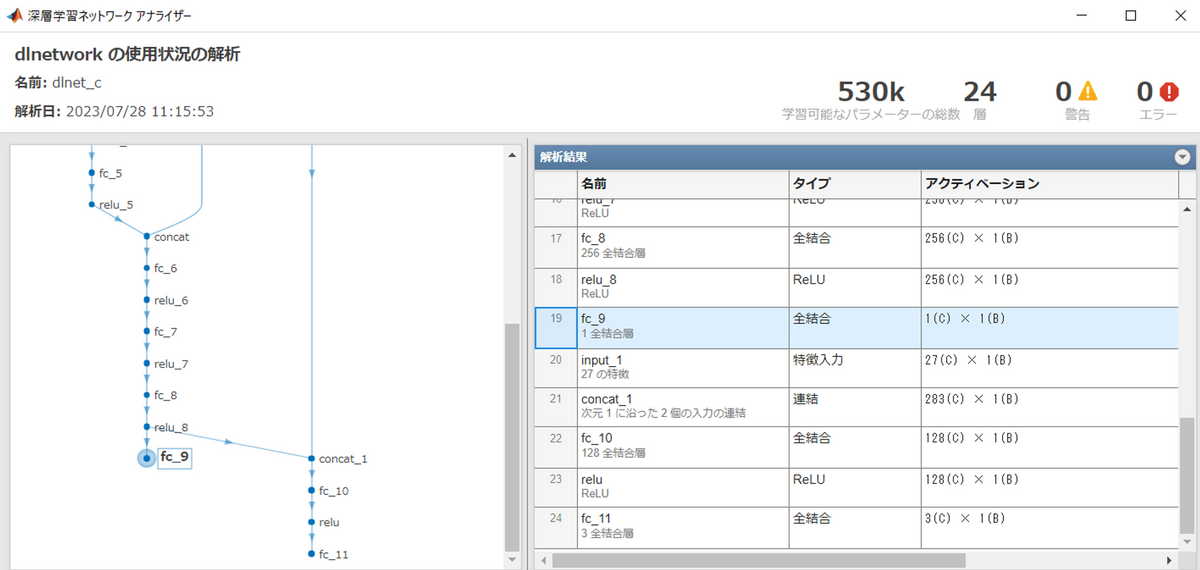
これまで、NeRFで利用されるニューラルネットワークでどのような処理が行われているか、ざっくりと話してきました。実際に、ニューラルネットワークの構造を見てみたいと思います。以下は、NeRFのネットワークをMATLABのDeepNetworkDesignerにて可視化しているときの結果です。赤枠が位置情報の入力、青枠が光線の向きに関する情報です。このように、NeRFのネットワークは2つの入力が必要です。それぞれ、全結合層 (fully connected layer) や正規化線形ユニット (Rectified Linear Unit: ReLU) 層にて処理されていきます。

別の例として、NeRFのオリジナル実装で利用されている深層学習ネットワークの構造も同様にMATLABで確認してみました。
上のgithubのページで利用されているNeRFのモデルをh5形式で保存し、MATLAB内のPythonの深層学習ネットワークモデルのインポートの関数で読み込みました。全結合層の位置やパラメータなどを画面上で確認できます。この実装では、1つの入力層があり、その直後に、splitするレイヤーを設けて仮想的に2入力のネットワークを構築していることがわかります。
以下のコードを利用して可視化しました。importKerasLayers関数を利用することでh5形式のNeRFのモデルをインポートできます。これを実行する際は、modelフォルダの中身もダウンロードしておく必要があります。
またNeRFのネットワークでは、対象とする点の色と密度を返すと上で説明してきました。実際にネットワークはどのようになっているでしょうか。
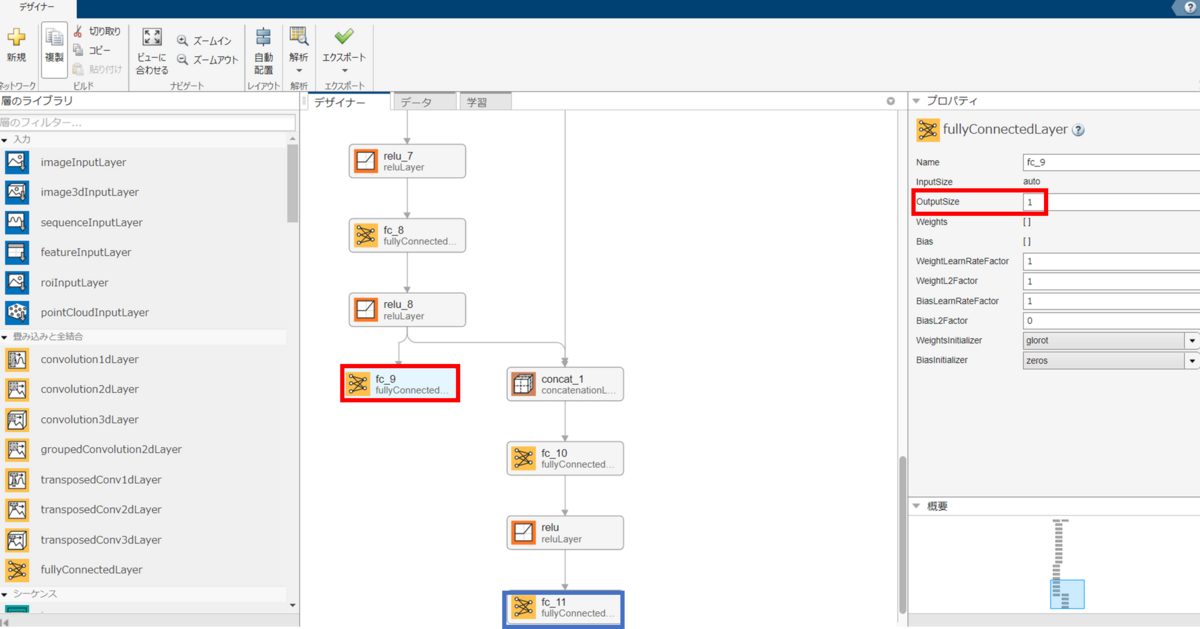
下の図を見てください。fc_9から出力される値のサイズは1×1になっています。右側の赤枠に書かれています。これは密度σに関してです。また、真ん中下の青枠は色に関する出力です。こちらのサイズはRGBで色を表したときの3×1になっています。
このようにNeRFのネットワークは2入力、2出力であることがわかりました。しかし、fc_9の赤枠を見てください。こちらは入力の左側 (上の図で言うinput、input_1でないほう)の入力が全結合層などで計算されて、入力の右側 (上の図で言うinput_1)からは情報が伝達されません。つまり、光線の向きは考慮されずに、対象のXYZ情報のみで密度σの値が決定します。一方で、右側の出力(色情報)については、入力したXYZ情報と光線の向きの両方を加味して出力されます。concat_1という茶色のブロックでそれぞれの特徴量がつながっていることがわかります。この出力の位置が逆ではだめなのでしょうか。おそらく逆にしてしまうと、うまくNeRFのネットワークが機能しないと思われます。その理由については、本章の中の、「ニューラルネットワークの構造についてより詳しく」にて説明します。
7.2 密度σについて
4章にて、Fig. 2を利用しながら、訓練、推論ともに特定の光線に対して推論を行う際は、その光線上で複数点サンプリングし、その色と密度σを掛け合わせたような値を累積させて、そのカメラの画素に対する色を決定すると述べました。この密度σに関してより詳しく説明します。

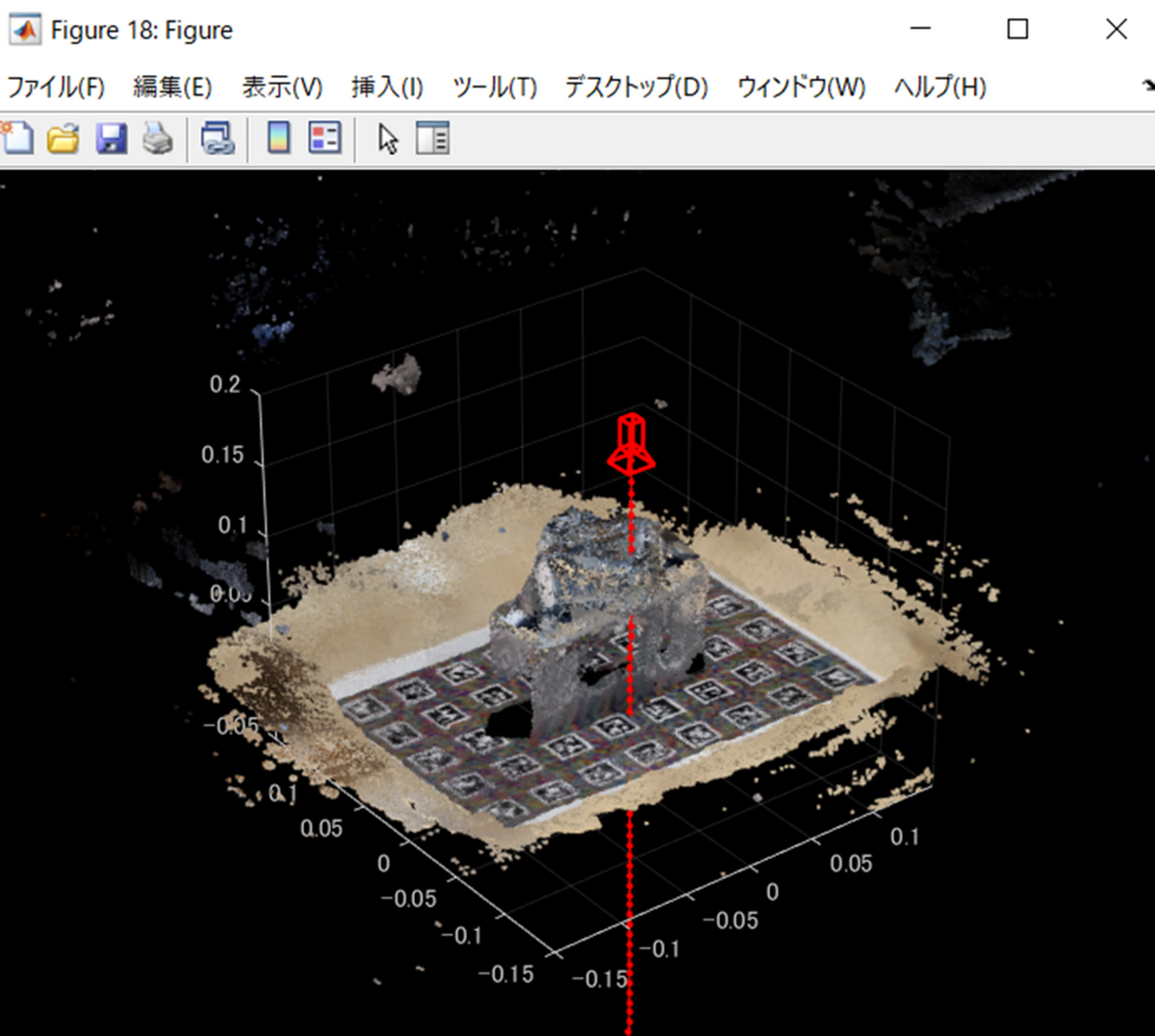
以下の図を見てください。訓練や推論で、以下の図中のカメラからその下に延びる破線にそって、光線を発しているとします。そして、この光線とカメラ平面の交点の画素でどのような色が返されるかを考えます。
上で説明したように、この計算においては、カメラから一定間隔で点をサンプリングし、その点XYZに対する色と密度σを求めます。以下の図では赤線がありますが、たくさんの赤い点で構成されていることがわかります。この点それぞれに対して、色と密度σを求めます。その点での物体の存在度合い(別の用語では論文中では、transmittanceと表現している)をこの光線に沿って足し合わせていきます。
カメラから発せられた光線はどこかにぶつかって跳ね返り、一部透過します。計算上は無限に遠い点に対しても計算できますが、実際に対象の範囲は限られるため、この以下の図のようなサンプリングする点の範囲を決めます。tn (nearest)から tf (farest)というパラメーター設定をします。そして、近い点から密度σを加味しながら色を計算していきます。そしてその密度の累積が一定の閾値を超えた時点でその光線が物体って反射しきったとして、追跡を終えます。
繰り返しになりますが、この操作を訓練の際は、訓練データに含まれる光線を無作為に取り出したものに対して訓練を行い、推論の際は、任意のカメラ位置と方向を定めたのちに、その仮想的なカメラの画素全てに対して上記の計算を行います。
The function T(t) denotes the accumulated transmittance along the ray from tn to t, i.e., the probability that the ray travels from tn to t without hitting any other particle. Rendering a view from our continuous neural radiance field requires estimating this integral C(r) for a camera ray traced through each pixel of the desired virtual camera.
tf (farest), tn (nearest) の間の点に対して、色や密度σを求めると言いました。上の画像で等間隔で複数の点がありましたが、実際はどれくらいの数や間隔で訓練や推論をすればよいでしょうか。この論文中では、N個の等間隔な点を作り、その点に対して、計算しています。また、この論文中では、NeRFのネットワークにバッチ正規化層 (Batch Normalization) や、Dropout層がないため、訓練・推論でネットワークの順伝搬の計算に違いはないと思われます。
また、この等間隔に設定されたN個の点の数はどのように設定すればよいでしょうか。このパラメータを大きくすると、より細かい間隔で点の色と密度σが求まるため、より詳細な3次元モデルが生成できると考えられます。一方で、その数が増えるにしたがい、計算時間も長くなるというデメリットがあります。この論文中で利用されたパラメーター設定に関しては、本章の「訓練パラメータについて」にて述べます。
7.3 レンダリング (Volume Rendering) について
前節にて、密度σという値をもとに、あるカメラの位置と向きからある画素に映る情報を計算すると述べました。具体的にどのように計算するのでしょうか。この論文中では、Volume Renderingという、先行研究にある方法を利用します。
通常は、求積法 (quadrature) を利用して、レンダリングを行い、対象の3次元的なシーンを計算します。ボクセルという、ボックス状に点を変換したモデルを利用することが多いが、その方法だと解像度に限界があり、キレイに見えないと記述があります。そして、上で述べた、tn, tfというパラメータを使いながらレンダリングし、3次元的なシーンを求める方法が提案されています。
We numerically estimate this continuous integral using quadrature. Deterministic quadrature, which is typically used for rendering discretized voxel grids, would effectively limit our representation’s resolution because the MLP would only be queried at a fixed discrete set of locations. Instead, we use a stratified sampling approach where we partition [tn, tf ] into N evenly-spaced bins and then draw one sample uniformly at random from within each bin:
求積法というと、区分求積法という言葉で聞いたことがあると思います。そこでは、対象とする範囲を一定の間隔で区切り、例えば面積を求める場合は、以下の図の赤色の区切られた面積を出し、足し合わせることで青色の面積を出します。ここでは、対象を等間隔に区切って、ボックス状(ボクセル)にして、その光線上で色を足し合わせていってもあまりキレイに見せれない、ということを言っていると思います。
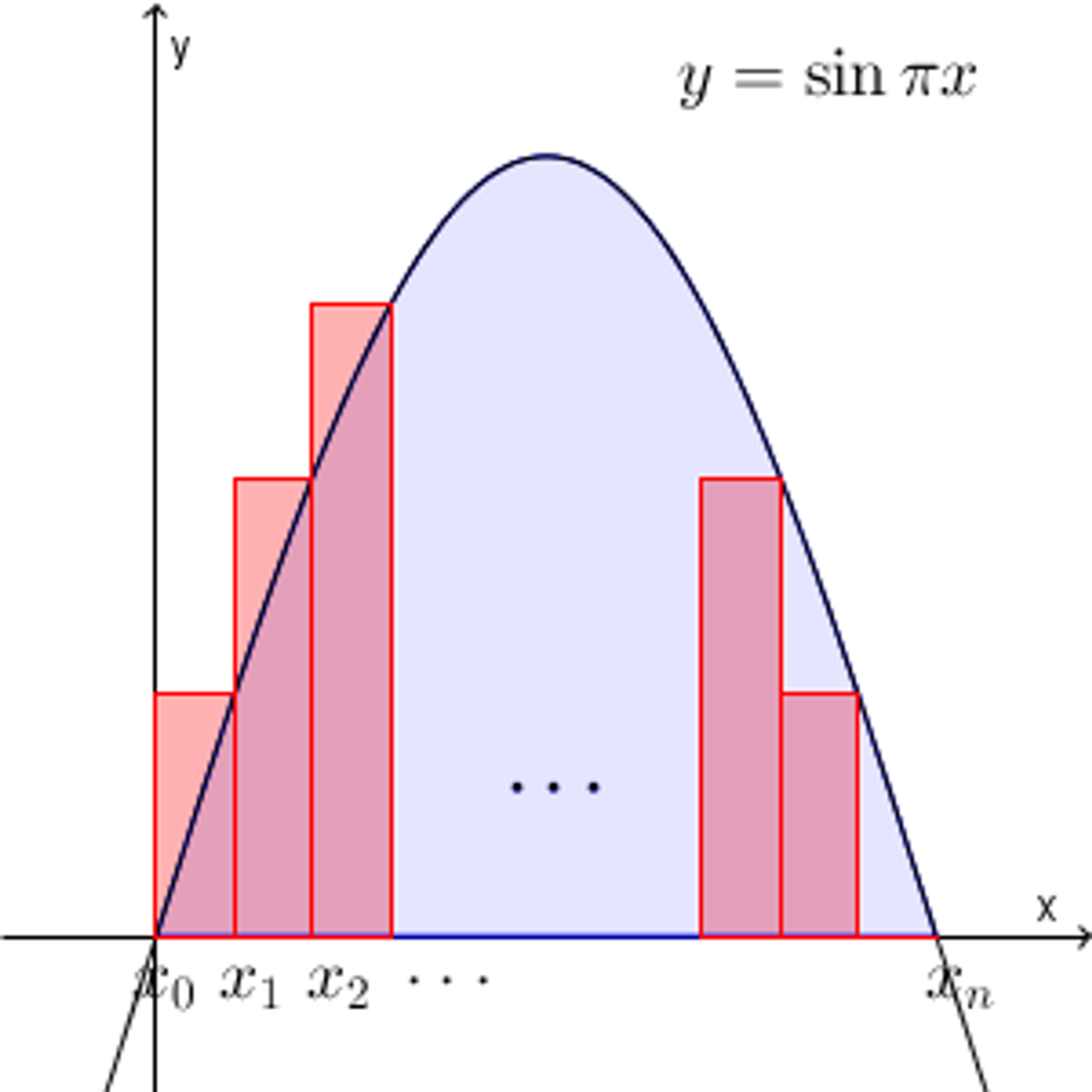
図出典: 【基本】区分求積法を使って和の極限を求める
そこで、推論する座標(カメラから見たときの奥行き)を2つの大きなレベルに分けて、階層的に推論 (hierarchical sampling) を行っていきます。まずは、対象の点の色をどのように求めるかについて述べます。色の決定に関しては、以下の論文中の式(1)が利用されます。
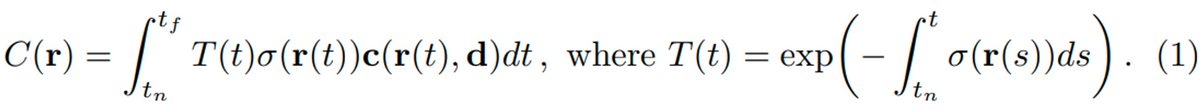
しかし、上で述べたように、等間隔に点を設置するので、以下の式(2)や(3)を利用して色を求めることができます。それぞれの式に関して考えていきます。
前提として、この式の操作をイメージで言うと、特定の光線上にて点をサンプリングし(以下の図では9点)、それぞれの点に対して、色と密度σを求め、遠いもの(右側)ほど、影響力を小さくしたうえで加味し、近い(左側)ほど、その色の影響力を大きくしたうえで計算します。以下の図の赤点から見ていき、はじめは大きな影響度をもって、その暫定的な色を決定します。さらにその次にある複数の点(赤、緑、黄色)に関して重み付けを行いながら暫定的な色をどんどん更新していきます。
この図は以下のブログから引用しています。
より具体的に述べます。まずは、サンプリングする点の座標について式(2)で定めています。先日したように、サンプリングする点の範囲をtnとtfで設定します。tnはカメラから最も近い(nearest)点のことなので、パラメータとして固定された値であることにご注意ください。何かのn番目の値ではありません。Nはサンプリングする点の総数(例: 64)です。そのため式(2)で定められるi番目の点tiに関しては、最も近い点tnを起点とし、等間隔に並べられた点のi番目の座標を計算することで求めていることになります。
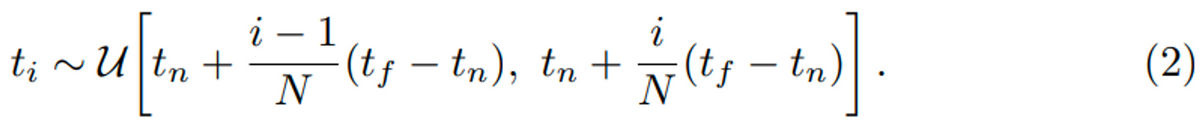
このように等間隔に設置された点tに対して、以下の式(3)で対象の点の色C(r)を計算します。
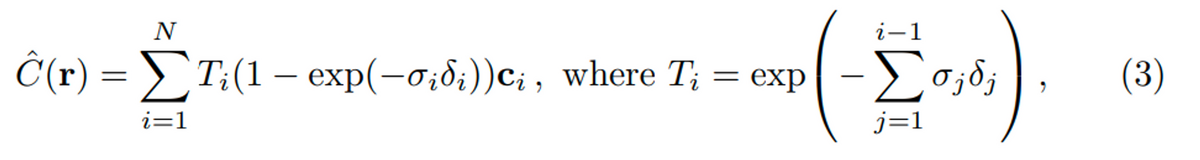
δは隣の点同士の距離で、ciはi番目のサンプリングされた点に対して推論された色の値です。
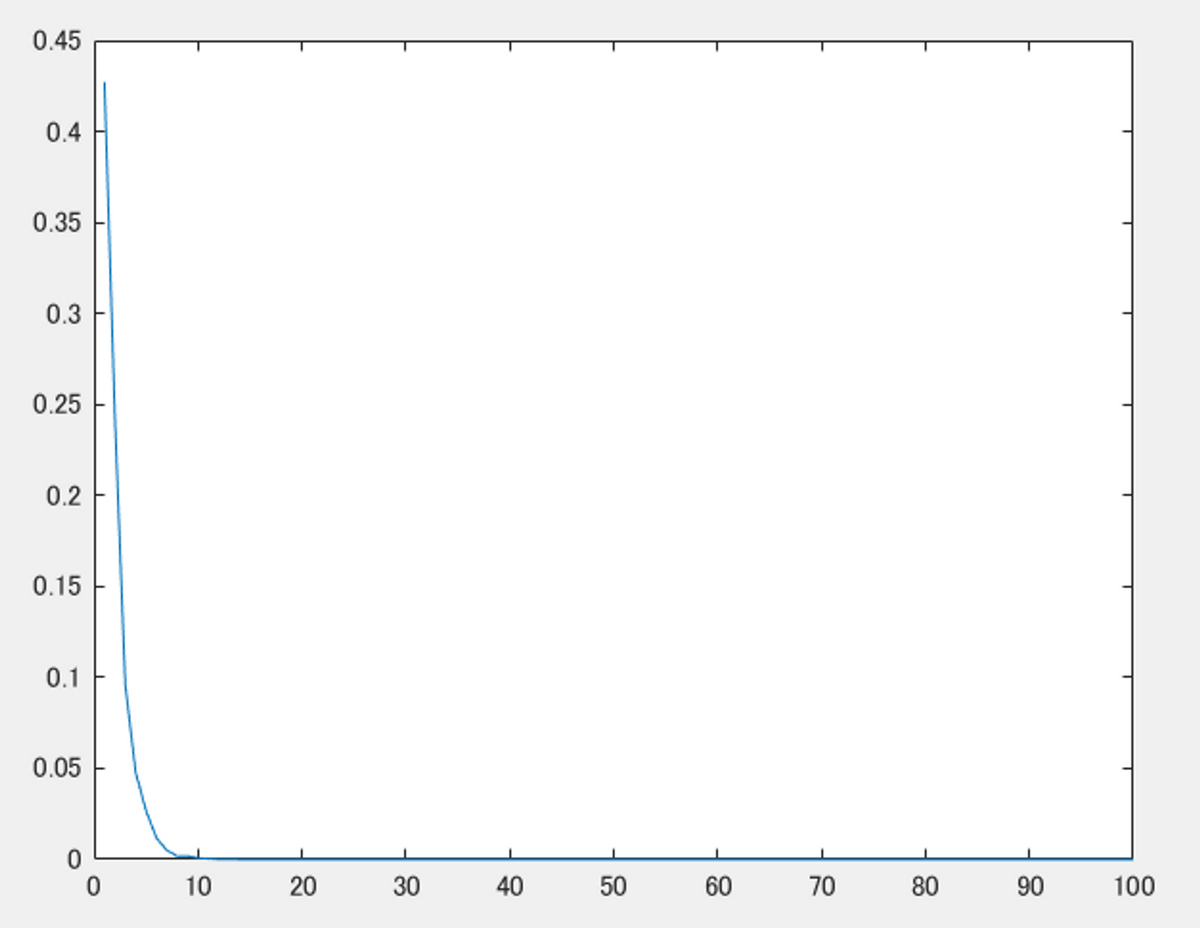
また、Tiに関してより詳しく見ていきます。光線が水平に進んでいて、隣の点どうしの距離は等しく1であるとします。そして、密度σに関しては、ランダムに設定します。以下の図は、横軸がiで、縦軸がそれぞれのTiの値をプロットしています。このTiは、式(3)のメインの部分からわかるように、i番目の点ciの色に対して乗ずる重みです。この重みの値は、iが大きくなる(カメラから遠くなる)につれ、どんどん減衰していくことがわかります。これにより、上で述べた、点ごとの優先度を変えていることに相当します。
dists = 1; sigma = rand([100,1]); T = exp(-cumsum(sigma.*dists)); figure; plot([1:1:numel(sigma)], T')
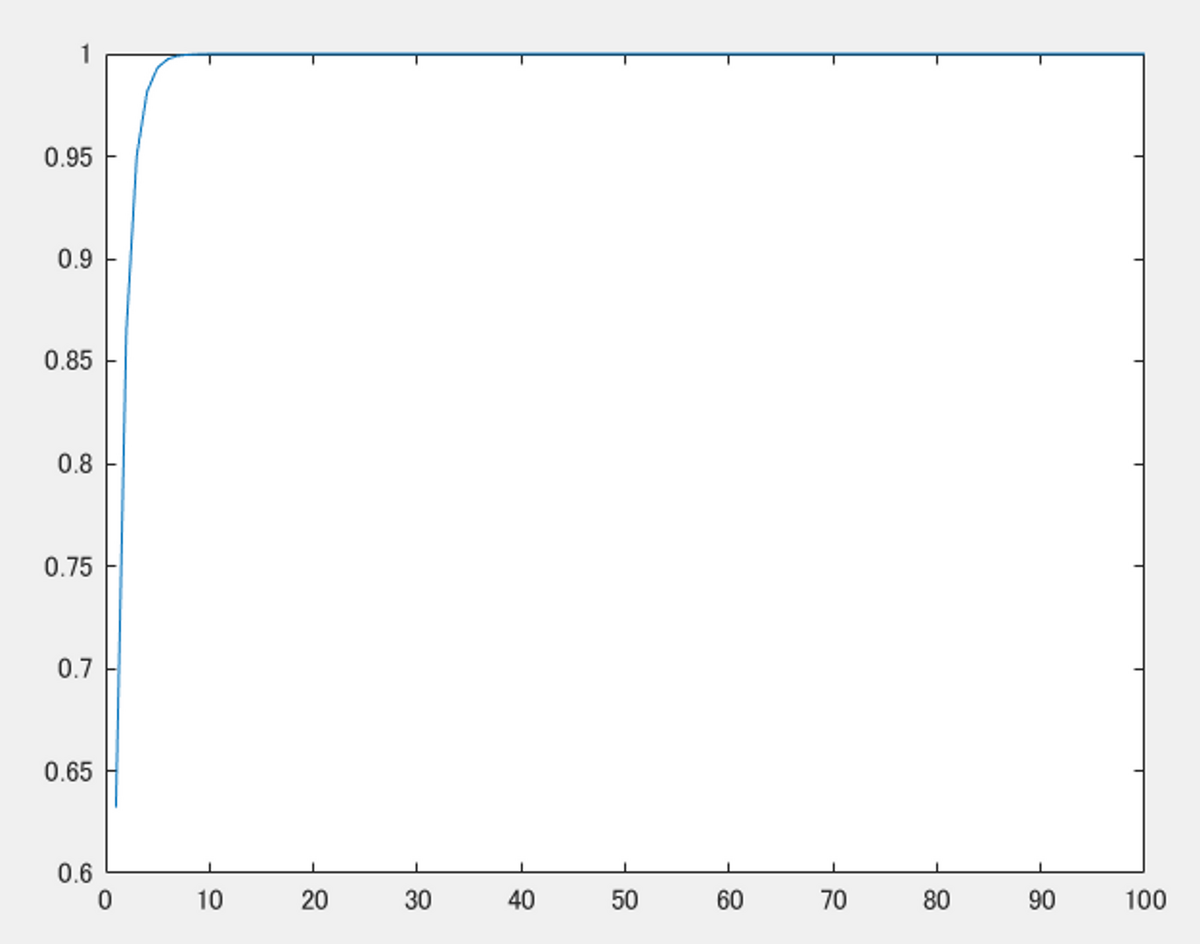
また式(3)の1-exp(-σδ)の部分について以下のコードでプロットしてみます。同様に、隣の点どうしの距離δは1であるとします。すると、σの値が大きければ大きいほど、1-exp(-σδ)の部分の値も大きくなることがわかります。ここから、上で述べたような、密度σの値が大きいほど、その点の色にかかる重みが大きくなる、ということが実現していることがわかります。この値は微分可能なのでNeRFのネットワークにも適していることもわかります。
dists = 1; x = [1:1:100]; alpha = 1 - exp(-x*dists); figure;plot(x,alpha)
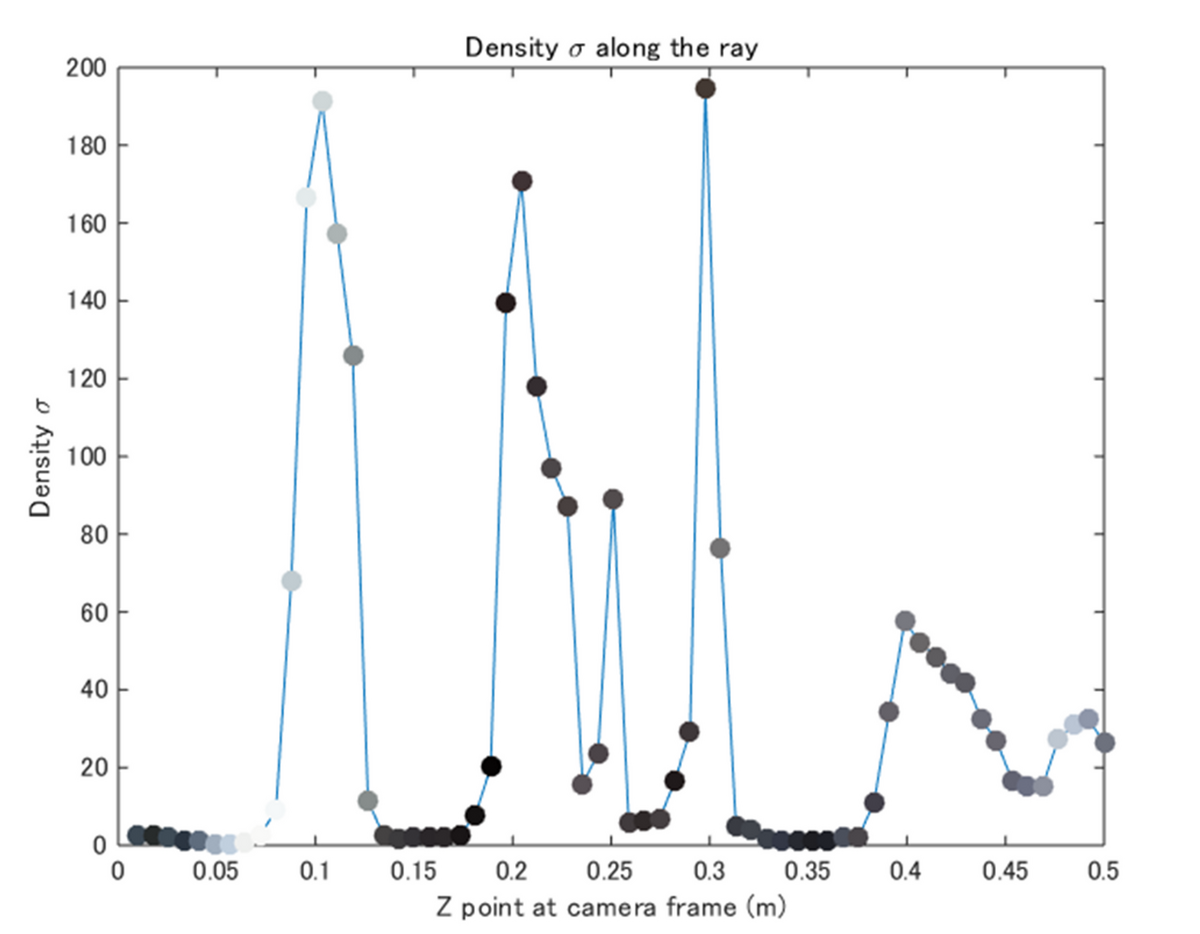
ここで述べたような、密度σとその色に関する関係性を以下の図で示しています。横軸はカメラからのそのサンプリングして点の距離、縦軸は密度σを示しています。また、各プロットの色は、その点に対する色を示しています。縦軸の密度σとその各プロットの色を掛け合わせることでその点での色の持ち点のようなものが決まります。さらに、そのカメラからの距離もかけて、カメラから近いほど優先されるように調整します。
より詳しいレンダリングの方法については、次の、Hierarchical volume samplingの節で追記します。
7.4 Hierarchical volume sampling
さきほどは、NeRFのネットワークを利用して、レンダリングをして、3次元的なシーンの情報を得るために、どのように密度σやカメラからの距離を利用して色を決定するか述べました。しかしそこの説明では等間隔に設置されたN個のサンプル点に対して計算を行っているままでした。この方法では以下の課題があります。
- 1つの光線にそって毎回N個のサンプリングを行うと非効率である。なぜなら、物体のない領域や、その視点から隠れていて、見えるはずのない場所の点に対して推論し続けるというケースが発生する
Our rendering strategy of densely evaluating the neural radiance field network at N query points along each camera ray is inefficient: free space and occluded regions that do not contribute to the rendered image are still sampled repeatedly
上で述べたシーンの再構成を1つのネットワークで行うのではなくて、2つのネットワークにて段階的に行います。ここでは、それらをそれぞれ、coarse、fineと呼びます。NeRFにおいては、同じ構造を有するニューラルネットワークが2つ必要です。
Instead of just using a single network to represent the scene, we simultaneously optimize two networks: one “coarse” and one “fine”.
まずは、coarseネットワークで推論を行い、その中で、密度の物体がありそうな場所にしぼって、fineネットワークで再度推論を行います。coarseネットワークによる推論では、等間隔に点を設置し、その座標の推論を行います。この操作はこれまで述べたものと同様です。
Instead of just using a single network to represent the scene, we simultaneously optimize two networks: one “coarse” and one “fine”. We first sample a set of Nc locations using stratified sampling, and evaluate the “coarse” network at these locations as described in Eqns. 2 and 3.
以下の、Given以下を見てください。先ほどの式(3)で見た、式(3)の1-exp(-σδ)の部分が再登場しています。こちらは、密度σの値が大きいほど、その点の色にかかる重みが大きくなる、ということを微分可能な形で実現していたのでした。これがこの式(5)にて、Tiと掛け合わされたうえで重みwとして出てきています。この重みが多いほど多くサンプリングし、逆にこの重みが小さい、つまり点のない空間である可能性が高い点は低い確率でサンプリングする、という方式で、fineネットワークに入力する点の座標を決定します。

ただし、レンダリングの際は、coarseとfineの両方の情報を利用します (but using all Nc+Nf samples)。
7.5 損失関数 (Loss Function) について
さきほどのHierarchical volume samplingや、5章で述べた手順に従い、各点の色情報を決定することができました。この色情報が定まったのちに、訓練時にはどのようにその正確さを評価すればよいでしょうか。訓練の際は以下の手続きを経ます。
- カメラの画素をランダムに抽出し、外部パラメータを利用して、ワールド座標系に変換したのちに、それに対して推論を行う。
- Hierarchical volume samplingを利用して、N個の等間隔に設置された点に対して、coarseネットワークにて計算を行い、さらに、式(5)で定められる重みによって定められる分布から生ずる点に対して、fineネットワークにて計算を行う。
- シンプルに以下の式(6)のように、色情報でロスを求める。coarseとfineの両方の出力に対して損失を求める。
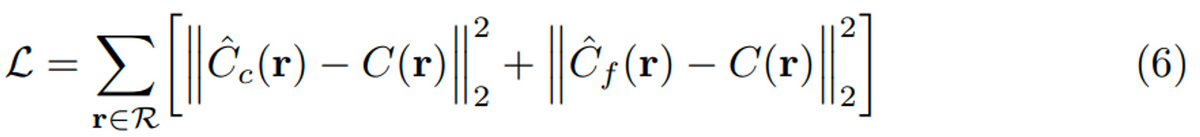
At each optimization iteration, we randomly sample a batch of camera rays from the set of all pixels in the dataset, and then follow the hierarchical sampling described in Sec. 5.2 to query Nc samples from the coarse network and Nc + Nf samples from the fine network. We then use the volume rendering procedure described in Sec. 4 to render the color of each ray from both sets of samples. Our loss is simply the total squared error between the rendered and true pixel colors for both the coarse and fine renderings:
さきほども述べたように、fine, coarseの2つのネットワークの計算においては、密度σの値も利用されています。そしてこのσの値が正しいほど、この損失の値も小さくなります。つまり、ここでは色情報のみを利用して損失を求めているものの、その計算には間接的にσも含まれています。この損失関数までの説明で、NeRFのネットワークの訓練から評価方法まで説明されました。次節からはもう少し詳しい話になります。
7.6 入力の座標と光線の向きの変換について: Positional Encoding
NeRFのネットワークには、対象とする点の位置とその点を見る時の光線の向きを入力するのでした。しかし、実際は生のXYZ座標やその光の方向を入力するわけではありません。Positional Encodingと呼ばれる方法で、より高次元に変換してからネットワークにて計算を行います。この論文で利用されている式は以下の通りです。pは位置を表し、位置XYZの場合は、pは例えば (1, 2, 3)のようになります。それをsin, cosに対して、XYZそれぞれに対して入力し、計算します。ここはこの処理そのものに関しては、特に深く考える必要はなく、XYZの情報を順番に2の累乗のπをかけながら、sinやcosの式に入れて変換するだけです。ここでのパラメータはLという値で、何セット分sinとcosの項にするかということです。論文中では、XYZ座標に対してはL=10、カメラの向きに関してはL=4が設定されています。XYZ座標のほうが、より高い次元に写像されたうえで訓練や推論されます。
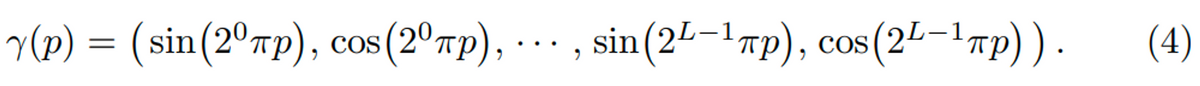
この操作を簡単に実装したものが以下になります。順番にXYZに対してsinやcosで計算をし、最後はそれらをくっつけています。
% positional encoding in NeRF % This function is performed in the following paper. % NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis clear;clc;close all % parameter L = 10; % xyz p1 = [1 2 3]'; freq_bands = reshape(repelem(2.^(0:(L-1)),1,size(p1,1)),size(p1,1),1,[]); emb_period = [sin(freq_bands.*repmat(p1,[1,1,L]));cos(freq_bands.*repmat(p1,[1,1,L]))]; emb_period = reshape(permute((emb_period),[1,3,2]),[],size(p1,2))'; freqBands = p1 .* repmat(2.^[0:L-1], [3, 1]); % sin=>x, y, z *10 = 30 sin1 = sin(freqBands); % cos=>x, y, z *10 = 30 cos1 = cos(freqBands); % combine both sin and cos embed = [sin1(:); cos1(:)]
そのままXYZなどの値を入力するのではなく、先に高次元に変換したほうがうまく学習できたそうです。結果の章では、この操作ありなしの結果を比較しているので詳しい差は後述します。
先行研究でもこのような変換をしたほうがうまく学習ができることが報告されていて、今回はそれに倣っています。
Despite the fact that neural networks are universal function approximators [14], we found that having the network FΘ directly operate on xyzθφ input coordinates results in renderings that perform poorly at representing high-frequency variation in color and geometry. This is consistent with recent work by Rahaman et al. [35], which shows that deep networks are biased towards learning lower frequency functions. They additionally show that mapping the inputs to a higher dimensional space using high frequency functions before passing them to the network enables better fitting of data that contains high frequency variation.
Rahaman, N., Baratin, A., Arpit, D., Dr¨axler, F., Lin, M., Hamprecht, F.A., Bengio, Y., Courville, A.C.: On the spectral bias of neural networks. In: ICML (2018)
7.7 ニューラルネットワークの構造についてより詳しく
7.1の最後のパラグラフにて、色の情報は、対象の点の位置と光線の向きの両方が加味されるのに対し、密度σの値はその点の情報のみで決定すると述べました。これについて考えます。
NeRFのネットワークでは、任意の点Pに対しては、密度σはどの角度から見ても同じ値が返される一方で、色に関しては、その点を見る向き、より厳密にいうと、その光線の向きによって違う色が返されるよう (view-dependent) に設計されています。なぜなら、ある物体上の点を見てもその物体の存在度合い(密度)は、どの角度から見ても同じです。一方で、反射などがあるため、同じ物体上の点を見ても、見る角度によっては、白く見えたり、暗く見えたりするはずです。このような制約をニューラルネットワークに学習するためにはどうすればよいでしょうか。これに関しては以下の記述が対応しています。
We encourage the representation to be multiview consistent by restricting the network to predict the volume density σ as a function of only the location x, while allowing the RGB color c to be predicted as a function of both location and viewing direction. To accomplish this, the MLP FΘ first processes the input 3D coordinate x with 8 fully-connected layers (using ReLU activations and 256 channels per layer), and outputs σ and a 256-dimensional feature vector. This feature vector is then concatenated with the camera ray’s viewing direction and passed to one additional fully-connected layer (using a ReLU activation and 128 channels) that output the view-dependent RGB color.
また、これと7.1の最後のパラグラフが対応しています。
つまり、以下の図のように、点の位置の入力(Positional Encodingされた60次元の値ともとのXYZを足した63次元)の値が以下の左下のように全結合層などで処理されます。

そして、光線の向きの影響を受けないように、つまり光線の向きの情報は流れ込まない状態で以下の図の左下のfc_9のように密度σの値が決定します。このようなNeRFのネットワーク構造により、密度σの値が、光線の向きによらない、つまりどの向きから見ても密度σの値は同一であるように設計されています。
しかし、色情報に関しては位置だけでなく、その点を見る方向も加味される必要があるため、以下のようなに2つの入力から得られた特徴量を合流させたうえで計算させています。

また、ここのNeRFのネットワークの可視化に関しては、MATLABのAnalyzeNetworkアプリを利用しました。ここでは、そのネットワークが適切かどうか自動的に判定したり、各層での出力サイズなどを可視化したりすることができます。
一方で、NeRFの学習をするにあたって、全結合層の数や次元数、そして、それらの重みやバイアスの初期値の設定など、いろいろと変えて実験したくなると思います。その場合は、MATLABを利用する場合、DeepNetworkDesignerが便利です。UI上でそれらのパラメータなどを柔軟に変更することができます。
7.8 訓練パラメータについて
これまでで述べたようなNeRFのネットワークには、多くのパラメーター設定が存在します。この中で主要なものを説明します。
- 訓練時に各ミニバッチとして利用する光線の数: 4096本
- 推論時は画像のピクセルごとにスキャンしていくイメージ。そのため、訓練の際は各画像から限られた数の光線が利用される一方で、推論の際は、カメラの画素分だけ光線が利用される。
- 例えば、画像分類では、画像を32枚ごとに取り出して、それをミニバッチとするが、今回はこの光線の数がミニバッチに相当する
- レンダリングの際の、光線方向にサンプリングする点の数はcoarseネットワークでは64個、fineネットワークでは128個である
- オプティマイザーはAdamを利用した
- その中のパラメーターは以下の英文を参照のこと
- 100–300kの反復が必要であった
In our experiments, we use a batch size of 4096 rays, each sampled at Nc = 64 coordinates in the coarse volume and Nf = 128 additional coordinates in the fine volume. We use the Adam optimizer [18] with a learning rate that begins at 5 × 10−4 and decays exponentially to 5 × 10−5 over the course of optimization (other Adam hyperparameters are left at default values of β1 = 0.9, β2 = 0.999, and = 10−7). The optimization for a single scene typically take around 100–300k iterations to converge on a single NVIDIA V100 GPU (about 1–2 days).
8. 結果について
8.1 4章のVolume Rendering with Radiance Fieldsに掲載されている図について
以下の、Fig. 4 を見てください。実際の正解データ(Ground Truth)、本手法の結果 (Complete Model)、視点ごとに異なって見えるようにする機能を入れずにNeRFを学習した場合(No View Dependence)、および、Positional Encodingを使わないで、NeRFを学習させた場合の4つの結果を示しています。
はじめの2つはわかりますが、後半の2つがわかりにくいかもしれません。view dependenceというのは先述したとおり、角度によってキラキラしたり、していなかったり色々な見えかたがするのを反映させた結果です。逆にここでは、No view dependenceとあるので、その機能を入れずに学習した場合です。具体的には、7.1や7.7で示したような、NeRFのニューラルネットワークで、光線の方向の入力をなくしたうえで、訓練や推論を行ったときの結果であると思われます。つまり、見る視点に関わらず同じ色を返すようにしているネットワークを利用した時の結果です。No Positional Encodingは、7.6で説明した、Positional Encodingの機能を利用せずにネットワークを訓練、推論したときの結果です。
No view dependenceのほうは、ブルドーザーのおもちゃの反射特性がうまく再現できていません。また、No Positional Encodingでは、ブルドーザーのタイヤ付近の変動の大きい細かい部分 (High Frequency Geometry)をうまく再現できていません。

8.2 Ablation studiesについて
Ablation studyでは、何か1つ条件を変えて、その変数の影響を議論します。また評価指標はPSNR、SSIM、LPIPSの3つを示しています。それぞれ高い、高い、低いほうが優れています。ここでは、各評価指標の詳細は割愛します。
表の中のそれぞれの結果を見ていきたいと思います。赤枠は No Positional Encodingの場合を示していて、7.6で説明した、Positional Encodingの機能を利用せずにネットワークを訓練、推論したときの結果です。3つの評価指標は、どの項目においても本手法の結果(Complete Model)よりも劣っていて、Positonal Encodingが重要であることが示唆されます。
同様にして他の結果についても見ていきます。青枠は、No Hierarchical とあり、7.3で示した、Fine, Coarseの2つのネットワークやサンプリング方式を使うのではなく、片方のみのネットワークやサンプリングで行った場合です。黄緑のFewer Imagesは、より少ない画像枚数で行った場合、また、黄色のFewer (More) Frequeciesとは、7.6で説明した、Positional Encodingの際に用いるSin, Cosの数です。より多くの項を利用して、XYZをEncodingする(しない)場合の結果を示しています。どの結果も、本手法の結果(Complete Model)よりも劣っていて、それぞれの手法が重要であることが示唆されます。

8.3 追加実験 (Followup Work)
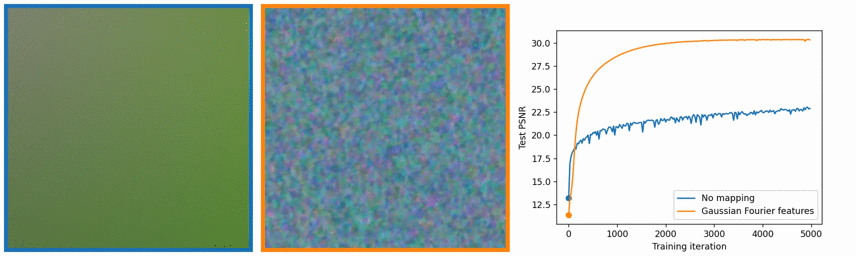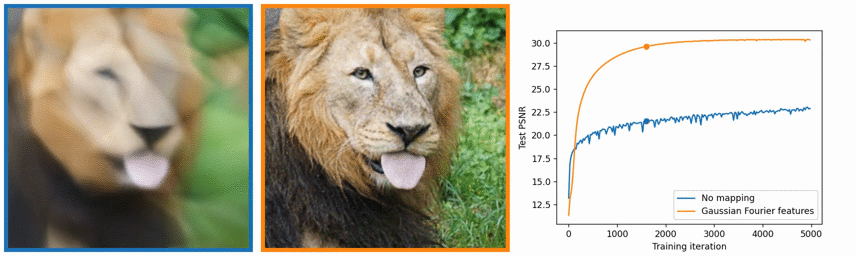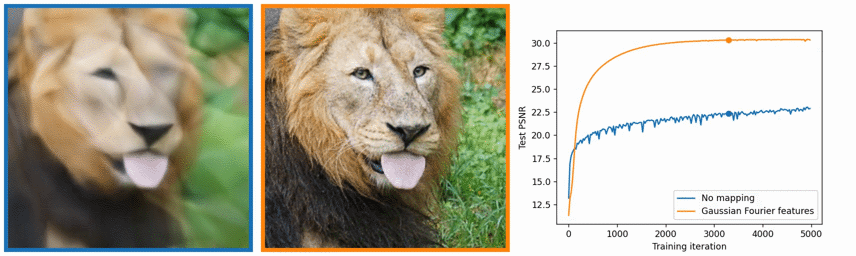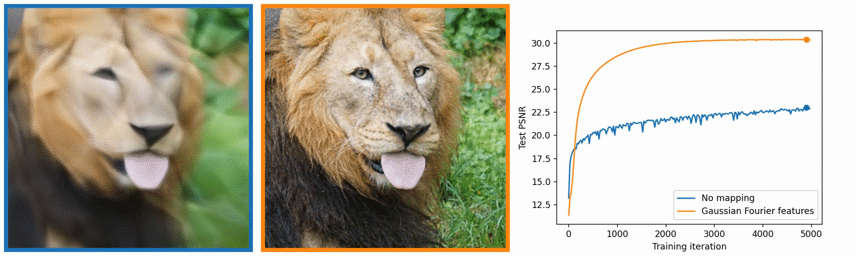
これは、7.6で説明した、Positional Encodingの利用の有無に関する比較だと思います。この図は、論文中ではなく、以下のProject Pageに掲載されていました。Positional Encodingを利用した場合(右)のほうが、きめ細かい画像が生成できています。一方で、左はのっぺりと広がったような価値になっています。一番右の曲線を見ても、Positional Encodingを利用した場合(オレンジ)のほうが、使わなかった場合(青)よりも、少ない訓練数で、高い精度を出せていることがわかります。
Fully-connected deep networks are biased to learn low frequencies faster. Surprisingly, applying a simple mapping to the network input is able to mitigate this issue. We explore these input mappings in a followup work.
8.4 出力のメッシュ化について
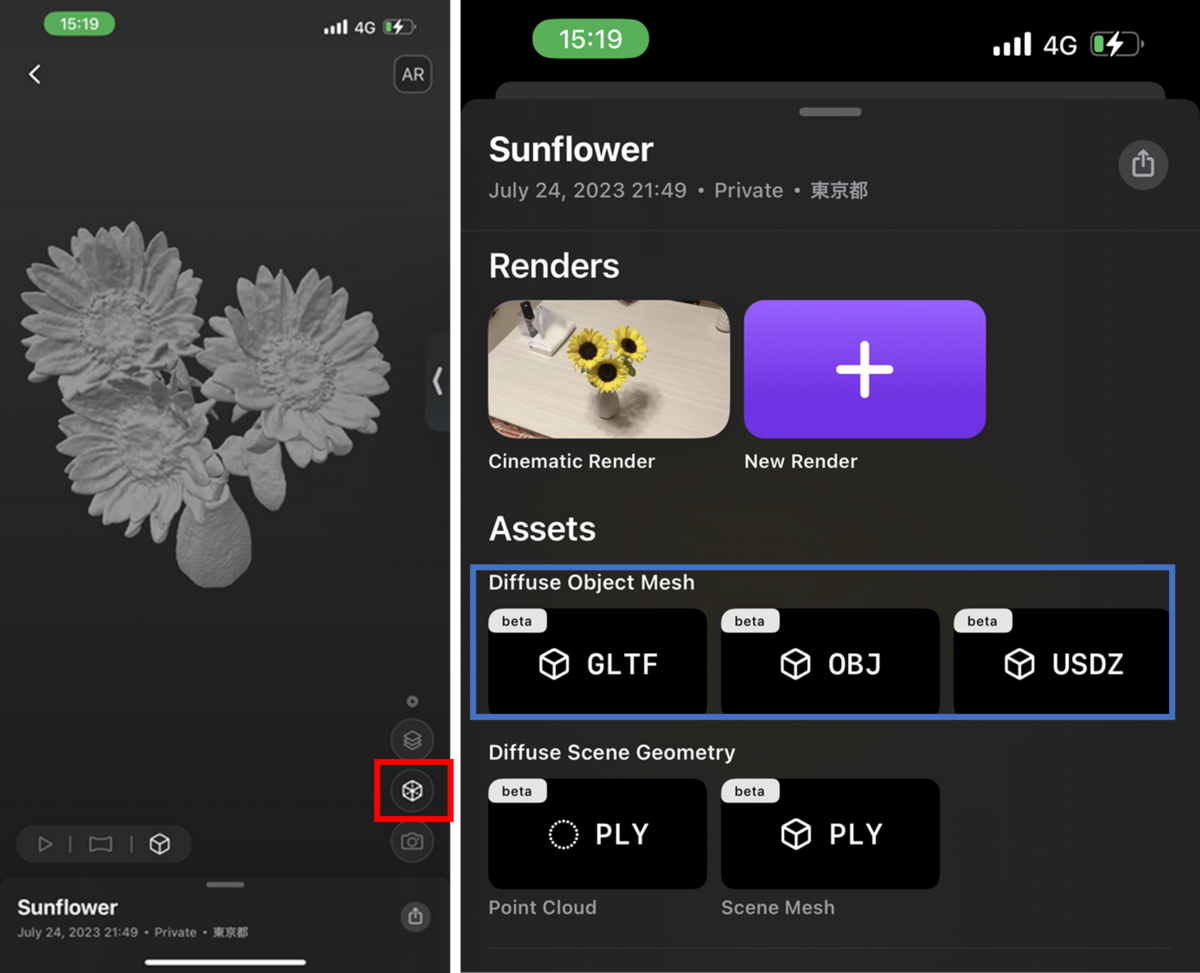
論文中にはほとんど記述がありませんが、NeRFのgithubのページには、NeRFにより出力されたモデル(点群)をメッシュモデルに変換しています。
また、2章で紹介した、LumaAIでも、メッシュモデルの表示ができます(赤枠)。また、それらをGLTFなどの形式でエキスポートすることができます。
これは、NeRF自体の機能ではなく、NeRFで得られた点をマーチングキューブ法と呼ばれる手法でメッシュ化しています。
マーチングキューブ法の詳細は以下のページがわかりやすかったです。
9. NeRFにおける制限について
今回のNeRFの手法における制限について述べます。これらは後続の研究で解消されている場合もあります。あくまで本論文に書かれていた手法に限った話です。
- 複数のシーンを学習させることはできない: 対象物をカメラで撮影した時の光線の向きやその(ワールド)座標系の点に対する色を推論します。そのため、似た物体であっても、対象物が変わったり、移動すると画像撮影からやり直す必要があります。
- 畳み込み演算を利用しているわけではない: 画像を扱う深層学習ネットワークでは、Convolutional Neural Network (CNN) と呼ばれるような、畳み込み演算を利用したネットワークが広く活躍しています。ここでは、リモートセンシングの分野などで利用されるフィルター処理のような計算が行われ、エッジの情報などが畳み込み演算の過程で画像特徴として獲得されることが知られています。しかし、NeRFにおいては、もともとの入力は画像であるものの、そのような処理は行っていません。そのため、少なくとも明示的には、画像の周辺情報などは加味しない形で学習を行っています。
- Fine-tuningの要領で、学習済みのニューラルネットワークを再利用することは難しい: 対象物を少しだけ回転させたり移動させたりしただけ、といったような場合を除き、基本的には、以前に利用したニューラルネットワークを再利用して、Fine-tuningを行うことは難しいと思います。しかし、例えば、部屋の中の物体などと限定して、そこにありそうなモデルで無数に学習して、重みの中央値などを取るとそのニューラルネットワークをベースに学習するとよい、みたいな状況が出てくるかもしれませんね。
- SfMなどのカメラの位置推定がうまくいっていない場合は、NeRFのネットワークをどれだけ訓練させてもよい結果を得ることが難しい: NeRFの訓練は、カメラの位置や向きを既知として扱うため、その情報が正しくない場合はうまくいかないと考えられます。自己位置推定もニューラルネットワークなどでEnd-to-Endでできるようなモデルがあるといいですね。
- より細かい3次元モデルを生成しようとすると、非常に時間がかかる:
推論の際は、任意の画素に対して、光線を発し、その光線上で、あらかじめ設定した点数(例: 64)の分だけ計算を行います。より細かいモデルが欲しい場合は、この点数を多くして、イメージ的には、対象をボクセル状にしたときの細かさを上げていきます。しかし、単純計算では、ボリュームの3次元のスピードで計算量が増えていくと思います。
10. 考えられる工夫点
こちらも同様に、私が論文を読んで思ったことで、後続研究で解消されていたり、そもそも私の勘違いもあると思います。
1 画素単位で訓練や推論を行うのではなく、周囲の情報もうまく取り入れるといいのではないか: Mip-NeRFという後続研究があります。
こちらのスライドがわかりやすかったです。
2 損失関数について:
本論文では、色の2乗誤差というシンプルな関数を利用しています。例えば以下のMip-NeRFでは、歪みに基づく正則化を用いています。
この他にもいろいろと損失関数の工夫のアイデアがありそうです。例えば訓練の過程でもあえて、画像全体に対して推論を行い、その画像がNeRFにより生成されたものなのか、それとも入力の画像なのかを判定させる、Adversarial Lossのような機構を取り入れるといいかもしれません。敵対的生成ネットワーク (Generative Adversarial Network: GAN) 使われる手法です。こちらも似たことをした研究はありそうです。
例えば、Adversarial Lossを利用したネットワークは以下の記事でまとめています。
3 ライトフィールドカメラやステレオカメラは使えないか:
NeRFでは、学習の際に対象の3次元点群は用いていません。そのため、密度σという出力を利用して、深度情報を計算します。しかし、より直接的に、深度情報もニューラルネットワークで出力できると、任意視点からのシーン生成に加え、生成される3次元モデルの精度も高まるかもしれません。例えば、ステレオカメラを利用して、対象の深度情報も同時に取得して、その情報を密度情報と紐づけて学習するのもおもしろそうです。ただステレオカメラである程度対象物やその周辺の3次元情報が取れているので、あまりNeRFと併用する意味はないかもしれません。ライトフィールドカメラについても同様です。
11. 結論
結論の章では以下のような記述がありました。
ある視点から対象物を見たときに、その光線上にある任意の点の密度と見え方(色)を返すニューラルネットワークが提案された。
an MLP that outputs volume density and view-dependent emitted radiance as a function of 3D location and 2D viewing direction
レンダリングするために、hierarchical samplingを利用したが、工夫の余地もあると思われる
Although we have proposed a hierarchical sampling strategy to make rendering more sample-efficient (for both training and testing), there is still much more progress to be made in investigating techniques to efficiently optimize and render neural radiance fields
長くなってしまいしたが、任意の視点から見たときのシーンを生成するNeRFについてのまとめを行いました。
論文や実装を見たり、NeRFを体験するうえで考えたことなどを12章にまとめます。
12. Self-QA
1 SfM-MVSやLiDARとの違いは?
メインの生成物がちがう。SfM-MVSは点群(やメッシュモデル)を作ることができる、一方で、NeRFでは、新しい視点から見たときにどのような感じに見えるかがわかるようになる。ここでは、SfM-MVSやLiDARから出力される点群などとは異なり、角度ごとに違う見え方のするシーンを再構成することができる。新しい視点を作る過程で、間接的に奥行きに相当する情報(シグマ)も計算するため、3次元モデル自体を構成することもできるが、あくまで、NeRFの主たる出力は任意の視点からのシーン生成で、メッシュモデルなどはあくまで副産物的な立ち位置だと思う。SfM-MVSにおいては、点群やメッシュモデル、オルソ画像などが主な出力で、LiDARの主な出力は点群である。
なお、本記事では、SfMについて扱ったが、その点群をより高密度にする(dense image matching)技術である、多視点ステレオ (Multi-View Stereo: MVS)については6.4での補足にとどまっている。
MVSについては、以下の論文がわかりやすい。
布施 孝志先生: 解説:Structure from Motion (SfM) 第二回 SfM と多視点ステレオ
https://www.jstage.jst.go.jp/article/jsprs/55/4/55_259/_pdf
Furukawa, Yasutaka, and Carlos Hernández. "Multi-view stereo: A tutorial." Foundations and Trends® in Computer Graphics and Vision 9.1-2 (2015): 1-148.
2 SfMで作った対象の点群のXYZ座標を使っているのか?
使っていない。SfMはカメラの位置と向きを求めるために利用する。
3 NeRFを利用したアプリケーション(例: LumaAI) で、対象の3次元モデルを得たとする。この行為を「3Dスキャンをした」と表現してよいか?
広い意味で捉えると問題ないと思う。スキャンと聞くと、レーザースキャナなどで、対象にレーザを照射し、その光が返ってくるまでの時間を利用して対象の3次元モデルを作成する、そしてそれを少しずつずらしながら走査することで対象の像を得ていく、ということをイメージすることが多い。一方、NeRFでは、画像のみを入力としていて、そのようなレーザ照射は含まれない。しかし、NeRF(のニューラルネットワーク)における推論では、各画素に対する仮想的な光線を考え、その光線を各画素に対して順番に当てて、計算していくイメージである。これは走査(スキャン)することを連想させ、(実際にレーザ照射はしないものの)「3Dスキャンしている」と言っても間違いにはならないのではないか。
4 ニューラルネットワークの「記憶力」はどれくらいなのか?
わからない。上の実装では、あまり深くないニューラルネットワークの学習を行った。例えば、非常に多くの角度から、たくさんの物体を含む対象を学習させた場合、そのようなニューラルネットワークで、あらゆるカメラの位置と向きから見たときの様子を再現できるのだろうか。推論の際の計算コストと同時に、広いシーンを細かく再現しようとすると、ニューラルネットワークが「記憶」しきれず、うまく再構成できない、ということはないのか。
5 SfMのソフトウェアとしては、Agisoft Metashapeが有名だが、どのような特徴点の種類を利用しているのか?
SIFTに似たもので、それよりもマッチングがうまくいく方法らしい。以下は現在のMetashapeの前のバージョンの、PhotoScanに対する記述である。
At the first stage PhotoScan detects points in the source photos which are stable under viewpoint and lighting variations and generates a descriptor for each point based on its local neighborhood. These descriptors are used later to detect correspondences across the photos. This is similar to the well known SIFT approach, but uses different algorithms for a little bit higher alignment quality.
6 カメラの自己位置と向きを推定するために利用した、Structure from Motion (SfM) の仕組みについてより詳しく知りたい。よい参考文献はないか?
Multiple View Geometry in Computer Vision が有名。
7 カメラの内部パラメータは、訓練と推論で同一である必要はあるのか?
ない。推論に使うときの内部パラメータさえ、定めることができれば、各画素に対する光線が定義でき、それにより、サンプリングする点の座標も求められる。
実際に、LumaAIでは、新規でレンダリングする際の焦点距離を以下のように変更することができる。

8 NeRFにおいては、入力する値に対して、Positonal Encodingが施されているが、これはChat GPT (Generative Pre-trained Transformer) などで利用されている、transfomerのような要素はあるのか?
ない。自然言語処理などで利用されるTransformerは、入力に対して、離れた場所の単語であってもうまくそれらの関連性などを重みづけさせるために利用されている。一方で、NeRFにおけるPositonal Encoderは、モデルの学習をやりやすくさせるために、sinやcosを利用して入力を変換している。
A similar mapping is used in the popular Transformer architecture [47], where it is referred to as a positional encoding. However, Transformers use it for a different goal of providing the discrete positions of tokens in a sequence as input to an architecture that does not contain any notion of order. In contrast, we use these functions to map continuous input coordinates into a higher dimensional space to enable our MLP to more easily approximate a higher frequency function. Concurrent work on a related problem of modeling 3D protein structure from projections [51] also utilizes a similar input coordinate mapping.
9 SfMにおいて、入力の画像どうしで、特徴点のマッチングを行う必要があると書いていた。ここではRANSACアルゴリズムが利用されていたが、動画中の物体追跡などで利用される、Kanade-Lucas-Tomasi (KLT) アルゴリズムなどでもよいのではないか?
それぞれの画像が少ししか違っていない場合はそれでもよいかもしれないが、基本的に、SfMに利用する画像は違う角度や一定数離れている場合が多く、それらの場合は、KLTでは追跡しきることが難しい。その場合、SURF特徴量とRANSACを組み合わせることが望ましい。
10 NeRFから3次元構造を出力する場合、メッシュモデルと点群、どちらが出力されるのか?
点群である。この点群に対して、マーチングキューブ法などを利用して、メッシュ化している。
11 Positonal Encodingでは、入力をsinとcosを利用して変換しているが、y=xとしたときのフーリエ級数展開をしていることと等しいのか?
そうではない。論文中では、入力を-1から1に正規化して使うとある。そのため -π ≦ x ≦ π の区間に入力は収まり、y = x をフーリエ級数展開する。y = xは奇関数であり、cosの成分は0になる。時進めると以下のような結果が得られる。
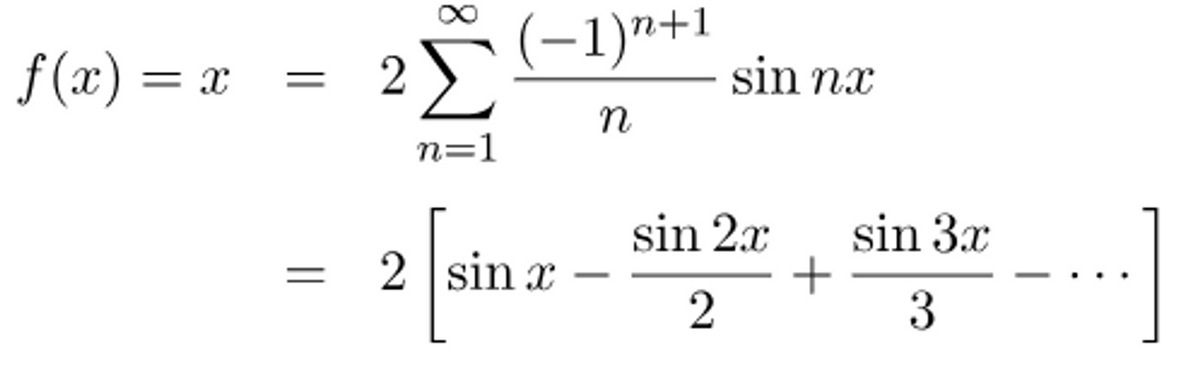
上の画像はこちらのサイトから取得させていただきました。
一方で、NeRFの論文中では、以下の式が利用されている。
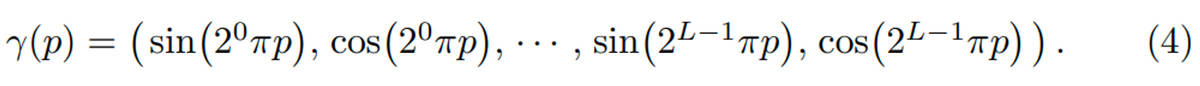
ただ、点の座標を式(4)で変換するのではなく、フーリエ級数展開の結果を利用して、入力するほうが精度がよくなる、とかはないのか?
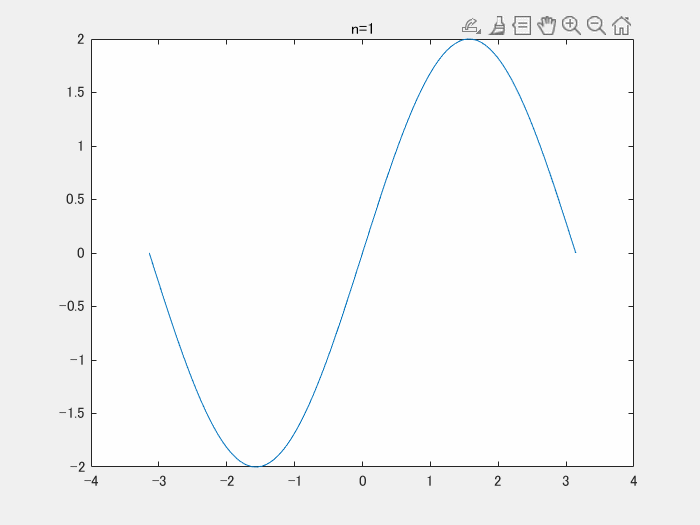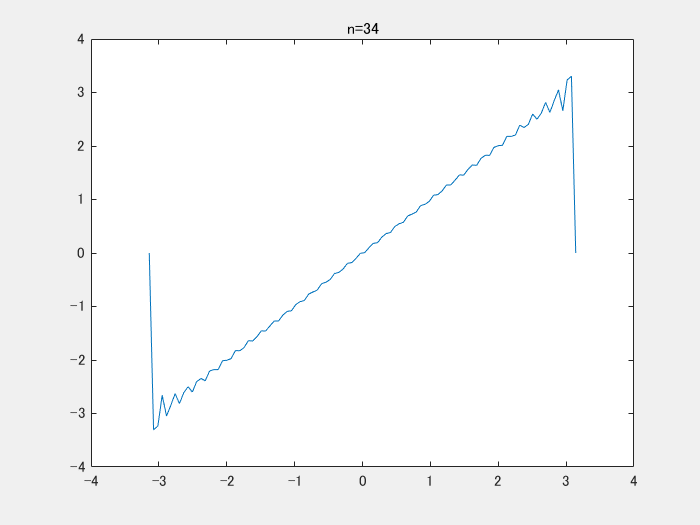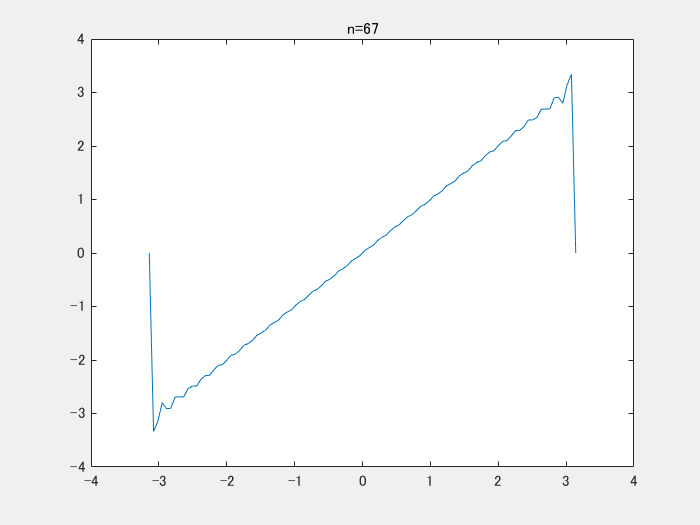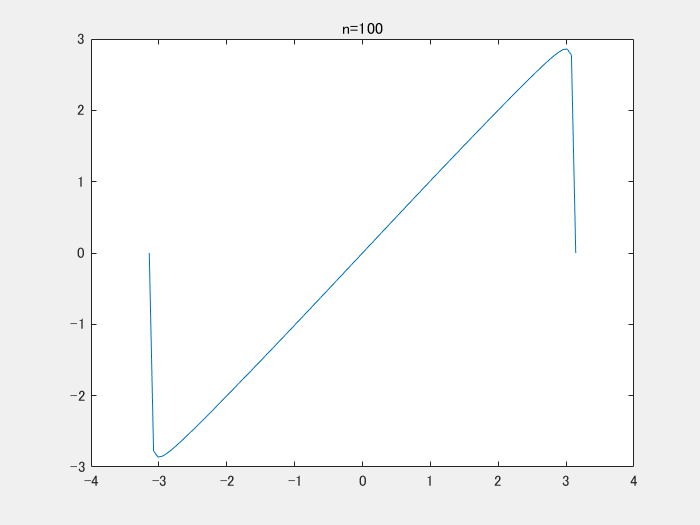
以下の動画は、y = x をフーリエ級数展開をして、足し合わせたときの結果です。どんどんy = x に近づいていることがわかります。
上の動画を作成するコードです。
clear;clc;close all numIter = 100; x = linspace(-pi,pi,100); y = zeros(1,numel(x)); figure; filename = 'demo.gif'; for i = 1:numIter yi = 2*sin(i*x)*(-1)^(i+1)./i; y = y+yi; plot(x,y);title(sprintf('n=%d',i)) drawnow;pause(0.1) frame = getframe(1); im = frame2im(frame); [imind,cm] = rgb2ind(im,256); if i == 1 imwrite(imind,cm,filename,'gif', 'Loopcount',inf); else imwrite(imind,cm,filename,'gif','WriteMode','append'); end end
12 COLMAPの他に無料でSfMを試すことのできるソフトウェアはあるか
たくさんある。 詳しくはそれぞれの名前で検索してほしい。
- OpenSfm
- OpenDronemap
- Regard3D
OpenDroneMapに関しては、使い方に関する記事を書いたのでぜひご覧ください。
13 NeRFを利用したアプリ(LumaAI)のほかに、iPhone LiDARのアプリも多く存在する。どちらもスマホで簡単に3Dモデルを取得できるが、どのように使い分けるとよいか?
映えるような、任意の視点からの動画を撮りたい場合は、LumaAIを使い、実際に3Dとして取得して、長さや面積、体積などを計測したい場合は、iPhone LiDAR のアプリを利用したらよいのではないか。
NeRFの特徴としては、任意の視点からの動画を作成できるということである。そのため、対象の空間の魅力を最大限に生かした見せ方ができると思われる。しかし、食べ物などの小さな物体であれば、一部の白や反射の多い物体を除き、iPhone LiDARでもキレイにスキャンでき、かつ映える動画も作成可能である。また、実際にメッシュモデルなどのモデルとして出力したい場合は、直接的に対象の3次元構造を取得しているiPhone LiDARのほうが使いやすい印象がある。
しかし様々なユースケースがあり、それぞれの特性を理解して、適宜使い分けることが望ましい。
14 iPhone LiDARを使ったことがない。どのようなものかわかる資料はないか?
以下の資料でiPhone LiDARでスキャンしたときの様子や結果を紹介している。
15 本記事では、はじめにカメラキャリブレーションにより内部パラメータを求めていた。その工程はスキップできないのか。実際、LumaAIでは、そのような操作はないし、任意の動画もアップロードできるが?
LumaAIはiPhone上で利用するため、そのiPhoneのカメラで撮影する場合は、そのカメラの機種からカメラの内部パラメータを読み込んでいるのかもしれない。
しかし、ICCV21の Self-Calibrating Neural Radiance Fields では、カメラの内部パラメータも同時にアルゴリズム中で求められる方法を提案している。
最後に
非常に長い記事になりましたが、ここまで読んでくださり、ありがとうございました。本記事は、私がNeRFの論文を読んで、勉強した時のまとめであり、わかりにくいところや不十分なところ、厳密ではないところがあったかと思います。しかし、この記事が、NeRFなどの(3D)コンピュータービジョン関連のトピックを勉強したい方の手助けになれば幸いです。もし修正・加筆すべき箇所があれば教えていただけますと幸いです。できるかぎり更新に努めたいと思います。
サポートベクトルマシン(SVM)を簡単に、わかりやすく説明したい
この記事は、MATLABアドベントカレンダー(その2)の12日目の記事として書かれています。
1 はじめに
本記事では、サポートベクトルマシン(Support Vector Machine: SVM)の仕組みについてまとめます。
サポートベクトルマシンは複数の次元を有するデータを超平面で分離する手法として有名です。色々な場面で利用でき、機械学習の代表的な手法の1つ言えます。以下の図は、3つの変数をもつデータを2つのクラスに分類しているときの図です。各軸が、それぞれの変数に対応しています。また、赤色の局面(超平面)によって、2つのクラスに分類されます。この図は3変数の場合を示していますが、これがより多くの変数の数(次元)になっても問題ありません。このように2つのクラスを超平面(曲面)でうまく分類できると非常に便利そうで、かつおもしろいです。本記事では、このサポートベクトルマシンがどのように計算されるのかを紹介したいと思います。
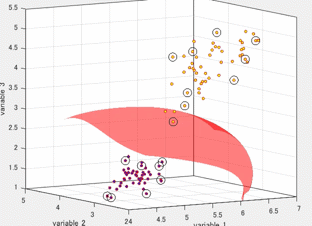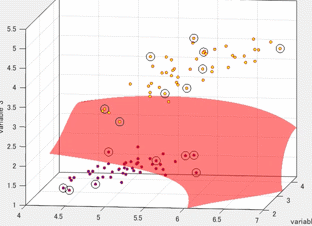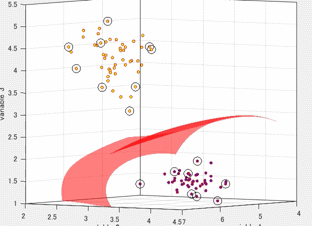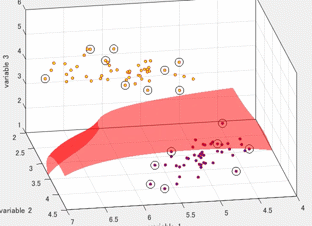
このサポートベクトルマシンの分離平面を可視化するためのコード (Python、MATLAB)は以下のブログやfile exchangeにて公開しています。もしよろしければ、こちらもご覧ください。
過去の記事:サポートベクターマシン(SVM)の分離平面の可視化 (Python, MATLAB)
File Exchange: Visualizing a hyper-plane in SVM classifier(SVMの分離境界面の可視化)
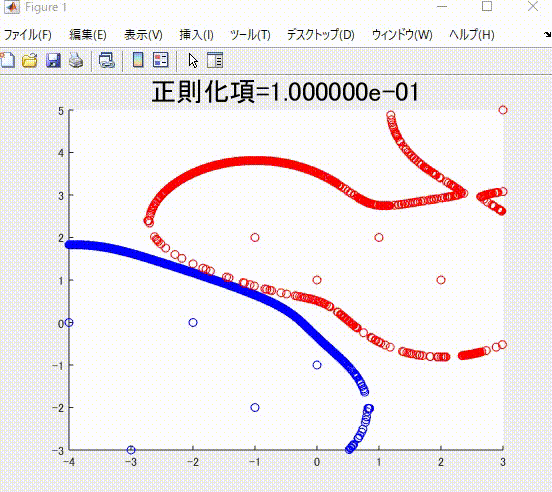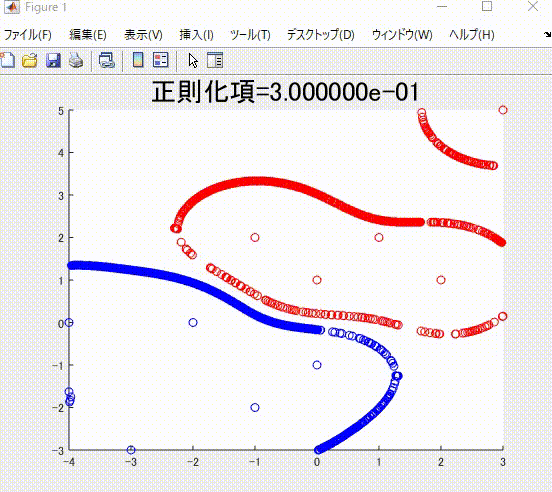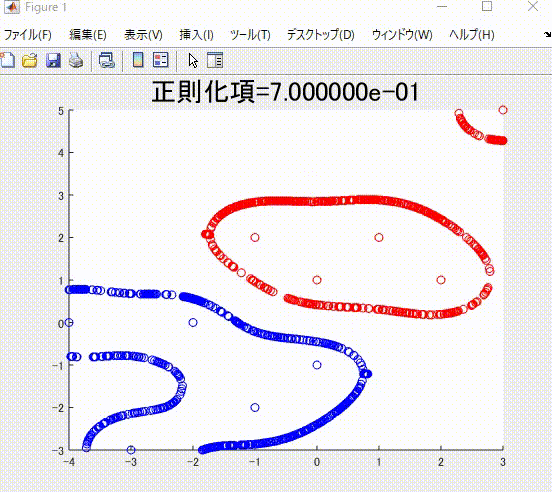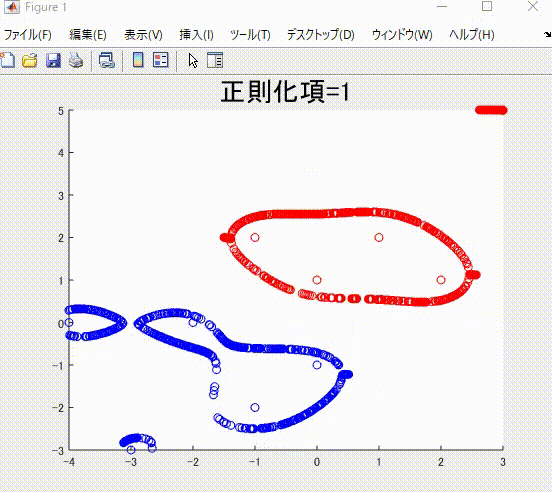
また、本記事を執筆するにあたり、私の理解に基づき、2クラス分類のサポートベクトルマシンを1から実装し(ただしかなりおおばっぱな実装です)、以下のようなそれらしい結果を得ることができました。赤丸と青丸がそれぞれ異なるクラスに属するサンプルで、赤線と青線がそれぞれを分類(分離)する境界です。赤色および青色のサンプルはそれぞれ、同じ色の境界で囲まれていて、うまく分類ができていそうです。
下の図は、本記事で説明する、正則化項の値を値を変えながら学習した時の、境界です。
また、下の図は、ガウシアンカーネルのパラメータを変化させながら学習させたときの境界になります。
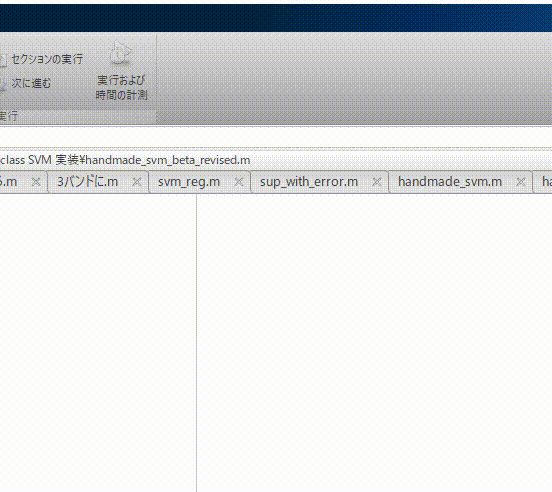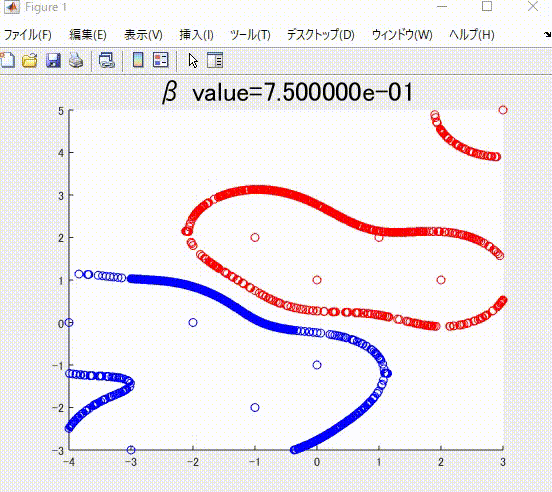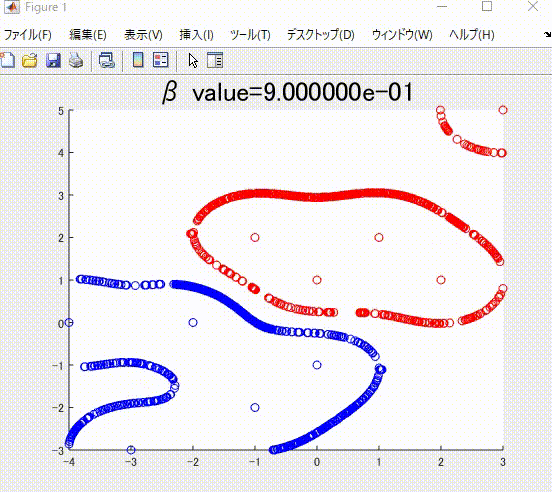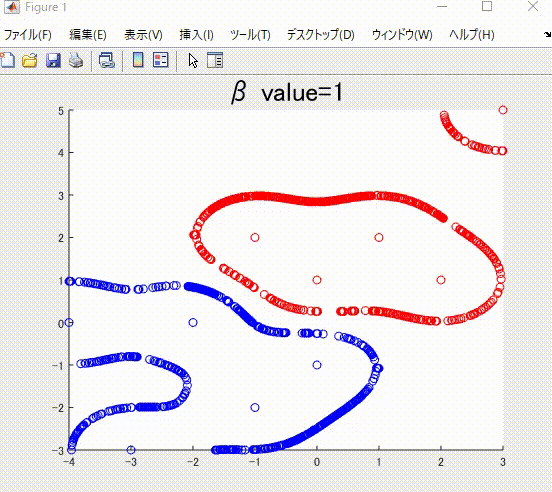
本記事の執筆にあたっては、
赤穂先生の「カーネル多変量解析」を非常に参考にさせていただきました。
非常にわかりやすい書籍であり、大変おすすめです。
注意1:説明する流れについて
サポートベクトルマシンについて説明する方法として、
1) 「マージンの最大化」
2) 「損失関数+正則化項」
といった複数の説明の方法があります。ネットの記事では1で説明するものも多いですが、本記事では、2)のアプローチで説明することを試みます。
注意2: サポートベクトルマシンのという用語について
本記事では、サポートベクトルマシンを2つのクラスに分類するアルゴリズムとして説明しています。多クラスに分類する際の方法も7章にて述べます。
2 サポートベクトルマシンの導入について
まずは、簡単にするために、データの分布と、サポートベクトルマシンの境界を2次元で見てみます。
以下の図を見てください。赤色と青色がそれぞれ異なるクラスに属するサンプルで、x, yがそれぞれのサンプルの持つ変数の値を示します。Boundaryという境界も直線で示されています。この境界の右上が「クラス1」、左下が「クラス-1」を示します。
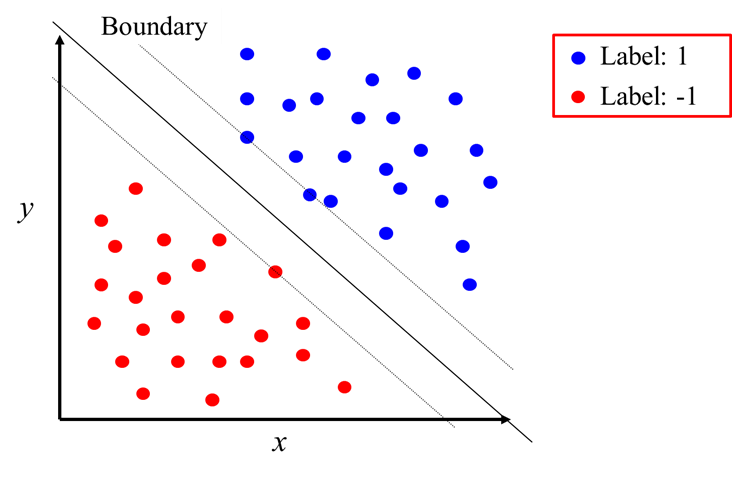
このように、直線や曲線で境界が定義できれば、簡単にクラスの分類ができそうです。ただ、その境界はどのようにして作ればいいのでしょうか。
以下に示す、私の投稿した過去の記事では、線形回帰(単回帰・重回帰分析)の式の重みを解析的に求めていました。
線形回帰(単回帰分析)を1から実装して理解を深めてみよう
線形回帰(単回帰分析)を1から実装して理解を深めてみよう: つづき
重回帰分析の勉強&実装による検算をしてみよう
そこでは、以下のような式を定義して、最小二乗法によって、その係数(最小二乗推定量)を求めました。
...(1)
線形回帰の場合の損失関数は以下のようなものでした。この値が小さいほど、予測の誤差が小さいことを示しています。
...(2)
前回の記事では、正解ラベルyと予測値の値の差分を二乗し、その和を最小にする係数を解析的に計算しました。
今回の、サポートベクトルマシンでは、各サンプルをカテゴリーに分ける(ラベルは1 や -1)ことを目指します。
線形回帰の場合は、誤差は4である、とか、10である、といった値が返され、計算が簡単にできました。
しかし、カテゴリー分けの場合は、その分類が 間違ってる or 正解 の2択になるため、その2乗誤差による評価は直接的に利用することができません。もちろん、ニューラルネットワークのように2乗誤差による評価を利用可能にすることも考えられますが、ひとまず今は以下に述べる方法によって、サポートベクトルマシンの分類の性能を評価します。
sign (sng)を符号関数を利用します。
符号関数については、以下のページがわかりやすかったです。

...(3)
符号関数(以下、sgnと表す)を用いて、サポートベクトルマシンの演算結果が0以上の場合は、1を、0より小さい場合は-1になるようにすることができます。なお、ここでは、演算結果が0の場合も、1を返すようにしています。なお、はサポートベクトルマシンにサンプルを入力した時に利用する関数で、ざっくりいうと、サポートベクトルマシンの中身、といったふうにも言えると思います。
すると、損失関数は以下のように定義することができます。
...(4)
の値は、先ほど述べたように、1か-1でした。yは正解ラベルで同様に1か-1を示します。クラスの名前を与えるとすると、クラスAやクラスBというふうに言い換えることもできます。これにより、サポートベクトルマシンの演算結果が正解の場合、損失は0、そうでない(間違えている)場合は1になることがわかります。具体的な例は後で挙げることにして、ここでは式の整理を進めます。
...(5)
...(6)
(6)式を得たところで、yのパターンと、そのサンプルの推論結果が正しい/間違い場合の、損失関数の値を確かめてみます。yが1/-1の場合と、それぞれで正解/不正解 の場合があるため、4通りの場合が存在します。それぞれについて確認してみます。
が1で
が1 (正解) ⇒
= 0
が1で
が-1 (不正解) ⇒
= 1
が-1で
が-1 (正解) ⇒
= 0
が-1で
が1 (不正解) ⇒
= 1
...(7)
以上のように、それぞれの場合において、正解の時は損失が0、不正解の時は損失が1になっていることがわかります。
このルールで、適切に誤差を評価できそうです。この誤差が0(ゼロ)であれば、そのサンプル(訓練データ)中のミスもゼロとなります。そのため、この誤差をゼロにするような関数 を求めればよいことがわかります。
しかし、(6)式では、凸関数になっていないという問題があります。以下の図を見てください。
凸関数では、「コブ」が1つだけ存在します。一方、凸関数でない関数は、「コブ」が複数存在します。
凸関数の場合は、最適解を求めやすいです。直感的に言うと、右と左を見て、その点が下方向にあれば、その点が最小値を取っていることがわかります。一方、凸関数でない場合は、関数全体の値を見渡し、その中での最小値を探す必要があります。
画像出展:凸関数と凸でない関数
(6)式と似た形で、かつ凸関数の損失関数を用意するために、ヒンジ関数を導入します。
すると、(6)式は以下のように書き換えることができます。
...(8)
(8)式をより具体的にイメージするために、以下の図を見るとわかりやすいと思います。
(8)は b = 0 の場合と考えてください。0との2つの値を比べます。0というのは、サポートベクトルマシンの予測結果が正しい場合です。一方、
の値が採用される場合は、その推論が正しくない場合です。例えば、y = 1 のサンプルに対して、負の値(正しくない)である -10 を返した場合を考えます。この場合、
の値は11となり、
では、11という値が採用されることになります。

画像出展:ヒンジ関数の意味、損失関数として使えることの大雑把な説明 https://mathwords.net/hinge
このを利用すると、(7)は以下のように書き換えることができます。
が1で
が0以上 (正解)⇒
が1で
が0 より小さい(不正解)⇒
が-1で
が0 より小さい (正解)⇒
が-1で
が0以上(不正解)⇒
...(9)
このように、予測が正解の場合は、そして、不正解のときは正の誤差値を返すことがわかります。
3. カーネル関数の利用
前節では、というヒンジ関数を用いた損失関数を定義しました。
多次元の入力に対して、ラベルが1の場合は、0以上、ラベルが-1の場合は、0より小さい値を返すとよい、という設定でした。
非常にシンプルに考えると、以下のような線形回帰(単回帰)のような形でもよさそうです。
...(10)
ここで、以前のブログ記事で、カーネル法による回帰を紹介しました。
カーネル法を利用することで、以下の図のようにグネグネとした曲線を描くことができ、
正則化などを利用しない場合は、サンプル(訓練データ)に完全にフィットする曲線を得ることができるのでした。
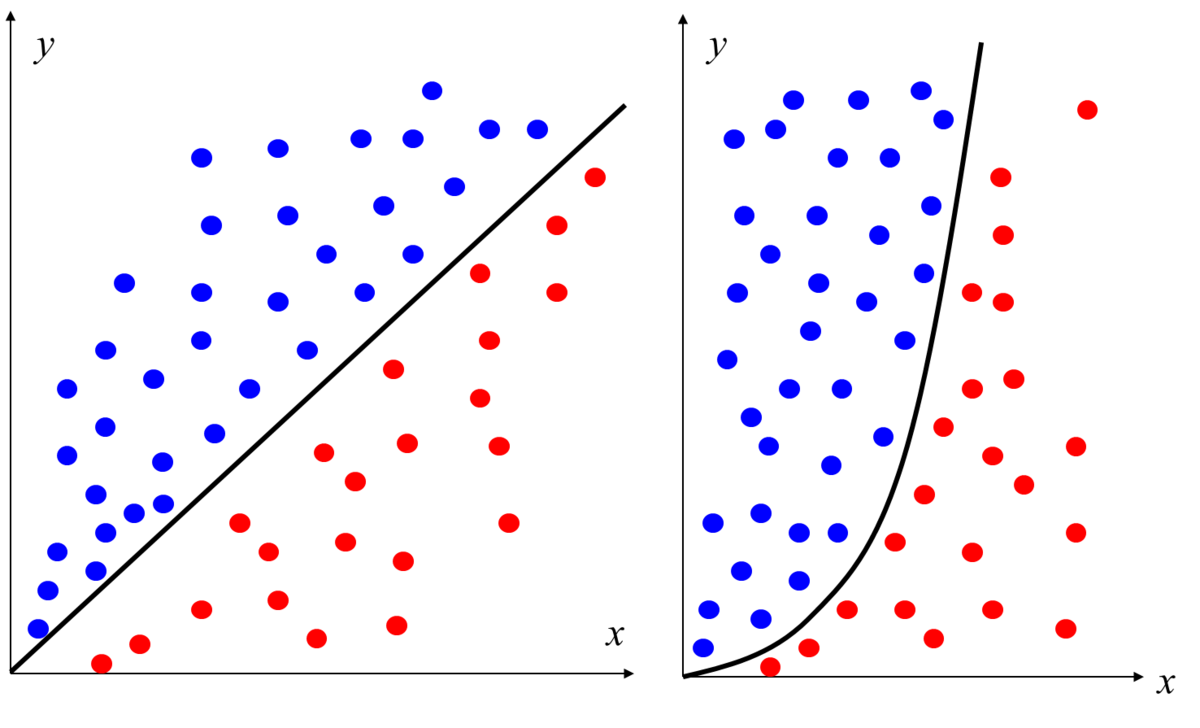
サポートベクトルマシンの場合について考えます。以下の図の左の図が直線で青と赤のクラスを分類しています。
右の図のような場合はどうでしょうか。左の例のように直線ではきれいに分けることができず、図のように曲がった形の分離境界が必要であることがわかります。サポートベクトルマシンの場合でも、このような2次元や多次元のサンプルに対しては、このようなより複雑な分離境界を利用するほうがより高精度な分類が可能になると考えられます。
カーネル法の便利な点として、何らかのモデル式(例:を考える必要はなく、
適切なカーネル関数やグラム行列Kを利用することで、複雑な曲線(曲面)を描くことができるのでした。
グラム行列の内容も以前の記事にて記述しています。
https://kentapt.hatenablog.com/entry/entry/matlabAdventDay11
そこで、を
に読み替え、
を以下のように定義します。
...(11)
また、損失関数は、正則化項を加え、以下のようになります。
...(12)
この正則化項に関しても、以前のブログ記事に詳細の記述があります。
まとめると、この(12)式を最小化する、重み が求めるとよいことがわかります。
そして、予測の際には、
を計算する ⇒ 正(負)なら ラベル1(-1)と分類します。
このように、損失関数や、最適化したい値を決めることができました。次の章では具体的な計算のステップについて考えていきます。
4. サポートベクトルマシンの学習のための具体的な計算
4.1. スラック変数の導入
さきほどの(12)式を解く方法をより簡単にすることを考えます。(12)式中のの値の値に応じて場合分けが生じるため、
最適化の計算が面倒になります。そこで、より式を解きやすくするために、凸二次計画問題 (QP=(convex) quadratic programming) に言い換えることを考えます。線形関数で表された制約条件をみたし,2次の目的関数を最小化する解を求める問題を2次計画問題といい,さらに目的関数が凸関数である場合に凸2次計画問題といいます。
http://www.me.titech.ac.jp/~mizu_lab/lib/pdf/kougisiryou/suuti/handout/11/suuti_kougi11-6.pdf
凸二次計画問題の場合は、既存のライブラリが色々と存在し、比較的簡単に解けるようです。
それでは、凸二次計画問題に言い換えてみます。
の値を(スラック変数)とします。すると、求めるものは、
...(13)
および
...(14)
の両方を満たすの中で、最も小さいものである。
「を満たすもの中での最小値」というのは変に聞こえるかもしれません。
例えば、の値が2以上であれば、上の条件を満たす場合、この「を満たすもの中での最小値」という条件がないと、
は2でも3でも4でも、何であっても満たしてしまうことになります。
このような言い換えをすることで、式(12)の最適化の問題を、凸2次計画問題に持ち込むことができました。
や以下のようなグラム行列
を利用して、
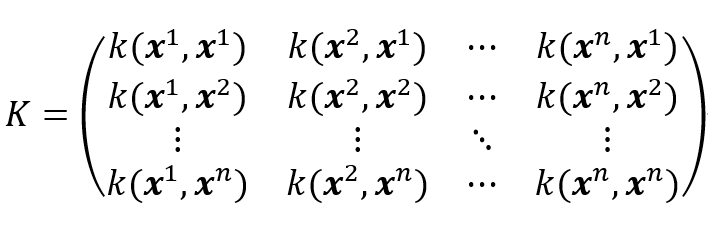
...(15)
(12)式を書き換えると、最適化する2次関数の式は、以下のようになります。
...(16)
4.2. ラグランジュの未定乗数法を用いた凸二次計画問題の求解
本記事では、先ほど求めた、凸二次計画問題を双対問題に帰着させて解いていきます。
式(14)のような制限のもと、式(16)の最小値を求めるには、ラグランジュの未定乗数を利用します。
ラグランジュの未定乗数法は、以下の主成分分析の記事で扱いました。本記事では省略しますが、もし興味がございましたら以下の記事もご覧ください。
ラグランジュ関数は、以下のようになります。
...(17)
ここで、ラグランジュ乗数 および
を導入しました。
について偏微分をします。この値が0となるので、以下の式を得ます。
...(18)
また、グラム行列は対象行列であるため、
...(19)
です。そのため、式(18)は
...(20)
ただし、
...(21)
...(22)
としました。
Kに逆行列が存在する場合、
...(23)
また、について偏微分を行うと、
...(24)
が得られます。
よって、式(23)と(24)を利用すると、式(17)は以下のように変形できます。
...(17を再掲)
を含む項をひとまとめにし、さらに
を代入して、
...(25)
最後の項を整理して、
...(26)
であり、さらに2項目と4項目をまとめることができるため、
...(27)
となります。
また、および、
と
という条件を合わせて、
...(28)
を得ることができます。そのため、の条件下で、
を最大化するを求めればよいことがわかります。グラム行列Kは与えられたサンプル(訓練データ)で計算できます。また、
も正解ラベルのため、既知です。そのため、
のみが未知です。
この凸二次計画問題は、SMO(sequential minimal optimization)と呼ばれるアルゴリズムなどを用いて
解くことができます。本記事では、SMOについては触れず、これらの手順で、を求めたらよいということで本章は終わりにしたいと思います。
4.3. サポートベクトルマシンの計算手順の簡単なまとめ
比較的シンプルな式(27)を得ることができました。これにより、サポートベクトルマシンの計算において、どのような手順を踏めばよいかわかりました。
1) (訓練データとして)与えられたサンプル から
までの値を用いて、カーネル法で用いるグラム行列
を計算する
2) 式(27)をという条件下で最適化するパラメータ
を求める
3) 式(23)のに
の値を代入し、
の値を求める
4) 式(11)のという値を求める(ここでは、テストしたいデータを推論している)
5) この値が0以上であれば、クラスA、そうでなければクラスBというふうに、分類を行うことができる
5. サポートベクトルについて
4章にて、具体的なサポートベクトルマシンの学習に必要な計算について述べました。それでは、サポートベクトルマシンの名前の中の、「サポートベクトル」とは何のことでしょうか。さらに、式(27)を見ると、グラム行列Kを計算していますが、それはサンプル数×サンプル数の形をしているため、訓練データが増えれば増えるほど、非常に大きなデータになってしまいます。それでは、運用上大変になりそうです。
(17)式のに関して偏微分を行います。この値は0になるので、
のとき、
...(29)
が成り立ちます。
厳密には、カルーシューキューンータッカー (Karush-Kuhn-Tucker) 定理について触れる必要がありそうですが、ひとまずここでは、ざっくりとした議論を進めます。
式(23)のから、
のときは
となることがわかります。
つまり、となるのは、
の場合に限られます。
よって、サポートベクトルマシンの計算においては、以下のヒンジ関数の図の、
折れ線の折れている点か、その左側の点のみを利用すればよいことになります。
また、右側の点は、サポートベクトルマシンの計算では登場しません。
そのため、サポートベクトルマシンの計算では、全体のサンプルが使われるわけではなく、
一部の点のみを保持すればよいことになります(スパース性)。一般には、サポートベクターは、もとの訓練サンプル数に比べてかなり少ないと言われています(栗田先生 サポートベクターマシン入門)。

6. マージン最大化について
冒頭でも述べた通り、サポートベクトルマシンを説明する場合、「マージン最大化」が利用される場合も多いです。
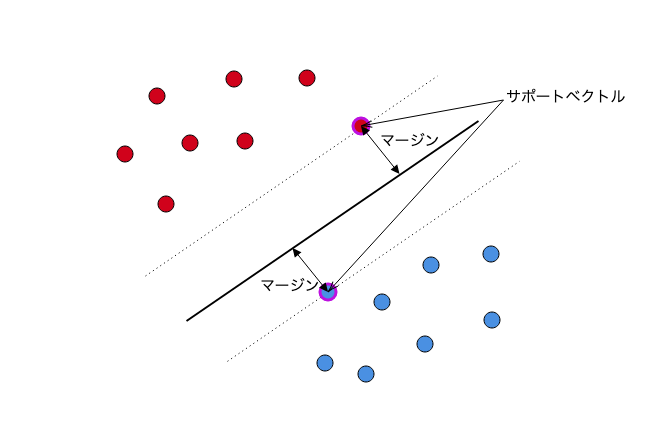
赤と青のサンプルを「スパっと」わける超平面を想定し、その超平面と赤と青のサンプル(のうち最も近いもの)の距離を
最大化しようという考え方です。
図出展:最初に学ぶ 2分類SVMモデルの基本 www.acceluniverse.com
そして、その文脈において、以下の図のように、直線や曲面で分けられない時は、
カーネル法を利用しながら、別の特徴空間にサンプルの写像をして、その特徴空間上で、線形分離をする。そうすると、以下のようなサンプルに対してもうまく分類を行うことができる、といったような説明がよくあると思います(図の出展のブログでは別の例を使ってわかりやすく説明されていました)。個人的には、サポートベクトルマシンをはじめて知ったときは、この説明はわかりやすいものの、実際の計算が想像しにくいという印象でした。しかし、本記事のような、「損失関数と正則化項の最適化」というアプローチを知ったうえでもう一度見てみると、より具体的に想像ができる気がしました。

図出展:最初に学ぶ 2分類SVMモデルの基本
そこで、今回の説明では採用しなかった、マージン最大化という観点で考えてみたいと思います。
簡単に、マージン最大化をもとに、サポートベクトルマシンを説明してみます。
以下は、冒頭で掲載した図を少し変更したものです。四角の点がそれぞれサポートベクターを示しています。

超平面の式をとし、各サンプルの値(特徴ベクトル)を
とすると、
超平面と、そのサンプルの距離は
...(30)
で表すことができます。
さて、冒頭の
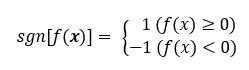
に合わせて、
の値が1より大きい場合は、ラベル1、
小さい場合はラベル-1を割り当てるとします。(こうなるようにωの値を等倍してうまく選ぶようにします)
このとき、式(30)で定義される、分離境界(超平面)と訓練データのサンプルの距離の最小値は、
のときの、
...(31)
となることがわかります。
このマージンを最大化する、を、別の言い方で表現すると、この式の逆数の二乗である、を最小化することになります。
この状態では、すべての点をうまく分類するための、超平面を作成することを念頭に置いています。
しかし、カーネル法による回帰の記事にもあったように、外れ値に対しても敏感に反応する超平面を作成すると、
他のデータに対して対応できない(過学習)ものになってしまいます。
そのため、誤分類を許さない今回の想定(ハードマージン)ではなく、いくつかの誤分類は許容し(ソフトマージン)、より滑らかな超平面を作成するために、正則化項に相当するものを追加します。
式(14)のスラック変数と同様に、
...(32)
という制約を設けて、
...(33)
を満たす、ωを見つければよいことになります。λは、誤分類が発生した時に加えるペナルティ項の係数(正則化項の係数)です。
ここで、
...(34)
と置くと、
...(35)
となります。
4.1で述べた、最小化する損失関数は以下のようになっていました。
...(16の再掲)
式(33)を式(35)を利用して変形すると、
...(36)
となり、とすれば
4章で示した方法と、等価な式を得ることができました。
このように、「損失関数+正則化項」を最小化する枠組みで説明した場合でも、「マージンの最大化」を考えた場合も、同じ計算をしていることになります。おもしろいですね。
7. 複数クラスの分類について
これまで述べてきたように、サポートベクトルマシンは2つのクラスの分類に利用可能です。しかし、3つ以上のクラスに分類したい場合も多く存在します。
多クラスの分類として知られている方法の例を挙げます。
- one vs all (1対他方式)
- one vs one (1対1方式)
- 誤り訂正出力符号
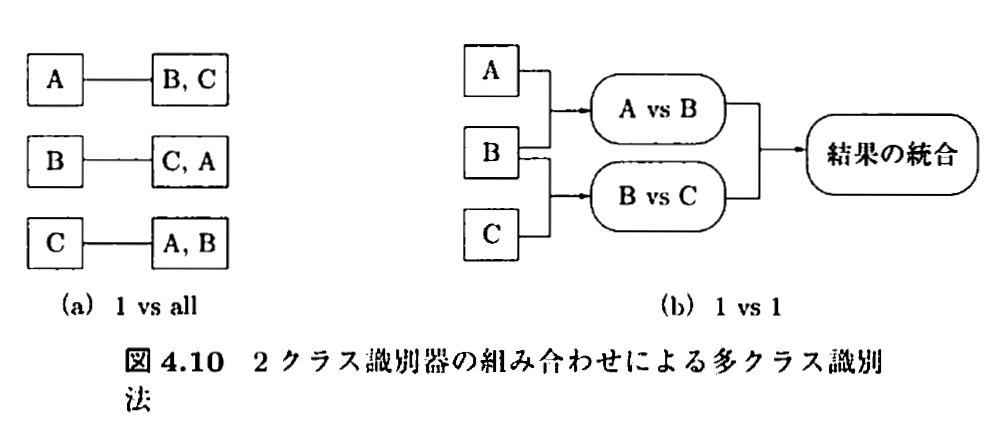
図出展:カーネル多変量解析 p.119
7.1. one vs all (1対他方式)について
上図の(a)にあるように、各クラスとその他のクラス、という分類器をそれぞれ用意します。
利点
- シンプルでわかりやすい。
欠点
- 全ての分類器で、all側になる場合や、複数のパターンで、one側になる(1つの分類器だけ、そのクラスを支持してくれると嬉しいがそうならない場合が多い。分離境界までの距離を基準にすることも考えられるが、サンプル数がクラス間で異なっていたりすると、フェアに判断することが難しくなる。)
- クラス間のサンプル数が不均衡である場合、学習が難しくなる。
7.2. one vs vs one (1対1方式)について
上図の(b)にあるように、1クラスどうしを比較するように、学習器をたくさん用意する。
利点
- one vs allのようなサンプル数が不均衡である場合でも対応しやすくなる。
欠点
- クラスの数が増えるに従い、用意すべき学習器の数が膨大になる。
7.3. 誤り訂正出力符号を用いた方法
詳しくは以下のサイトをご覧ください。
朱鷺の杜Wiki 誤り訂正出力符号
サポートベクトルマシンの多クラス分類への適用
https://deus-ex-machina-ism.com/?p=23045
8. MATLABでのパラメータ設定を見てみよう
サポートベクトルマシンの仕組みや、そこで必要な設定値をまとめてきました。実際に、サポートベクトルマシンを実行するときに、以上のパラメータ調整が可能であることを確認していきます。
今回は、ドキュメントが充実している、MATLABを例に考えます。以下に、主要なものを挙げます。
以下のドキュメントを参照します。
fitcsvm関数
2クラスの分類、または、1クラス (one-class SVM。本記事では、紹介しません)の分類に利用可能なサポートベクトルマシンの関数。
https://jp.mathworks.com/help/stats/fitcsvm.html
fitcecoc関数
「サポートベクターマシンまたはその他の分類器向けのマルチクラス モデルの近似」
https://jp.mathworks.com/help/stats/fitcecoc.html
8.1. ボックス制約

以下のような説明があります。
ボックス制約は、マージンに違反している観測値に課せられる最大ペナルティを制御するパラメーターであり、過適合の防止 (正則化) に役立ちます。ボックス制約の値を大きくすると、SVM 分類器が割り当てるサポート ベクターは少なくなります。ただし、ボックス制約の値を大きくすると、学習時間が長くなる場合があります。
式(12)で導入した、正則化項の係数であると思われます。これを大きくすることで、過適合(overfitting)を防ぐことができますが、同時に、分離境界の超平面が滑らかになりすぎて、認識能力が下がる可能性もあるのでうまくバランスをとる必要があります。
8.2. カーネル関数
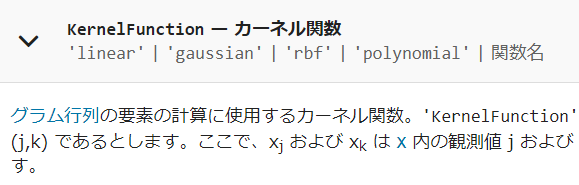
式(11)で導入した、カーネル関数の中身のことです。再掲になりますが、以前のカーネル関数の記事もご覧ください。i番目とj番目のサンプルを何らかのルールで計算させてグラム行列を作るのでした。私のブログ記事では、ガウシアンカーネルを利用していました。線形カーネル、多項式カーネル、カスタマイズしたカーネルなど、色々と利用が可能です。
8.3. カーネル関数のスケール
上の過去のブログ記事でも、ガウシアンカーネルのパラメータについて記述していました。
上の記事では、式3-1に相当する内容です。
例えば、ガウシアンカーネルを以下のように設定したとします。
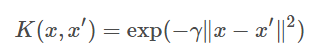
その場合は、以下のように設定するとよいそうです。
mdlSVM = fitcsvm(..., 'KernelScale', 1/sqrt(gamma));
出展:MATLAB answers "Gaussian kernel scale for RBF SVM"
https://jp.mathworks.com/matlabcentral/answers/328796-gaussian-kernel-scale-for-rbf-svm
8.4. 最適化ルーチン
式(28)周辺で、の条件下で、
を最大化するを求めるという、凸二次計画問題を解けばよい、ということを示しました。
本文中で説明した、SMOに加え、他のアルゴリズムも利用可能です。
8.5. キャッシュサイズ
カーネル法の際に用いる、グラム行列Kは、サンプルの数が多くなればなるほど、2乗のスケールで大きくなり、計算が大変そうだという、話をしていました。サポートベクトルマシンの計算をする際に、確保するメモリサイズに関するパラメータだと思います。

8.6. 多クラス分類をする際の方式
7章で述べたような、本来2クラスの分類に利用可能なサポートベクトルマシンを用いて、多クラスの分類をする際の方式です。上で述べた、one vs oneやone vs allに加えて、色々な方式が利用可能です。

8.7. Standarize
入力データを標準化する/しないを設定するもの。

8.8. 誤分類のコスト
例えば、AというものをBと間違えてしまった時のコスト(ペナルティ)の値を制御します。例えば、犬と猫を見分ける場合を考えます。訓練データ内に犬が90匹、猫が10匹存在するとします。その場合、学習せずとも、「全て犬である」と答えると精度は90%になってしまいます。このようなクラス間でデータ数が不均衡である場合などに、このコストを調整するといいと思われます。例えば、猫なのに、犬と訓練すると、非常に大きなペナルティ(損失)を与えるようにします。簡単にするために、クラス数の逆比を用いて、猫を犬と判断した場合に、9倍のペナルティを与えるようにすると、このような「全て犬という」事態はさけられそうです。

9. まとめ
かなり長くなりましたが、ここまで読んでいただき誠にありがとうございました。本記事では、
- サポートベクトルマシンの概要と、その学習時の計算について説明を行いました。
- 損失関数と正則化項の最適化に焦点を当てて、サポートベクトルマシンの計算方法について述べました
- 別の切り口である、「マージン最大化」で説明を行っても、等価な数式に帰着することを述べました
- MATLABを例に、ソフトウェアで実行するときのパラメータについて述べました
- この記事が、サポートベクトルマシンを理解するうえでのきっかけとなれば幸いです。
注意点としては、
- 学習の基本的なところは、単回帰や、重回帰に関する過去の記事でカバーしていますのでそちらもご覧ください。
- カーネル法に関しても、過去のカーネル法による回帰の記事でカバーしていますのでそちらもご覧ください。
- 筆者も細部については、勉強中のところが多く、わかりにくかったり、修正すべき点があるかもしれません。その場合は教えていただけますと幸いです。
参考文献
「カーネル多変量解析」赤穂昭太郎先生
「サポートベクターマシン」 赤穂昭太郎先生 https://www.ism.ac.jp/~fukumizu/ISM_lecture_2006/svm-ism.pdf
「サポートベクターマシン入門」栗田多喜夫先生 https://home.hiroshima-u.ac.jp/tkurita/lecture/svm.pdf
不等式条件下におけるラグランジュの未定乗数法
SVMの2次計画問題に関する解法の考察
http://numaf.net/Z9/Z9a/html/THESIS/H15/abst_toda.pdf
サポートベクターマシンとは[ソフトマージンサポートベクターマシン]
最初に学ぶ 2分類SVMモデルの基本
本文中に参考文献としての記載のあるものは、ここでは一部省略しています。
重回帰分析の勉強&実装による検算をしてみよう
この記事は、MATLABアドベントカレンダー(その2)の6日目の記事として書かれています。
1 はじめに
前回の記事では、1つの変数のみで、線形回帰(単回帰)を行うときの、数式の導出や自身の実装による検算を行いました。
線形回帰(単回帰分析)を1から実装して理解を深めてみよう
線形回帰(単回帰分析)を1から実装して理解を深めてみよう: つづき
そこでは、y = ax + bという非常にシンプルな場合を扱いました。
今回は、
といったような、変数の数を増やした場合について考えたいと思います。
そこで、本記事では、変数の数を増やして線形回帰(重回帰分析)をしたときの、計算方法について簡単にまとめます。さらに、MATLABを用いてコーディングをし、ここでの理解による実装の結果と、MATLABのregress関数の結果が一致することを確かめます。本記事は、タイプミスや間違いなどがあるかもしれません。その場合教えていただけますと幸いです。また、本記事は、前回の記事をもとに、執筆をしており、説明が比較的少なくなっています。もしよろしければ、先述した前回の記事も見ていただけますと幸いです。
また、本記事の原稿や用いたコードは以下のページにアップロードされています。
本記事の執筆においては、以下の資料が非常に参考になりました。
回帰分析(重回帰) http://fs1.law.keio.ac.jp/~aso/ecnm/pp/reg2.pdf
2 重回帰分析について
重回帰モデル (multiple regression model) とは、単回帰とは異なり、説明変数が複数ある回帰モデルのことです。
モデル式は、線形回帰に変数をさらに加えて以下のようになります。
...(1)
単回帰のときと同様に、誤差を2乗して、足したもの(残差平方和)を求めます。

...(2)
前回の記事と同様に、各変数で偏微分を行います。
のようにおいて、合成関数の微分を行っています。
aおよびに対して、偏微分を行った時の式を以下に記述します。
...(3)
yを左辺に移動させて、両辺を-2で割り、整理すると以下のようになります。
この式を正規方程式(normal equation)と呼びます。
...(4)
なお,変数の数が1つの単回帰の場合については,(4)の最初の方程式を他の方程式に代入することで、連立方程式を解くことができました。しかし、変数が多くなると、このように解析に解くことは非常に困難です。そこで行列を用いて解いていきます。
(4)の左辺を行列式で表すと以下のようになります。
...(5)
なお、 はi番目のサンプルのyの値を示し、
は、k番目の変数のl番目の値を示しています。
また、
と置いています。
さらに、(4)の右辺を行列式で表します。
...(6)
(6)のようにきれいな形で表すことができました。
さらに、(6)の式をXを用いて表すと、以下のようになります。
...(7)
(4)の左辺は(5)で、(4)の右辺は(6)のようになりました。
そこで、それらを合わせて、
...(8)
となります。
の逆行列が存在すれば、
..(9)
となり、係数の値(最小二乗推定量)を得ることができました。
3 回帰直線がサンプルの平均を通ることの確認
単回帰分析の記事で、回帰直線がサンプルの平均を通ることを示しました。
重回帰分析でも同様です。
(4)の1つ目の式で以下のことが示されていました。
この式をサンプル数nで割ると、以下の式を得ることができます。
...(10)
なお、yの平均を、xの平均を
としています。
この式から、回帰直線は、必ずサンプルの平均(重心)点を通ることがわかります。
また、単回帰分析の場合と同様に、残差の和は0であることや、残差ベクトルとが説明変数xは直交することも導くことができます。
4 重回帰分析を自分で実装して検算してみよう
3章まででまとめた重回帰分析に対する理解が正しいことを確認するために、4章では、自分で重回帰分析を実装します。まずは、MATLABを用いて計算し、さらに自分の手で実装します。そして、それらの結果が一致することを確認します。
4.1. MATLABのfitlm関数による計算
はじめに、MATLABの関数を用いて、重回帰分析を計算します。carsmallデータをロードし、さらに、fitlm関数を利用します。
load carsmall X = [Weight,Horsepower,Acceleration]; % fitlm を使用して、線形回帰モデルを当てはめます。 mdl = fitlm(X,MPG)
mdl =
線形回帰モデル:
y ~ 1 + x1 + x2 + x3
推定された係数:
Estimate SE tStat pValue
__________ _________ _________ __________
(Intercept) 47.977 3.8785 12.37 4.8957e-21
x1 -0.0065416 0.0011274 -5.8023 9.8742e-08
x2 -0.042943 0.024313 -1.7663 0.08078
x3 -0.011583 0.19333 -0.059913 0.95236
観測数: 93、誤差の自由度: 89
平方根平均二乗誤差: 4.09
決定係数: 0.752、自由度調整済み決定係数: 0.744
F 統計量 - 定数モデルとの比較: 90、p 値は 7.38e-27 です
このように、切片47.977、および、各変数の係数を得ることができました。
4.2. 自分の手で実装してみる
Xは以下のように定義されました。
縦に、サンプル、横に変数が並んでいて、データセットと同じ形をしています。そのため、
一番左の列に1を足すだけでよく、以下のようにするとXを定義できます。
validIdx = ~isnan(MPG)&~isnan(X(:,2)); X = X(validIdx,:); MPG = MPG(validIdx); myX = [ones(size(X,1),1),X];
さらに、重回帰分析の式は以下のように解くことができることがわかりました。
さきほどのXと合わせて、以下のように計算できます。
b = inv(myX'*myX)*myX'*MPG
b = 4x1 47.9768 -0.0065 -0.0429 -0.0116
すると、4.1と同じ結果を得ることができました。
4.3. 重回帰分析を3次元プロットする
4.2では3変数を利用しましたが、次は、2変数のみを利用し、その結果を3次元プロットします。
以下のページを参考にしています。
https://jp.mathworks.com/help/stats/regress.html
load carsmall x1 = Weight; x2 = Horsepower; % Contains NaN data y = MPG; % X = [ones(size(x1)) x1 x2]; b = regress(y,X)
b = 3x1 47.7694 -0.0066 -0.0420
scatter3(x1,x2,y,'filled') hold on x1fit = min(x1):100:max(x1); x2fit = min(x2):10:max(x2); [X1FIT,X2FIT] = meshgrid(x1fit,x2fit); YFIT = b(1) + b(2)*X1FIT + b(3)*X2FIT; mesh(X1FIT,X2FIT,YFIT) xlabel('Weight') ylabel('Horsepower') zlabel('MPG') view(50,10) hold off

上の図のように、説明変数をx、y軸とし、目的変数をz軸としてプロットすることができました。
5 まとめ
本記事では、重回帰分析について簡単にまとめました。行列式を用いることで、単回帰と同じ流れで簡単に導出することができました。さらに、MATLABでも実装し、自身の理解が正しいことを確認できました。
今回は、具体的な利用については述べませんでした。重回帰分析は様々な変数を入れることができるため、便利です。しかし多重共線性などについても考慮しながら、うまく運用することが重要です。今後も引き続き勉強し、うまくこのようなモデルを扱えるようになりたいです。
多重共線性への対応として、主成分分析を利用することも考えられます。主成分分析により、各変数を無相関化することができます。主成分分析については、以下の記事をご覧ください。
参考文献(本文中に記載のないもの)
Albertさま データ分析基礎知識サイト
丹羽時彦さま 放課後の数学入門
MATLABドキュメンテーション fitlm
iPhone LiDARで取得した3次元点群の境界を書き出してみよう
この記事は、MATLABアドベントカレンダー22日目の記事として書かれています。
この記事の前編として以下の記事も投稿しています。ぜひご覧ください。
この記事では、iPhone LiDARで取得した3次元点群をMATLABにて読み込み、さらに、その領域の境界のデータをKMLファイルとして出力する方法を紹介します。言語はMATLABを使用します。
3次元点群を取得するためのアプリは3D Scanner Appを用いました。
詳しい使い方は、以下の記事がわかりやすかったです。
また、以下の記事でもこちらのアプリの使い方を紹介しています。
ここでは、すでにiPad LiDARにて計測し、PCに転送した状態から始めます。
なお、ここで用いたコードや、点群ファイルは以下のページにアップロードされています。
点群ファイルの読み込み
LiDAR toolboxの機能を用いて、点群データの読み込みを行います。以下のように、lasFileReaderやreadPointCloud関数を用いて、簡単に点群ファイルを読み込むことができます。まずは、GPS情報を有した点群(LAS)ファイルをそのまま読み込み、表示してみます。なお、上のgithubのページでは、ファイルサイズを小さくするため、サンプルファイルのファイル形式をLAZ形式に圧縮してアップロードしています。(3D Scanner Appでは、LAS形式で点群がエキスポートされます。)MATLABに読み込む方法などは変わりません。
clear;clc;close all % las/lazファイルを読み込むためのlasFileReader objectを作成する lasReader = lasFileReader('sample.laz'); % las/lazファイルの、xyzおよび色情報を読み込み ptCloud = readPointCloud(lasReader); % 可視化 figure;pcshow(ptCloud)

しかし、単に読み込むだけでは、このように、うまく表示できません。2022年12月現在、3D Scanner Appから、Geo-referenceされた(位置情報を持っている)LASファイルをエキスポートすると、その座標は経度・緯度の値を持っています。経度緯度の値は、小数点以下の数が非常に多く、単にビューワーに読み込むだけではうまく行かない場合も多いです。
座標系の変換
geocrsオブジェクトの作成
MATLABのpcshow関数で点群を閲覧するために、経度緯度のxy座標を投影座標に変換します。
% geojcrsオブジェクトを作成する geocrs4326 = geocrs(4326);
ここで、作成した、geocrsオブジェクトの中身について確認します。
% 確認のため、geocrsを表示
disp(geocrs4326)
geocrs のプロパティ:
Name: "WGS 84"
Datum: "World Geodetic System 1984"
Spheroid: [1x1 referenceEllipsoid]
PrimeMeridian: 0
AngleUnit: "degree"
測地系(Datum)の情報や、Spheroid(楕円体)の情報格納されています。
PrimeMeridianは、本初子午線のことで、ここの数字は、緯度の基準が旧グリニッジ天文台からどれくらいの差分があるかを示しています。今回は0なので特に気にする必要はありません。

また、Spheroidをクリックすると、その中身を確認することができます。
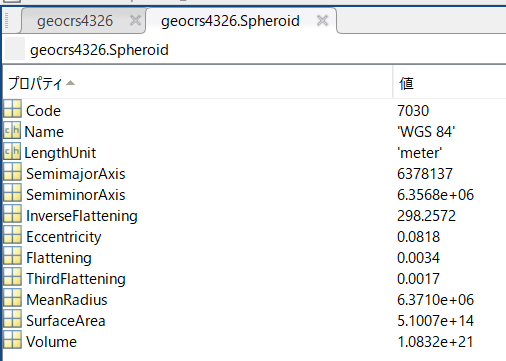
一部のみを紹介します。
-
Code: 割り当てられている識別コード EPSG:7030 -
SemimajorAxis: 赤道半径 6,378,137 m -
InverseFlattening: 扁平率の逆数 298.257223563
扁平率とは、(今回は)地球を表す楕円体が、完全な球と比べた時にどれくらい、扁平であるか(つぶれているか)を示します。全くつぶれていない(=球と同じ)場合は、0となり、つぶれているほど、1に近づきます。
楕円体の長半径をa、短半径をbとすると、扁平率は、
で表すことができます。
実際にその逆数を計算してみると、
f = 1-geocrs4326.Spheroid.SemiminorAxis/geocrs4326.Spheroid.SemimajorAxis; 1/f
ans = 298.2572
となり、InverseFlatteningの値と一致することが確認できます。
また、geocrsオブジェクトを用いて、そのWKTを簡単に作成することもできます。
WKT(Well-Known Text)は、ジオメトリの情報をテキスト形式で記述するものです。
str = wktstring(geocrs4326)
str = "GEOGCRS["WGS 84",DATUM["World Geodetic System 1984",ELLIPSOID["WGS 84",6378137,298.257223563,LENGTHUNIT["metre",1]]],PRIMEM["Greenwich",0,ANGLEUNIT["degree",0.0174532925199433]],CS[ellipsoidal,2],AXIS["geodetic latitude (Lat)",north,ORDER[1],ANGLEUNIT["degree",0.0174532925199433]],AXIS["geodetic longitude (Lon)",east,ORDER[2],ANGLEUNIT["degree",0.0174532925199433]],USAGE[SCOPE["Horizontal component of 3D system."],AREA["World."],BBOX[-90,-180,90,180]],ID["EPSG",4326]]"
ここでも、さきほどの、geocrsオブジェクトのような情報が確認できます。
projfwd関数を用いた、座標の変換
それでは、経度緯度の座標を投影座標に変換したいと思います。
このサンプルデータは、東京都で取得されたため、EPSGコードは6676を利用します。
変換自体は、projfwd関数を用いて簡単に行うことができます。
lon = ptCloud.Location(:,1); lat = ptCloud.Location(:,2); proj = projcrs(6676); [x,y] = projfwd(proj,lat,lon);
pcshow関数を用いた、点群の閲覧
pointCloudProj = pointCloud([x,y,ptCloud.Location(:,3)],"Color",ptCloud.Color); figure;pcshow(pointCloudProj)

以下の動画のように、MATLAB上でiPhone LiDARにて取得した点群を可視化することができました。 手軽にこのようなきれいな3D情報が取れてすごいですね。

3次元マップでの点群の可視化
次に、投影したxy座標をもとに、iPhone LiDARで取得した点群を、3次元のマップ上で可視化してみます。
このセクションの内容は、以前の投稿と同様です。詳細は以下の記事をご覧ください。
% 25点のうち1点のみを表示する。重くなってしまうため。 mskip = 1:50:length(lat); % 3Dで可視化するための図を用意する uif = uifigure; g = geoglobe(uif); % プロット geoplot3(g,lat,lon,ptCloud.Location(:,3)-mean(ptCloud.Location(:,3)),'r','MarkerSize',2,'Marker','o','HeightReference','terrain','LineStyle','none','MarkerIndices',mskip)
境界の表示の書き込み
さきほどは、点群ファイル全体を3Dのマップ上に表示させました。次に、この点群ファイルの境界を計算し、その境界のみを2Dの地図上に可視化してみようと思います。
境界の計算は、boundary関数で簡単に行うことができます。
ここで、計算を軽くするために、さきほど用いた間引きの間隔を用いて、50点ごとに境界を計算する点を抽出します。
% 点の間引き latSub = lat(mskip); lonSub = lon(mskip); % 境界の計算 k = boundary(latSub,lonSub); % 可視化は、geoplot関数が便利です figure;geoplot(latSub(k),lonSub(k)) % ベースマップの種類を指定できます geobasemap streets
kmlファイルへの書き込み
境界をkmlファイルとして書き込みを行います。
filename = 'myBoundary.kml'; kmlwriteline(filename, latSub(k), lonSub(k), 'Color','black','LineWidth', 3);
Google Earth Proでの表示
Windows環境で、かつ、Google Earth Proをインストールしている場合、以下のコマンドで、さきほど保存したkmlファイルをGoogle Earth上で確認することができます。Google Earth Proを別途開くことなく、MATLABからコマンド1行で起動できるのは非常に便利ですね。
Google Earth Pro(パソコン用)のダウンロードページ
winopen(filename)
以下の動画(GIF)では、winopen(filename)とコマンドウィンドウで入力しています。さきほど書き出した点群の境界をGoogle Earth上で可視化できていることがわかります。
まとめ
- この記事では、iPhone LiDARで取得した点群をMATLABを用いて、地図上で可視化しました
- 投影座標系から経度・緯度への変換も簡単に行うことができました
- 3Dのベースマップ上で、点群を可視化することができました
- 表示する点数が多くなると、非常にビューワーが重くなるため、間引くことが必要です
参考にしたページ(本文中に記載がないもの)
とらりもん:測地系 (datum)
Wikipedia: 扁平率
tohka383様:WKT にみる座標系について
MATLABドキュメンテーション:Transform Coordinates to a Different Projected CRS
MATLABドキュメンテーション:kmlwriteline
深層学習を用いた物体検出の手法(YOLOv2)についてのまとめ
この記事は、MATLABアドベントカレンダー(その2)の21日目の記事として書かれています。
はじめに
この記事では、物体検出の有名な手法である、YOLOv2について説明を行います。物体検出の手法を用いて、以下のように画像中から対象を自動的に検出することができます。

YOLOにより物体を検出しているときの動画の例も挙げます。以下の動画をご覧ください。

YOLOモデルは物体検出において非常に有名で、様々なバージョンが公開されています。この中でも、ネットワークがシンプルで、比較的高速かつ高精度に物体検出ができる、YOLOv2についてまとめたいと思います。YOLOなどの物体検出ネットワークの仕組みを説明した記事は多く存在します。本記事では、もとの論文の和訳をして、作者による説明を把握しつつ、適宜、補足説明を行います。これにより、論文をベースにした情報に触れながらも、(まずはぼんやりと)内容の理解の進む記事になればよいなと思いました。
そこで、本記事では、以下のリンクにある Redmon and Farhadi (2017) の論文の、Introductionと、Betterのセクションの和訳を行い、さらに、適宜、筆者の理解による補足を行います。特にBetterセクションでは、図を追加して、YOLOv2の原理について説明を行います。これにより、元の論文の流れをベースとして、YOLOv2の概要をつかみやすくすることを目指します。本記事を通して、物体検出の方法の理解度が上がれば嬉しく思います。なお、本論文では、以下の論文から図を引用しております。
[論文情報]
Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).
[論文のリンク]
なお、本記事で用いたコードや本文の原稿は以下のページにアップロードされています。
論文の和訳
それでは、さっそく論文のIntroductionから和訳を行っていきます。また、和訳に関しては、筆者の勝手な理解に基づいた意訳を多く含みます。ご注意ください。()内の内容は筆者による補足説明です。
Introduction
物体検出は、高速かつ正確で、さまざまな物体を認識できる必要がある。ニューラルネットワークの利用が広まり、物体検出のネットワークは、高速かつ高精度になってきている。しかし、ほとんどの物体検出手法は、まだ少数のオブジェクトに限定されており、現在の物体検出のデータセットは、分類やタグ付けといった他のタスクのデータセットに比べ、(データ数が)限られている。最も一般的な物体検出用データセットは、数千から数十万の画像のタグが含まれている[3] [10] [2]。一方で、分類データセットには、数百万の画像と数万から数十万のカテゴリが含まれる[20] [2] 。(このように、物体検出用のデータセットの量が少ないことがわかる。)
本論文では、検出を物体分類のレベルにまで拡張することを考える。しかし、物体検出のためのラベリングは、分類やタグ付けのためのラベリングよりもはるかに時間とコストがかかる。そのため、分類と同規模の物体検出用データセットが近い将来に登場する可能性は低い。我々は、既に存在する大量の分類データ を利用し、現在の検出システムの適用範囲を拡大する新しい手法を提案する。本手法は、異なるデータセットを一緒に組み合わせるために、物体の分類ラベルに対して階層的な見かたをする(例:食べもの⇒お肉系⇒焼肉)。また、物体検出と画像分類の両方のデータセットを用いて、物体検出のためのネットワークを学習することが可能なアルゴリズムも提案する。本手法は、(分類用の)ラベル付けをされたデータセットを利用して物体の正確な位置情報の推定方法を学習する。それに加え、分類のためのデータセットを利用して分類できる画像の種類を増やしたり、頑健性を向上させる。 この方法を用いて、9000以上の異なる物体のカテゴリを検出でき、さらにリアルタイムで推論のできるネットワーク(YOLO9000とよぶ)を学習させる。まず、ベースとなるYOLOとよばれるネットワークを改良し、YOLOv2の開発を行った。次に、ImageNetの9000クラス以上の画像分類のデータや物体検出のデータを用いてモデルの学習を行う。
Better
YOLOは、その他の物体検出手法と比較して、様々な欠点を抱えている。YOLOとFast R-CNNを比較した場合、YOLOはより多くの位置推定の誤差を有することがわかった(物体を検出したとしても、その位置に誤差が含まれる)。さらに、YOLOはregion proposal-basedな手法と比較して、再現率が低い(検出漏れが多い)ことがわかった。したがって、YOLOv2では分類精度を維持しつつ、主に再現率と位置推定の精度を向上させることを目指す。(以降、再現率をrecallとする)
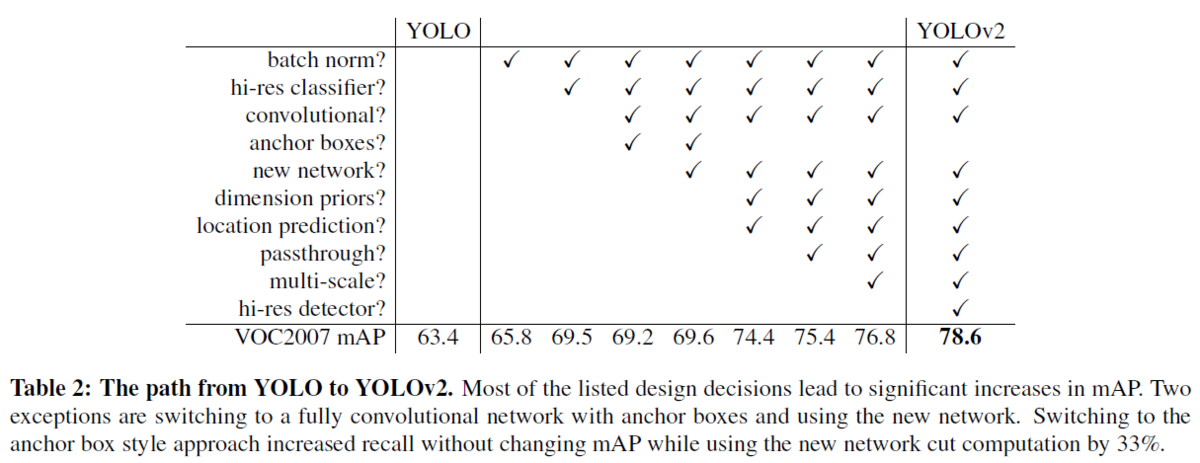
近年は深層学習を用いた物体検出の精度を向上させるために、ネットワークをより大きく、より深くする傾向にある[6] [18] [17]。より良い性能を得るためには、複数のモデルを構築し、それらの結果の平均などを取ることもある(アンサンブル)。 しかし、アンサンブルは計算コストも多くなるため、YOLOv2では、より正確かつ高速なネットワークを実現する。ネットワークのサイズを大きくする代わりに、ネットワークを単純化する。今回の提案では、過去の研究から得たアイデアと独自のコンセプトを融合させた。それらの結果の要約を表2に示す(この表の見方としては、チェックがあるところが、YOLOと比べて新たに追加した技術だと思います。例えば、左から2つ目の列だと、Batch Normalizationを追加した時はmAPが65.8で、そうでない場合は63.4である、といった形です)。
Batch Normalization
バッチ正規化により、他の正則化手法を使うことなく、学習を大幅に収束させやすくなる[7]。YOLOに含まれる全てのの畳み込み層の後にバッチ正規化層を加えることで、mAPが2%以上改善された。また、バッチ正規化はネットワークの正則化に役立つ。バッチ正規化により、ネットワークの過学習を防ぎ、ネットワークからドロップアウト層を除去することもできる。
バッチ正規化については、以下の記事がわかりやすかったです。
High Resolution Classifier
最先端の検出手法は、すべてImageNet [16]で事前に学習させた分類器を用いている。AlexNetを始めとして、ほとんどの分類器は、入力の画像のサイズが、256×256より小さいことが必要である [8]。オリジナルのYOLOでは,224×224の入力サイズで分類器ネットワークを学習し、検出のために画像サイズがを448×448になるように調整している。つまり、物体検出においては、画像分類から物体検出という異なるタスクのために、新たに学習が必要になるだけでなく、新しい入力解像度に適応する必要がある。そこで、YOLOv2では、まずImageNet上で10エポックの間、448×448の画像サイズで分類器ネットワークを微調整する。これにより、ネットワークはより画像サイズの大きい場合にも学習できるように各種重みなどをを調整するしやすくなる。この操作により、4%近いmAPの増加が得られた。
Convolutional With Anchor Boxes (その1)
YOLOは、畳み込み層の後に全結合層を置き、バウンディングボックスの座標を直接予測する。一方、Faster R-CNNでは座標を直接予測するのではなく、手動で選んだ事前分布を使用してバウンディングボックスを予測する[15]。そして、領域提案ネットワーク(RPN)を用いて、そのボックスのオフセットと信頼度を予測する。全結合層を用いて、直接バウンディングボックスの座標を予測するものとは異なり、畳み込み層の各グリッドが各ボックスのオフセットや信頼度を計算している。
==========論文の和訳をひとやすみ==========
補足事項1: YOLOv2のおおまかな流れについて
ちょうど上の、Convolutional With Anchor Boxesという章の前半で、YOLOv2の処理の内容が少し記述されていました。
そこで、論文の和訳は中断し、ここで、YOLOv2の大まかな流れを以下の図をもとに説明します。そして、このおおまかな流れの説明の後で、論文に戻り、どのような経緯でこのような方法に行きついたかを見ていきたいと思います。

1) 各画像をS×Sの領域に分割する (a)
- 上図の例では、(a)の画像が、4×4に分割されています
- 実際は入力の画像をこのように直接的に分割するのではなくて畳み込み層を通して、結果的に入力が小さくなります。その畳み込み層などの結果も、RGBの3チャンネルではなくて、およそ数千ものチャンネル数があります。
2) 1)で作成した各グリッドに物体があった場合、それはどのクラスか(クラス確率)を計算する (b)
- (b)を見てください。各グリッドがカラフルに色付けされています。例えば、黄色が樹木、緑が植生、青が車、赤が地表面付近の物体だとします。このように各グリッドのクラスを計算します。厳密には、各クラスの数値を計算して、その中で最も確率の高いクラスをそのグリッドのクラスとします。
- ここでは、物体があった場合の、条件付確率を求めています。つまり、物体があったと仮定したら、それぞれのクラスの確率はいくらであるかということです。
- 「そのグリッドに物体がある」とは、その物体の中心がそのグリッドに存在する場合を指します。
(引用:YOLOの論文)
If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
3) 各グリッドにおいて、物体がありそうなバウンディングボックスの位置とその信頼度を計算
- (c)を見てください。検出するための箱(バウンディングボックス)が複数出力されていることがわかります
- ここで、(バウンディングボックスの情報) = (中心のx, y座標+横幅、縦幅)で表すことができます。なぜなら、それぞれのバウンディングボックスの中心(や左上の隅)の座標を基準として、さらに横幅と縦幅がわかれば、バウンディングボックスは一つに定まるからです。
- 前方の樹木の幹や後方の樹木、自動車を検出したいのですが、(c)では、それらと関係のないものも複数出ており、この時点では正確な検出ができていないことがわかります。
- 推論時は、信頼度スコアqのみを予想。損失を計算して、重みを更新していく際は、右辺の値をもとに誤差が求まる。物体がない場合は0で、ある場合はIoUの値と等価


4) . (b), (c)より、信頼度×クラス確率を計算([d])
⇒各クラスごとの信頼度スコア(どれだけ推論が正確そうか)がわかる
(4’. 上の信頼度スコアやボックスの大きさが閾値以下なら消去)
5) 複数のバウンディングボックスが出力されないようにNMS を実行
NMSについて補足
1.Scoreの高いボックスから選択
2.そのボックスとIoUの高いもの (e.g. 0.5)を消去⇒繰り返し
==========論文の和訳を再開==========
上の章で、YOLOv2の大まかな流れを紹介しました。これにより、だいたいの雰囲気がつかめました。そこで、論文の和訳を再開し、このような手法い至った経緯を確認したいと思います。
Convolutional With Anchor Boxes (その2)
YOLOでは、全連結層を用いて、直接バウンディングボックスの位置を推定するのではなく、アンカーボックスを使って、各グリッドに存在する、バウンディングボックスの位置を予測する。ここではまず、プーリング層を1層削除し、ネットワークの畳み込み層の出力の解像度を高める(≒特徴マップの縦と横の大きさを大きくする)
またYOLOに入力する画像のサイズを小さくする。従来の448×448ピクセルから416×416ピクセルに縮小した。この理由は、畳み込みなどの結果で得られる特徴マップの縦横のピクセル数を奇数にしたいためである。提案するYOLOの畳み込み層により、入力画像を32分の1にダウンサンプリングする。つまり、416×416ピクセルの入力画像をYOLOにより処理すると、13×13の出力特徴マップが得られる。
アンカーボックスを用いた物体検出においては、各物体のクラスの予測と、各物体の位置の予測は別々に行われる。アンカーボックスごとにクラスとそのセルの物体らしさをYOLOでは予測したが、本手法もそれと同様のプロセスを踏む。物体らしさの予測の方法として、YOLOと同様に、グランドトゥルースとバウンディングボックスのIoUを予測する。また、その物体のクラスの予測においては、「そのバウンディングボックス内に物体が存在する場合における、その物体のクラスの確率」という、条件付き確率を予測する。
しかし、アンカーボックスを用いると、精度が少し低下してしまうという課題も存在する。YOLOは1画像あたり98個のボックスを予測するが、今回のようなYOLOv2にてアンカーボックスを用いた検出を行うことで、バウンディングボックスは1000個以上生成されるする。本発表の過程で試作した、アンカーボックスを用いない場合のモデルでは、mAPが、69.5 mAP、recallは81%であった。一方、今回のようなアンカーボックスを用いた場合、mAPは69.2 mAP、recallは88%であり、mAPは若干低下していることがわかる。しかし、recallの値は高く、mAPが減少しているとはいえ、本モデルにも改良の余地があると言える。
Dimension of Clusters
YOLOでアンカーボックスを使用する場合、2つの課題が生ずる。1つ目は、バウンディングボックスの寸法を手動にて選択する必要があるということだ(バウンディングボックスの寸法は自動では決められないということだ)。先述したように、ネットワークはバウンディングボックスの大きさ(の差分)を出力すること(や学習すること)が可能ではあるが、事前により確からしいバウンディングボックスのサイズを入力できれば、より精度の良い検出ができると考えられる。
完全に手動で(勘や経験に近い形で)事前分布を選択するのではなく、学習セットにてラベリング情報にあるバウンディングボックスの寸法に対してk-meansクラスタリングを実行することを考える。これにより、よりよいバウンディングボックスの大きさの設定が可能となる。標準的な、ユークリッド距離を用いたk-means法を使用した場合、大きなバウンディングボックスは小さなバウンディングボックスよりも、より大きな誤差を生ずる(単に寸法が大きいため、例えば同じ10%の誤差でも絶対量としては大きくなる)。ここでの目標は、より高いIoUを得るためのバウンディングボックスの大きさを決定することである。そこで、k-meansにて用いる「距離」の定義として、以下のものを用いる。
![]()
以下の図2に示すように、様々なクラスタ数(kの値)を用いて、k-meansを実行した。そして各クラスタにて、
1 最もそのクラスタの中心に近いバウンディングボックスの寸法を求める
2 そのクラスタの全てのバウンディングボックスと1で特定したバウンディングボックスのIoUを求める
3 全てのバウンディングボックスに対する、そのIoUの値を平均する
4 そのkの値のIoUの平均(3の値)をプロットする
ということを行う。
本論文では、k = 5にてClusterの数とIoUの値のバランスがとれていると判断し、クラスタの数は5とした。その結果、図2の右側のパネル中にあるように、様々な種類のバウンディングボックスを得ることができた。
==========論文の和訳を終了==========
YOLOv2の論文の一部しか和訳ができていませんが、これまでの内容で、おおよその仕組みや流れが紹介できたと思います。最後に、テストデータにて推論を行い、検出を行ったときに、その検出の良しあしを評価する方法について述べます。
物体検出の評価方法について補足
物体検出の評価指標として、平均適合率(mean Average Precision: mAP)が有名です。
具体的な計算方法については、以下の過去の記事で紹介しています。ぜひご覧ください。
アンカーボックスボックスの寸法を求めてみよう
後半は、YOLOv2の学習を行う上で、必要なステップについて、コードとともに確認していきたいと思います。
和訳の最後の部分で、アンカーボックスの寸法を、kmeans法により求めるとありました。論文中の図を見るだけでは、少し難しかったので、ここで例を用いて確認をしたいと思います。
なお、2022年12月現在では、estimateAnchorBoxes関数で、1行でアンカーボックスの計算を行うことができます。
データセットのダウンロード
この例では、295 枚の車両の画像から構成されるデータセットを使用します。Caltech の Cars 1999 データ セットおよび Cars 2001 データ セットからのものです (Caltech Computational Vision の Web サイトで入手可能)であり、Pietro Perona 氏によって作成されました。
以下のコードにて、ダウンロードすることができます。
clear;clc;close all pretrainedURL = 'https://www.mathworks.com/supportfiles/vision/data/yolov2ResNet50VehicleExample_19b.mat'; websave('yolov2ResNet50VehicleExample_19b.mat',pretrainedURL); unzip vehicleDatasetImages.zip data = load('vehicleDatasetGroundTruth.mat'); vehicleDataset = data.vehicleDataset;
バウンディングボックスの分布を可視化
アンカーボックスの寸法を求めるときに、学習データのバウンディングボックスの情報を用います。本データの様子を眺めるため、面積とアスペクト比を用いてプロットします。
% バウンディングボックスの情報を抽出 allBoxes = cell2mat(vehicleDataset.vehicle); % バウンディングボックスの面積とアスペクト比のプロット % アスペクト比の計算 aspectRatio = allBoxes(:,3) ./ allBoxes(:,4); % 面積の計算 area = prod(allBoxes(:,3:4),2); % 図示 figure scatter(area,aspectRatio) xlabel("バウンディングボックスの面積") ylabel("アスペクト比 (width/height)"); title("面積 vs. アスペクト比")
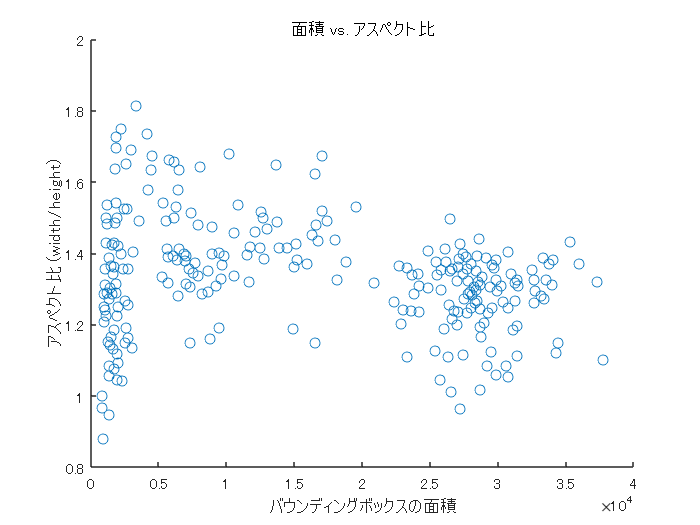
バウンディングボックスをクラスタリングし、アンカーボックスを決定
例えば、クラスタの数を6に設定し、論文と似た方法で、バウンディングボックスの寸法を決定したいと思います。
論文では、kmeans法が紹介されていました。しかし、ここでは、kmedoidsを用います。kmedoids関数では、デフォルトの設定として、kmeans++法を実行します。
まずは、例として、クラスタの数を6としてみます。また、距離は論文にあったとおり、ユークリッド距離ではなく、IoUに関する値(1-IoU)でした。距離の定義をカスタムに設定するため、'Distance'の引数を設定します。また、具体的な距離の計算の仕方は、iouDistanceMetric.mというコードに記述します。
% 6つのグループにクラスタリング numAnchors = 6; % K-Medoidsを使ってクラスタリング [clusterAssignments, anchorBoxes, sumd] = kmedoids(allBoxes(:,3:4),numAnchors,'Distance',@iouDistanceMetric); % クラスタリングした平均アンカーボックスのサイズ disp(anchorBoxes);
145 105
38 31
96 64
192 148
115 82
50 40
% クラスタリング結果のプロット figure gscatter(area,aspectRatio,clusterAssignments); title("K-Mediodsで"+numAnchors+"個クラスタリング") xlabel("面積") ylabel("アスペクト比 (width/height)"); grid
% 累積加算 counts = accumarray(clusterAssignments, ones(length(clusterAssignments),1),[],@(x)sum(x)-1); % 平均IoUを計算 meanIoU = mean(1 - sumd./(counts)); disp("平均IoU : " + meanIoU);
平均IoU : 0.86311
このように、kmedoids法とバウンディングボックス情報から、クラスタ数が6のときの平均IoUを求めることができました。最後に、論文にあったように、kの値を変えながら、平均IoUとアンカーボックスの数のバランスを可視化しようと思います。
アンカーボックスの数と平均IoUの関係の確認
上のセクションのコードをfor文で回します。
アンカーボックスを増やすと平均IoUは改善するが計算量は増大します。
このデータセットでは以下のような関係を得ることができました。論文での記述と合わせると、だいたいk=5くらいが良いのではないかと思われます。
% 1から15までアンカーボックスを増やしたときに平均IoUの改善がどうなるかを計算する maxNumAnchors = 15; for k = 1:maxNumAnchors fprintf('number of anchor box: %d\n',k) % Estimate anchors using clustering. [clusterAssignments, ~, sumd] = kmedoids(allBoxes(:,3:4),k,'Distance',@iouDistanceMetric); % 平均IoUを計算 counts = accumarray(clusterAssignments, ones(length(clusterAssignments),1),[],@(x)sum(x)-1); meanIoU(k) = mean(1 - sumd./(counts)); end
number of anchor box: 1 number of anchor box: 2 number of anchor box: 3 number of anchor box: 4 number of anchor box: 5 number of anchor box: 6 number of anchor box: 7 number of anchor box: 8 number of anchor box: 9 number of anchor box: 10 number of anchor box: 11 number of anchor box: 12 number of anchor box: 13 number of anchor box: 14 number of anchor box: 15
figure plot(1:maxNumAnchors, meanIoU,'-o') ylabel("平均IoU") xlabel("アンカー数") title("アンカー数 vs. 平均IoU")
まとめ
この記事では、YOLOv2の仕組みを論文の和訳とともに紹介しました。また、後半では、アンカーボックスの寸法の決定方法を、小規模なデータセットを用いて確認しました。 YOLOをはじめとする、深層学習を用いた物体検出の手法は非常に多くの分野で応用が進められています。農学分野での応用として、以下のような利用を発表させていただきました。こちらもご覧いただけますと幸いです。