点群のファイル形式であるPTS形式について
1. はじめに
この記事では、3次元点群のファイル形式の1つである、pts形式について説明したいと思います。pts形式は、主にLeica製品によりエキスポートされます。
また、点群の別の形式であるE57やLASについては以下の記事で紹介しています。
2. ptsファイルの中身について
2.1. 各列の情報について
点群ファイルは、対象の3次元情報を表すために、xyz座標の情報を有しています。さらに、そのため、点の数だけ、xyz情報があり、それらが各行に格納されます。pts形式では、そのxyz情報の他に、その点をレーザースキャナで取得した時の反射強度、およびその点のRGB情報を持たせることができます。
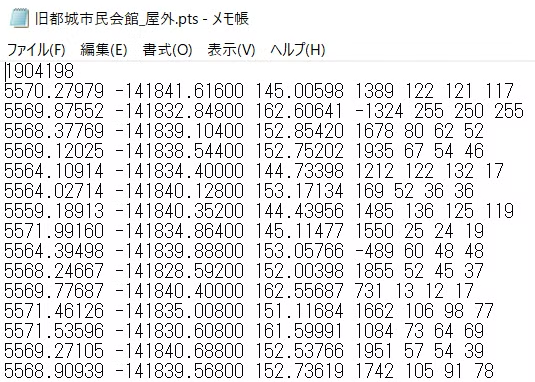
以下の図に、ptsファイルを「メモ帳」で開いた時の例を示します。一番初めに、そのファイルに含まれる点の数(1904198)があり、2行目からが、各点の情報を示します。1~3列目はxyz情報を示しています。4列目は強度情報を示しています。そして、5~7列目に、RGB情報が格納されています。ptsファイルは、ascii形式であるため、「メモ帳」などで開くことができます。
ptsファイルの内容を以下の表にまとめます。
| 項目 | 内容 |
|---|---|
| 提供元 | Leica |
| ASCII/Binary | ASCII |
| 点群全体の情報 | 点数 |
| 各列の持つ情報 | XYZ/反射強度/RGB情報 |
2.2. iPhone LiDARでptsファイルをエキスポートしたときの例
ptsファイルは、主に、Leica社製のレーザースキャナで取得した点を、ソフトウェアを用いてエキスポートしたときに利用されます。しかし、近年急速に広まっているiPhoneに搭載されたLiDAR(iPhone LiDAR)でもptsファイルとして点群をエキスポートすることも可能です。
iPhone LiDARのアプリの中で最も有名なものの1つに、3d Scanner Appが挙げられます。


エキスポートする際に青枠のPTS形式を選択してください。

エキスポートすると、ptsファイルを以下のようにメモ帳で閲覧することができました。3d Scanner Appからエキスポートした場合は、強度情報は、すべて0になっています。

3. 公開されているpts形式の点群データの例
インターネット上にいくつか、pts形式の点群ファイルが無料公開されています。その例をこの章で述べます。
3.1. 旧都城市民会館
以下のリンクから、ダウンロードすることが可能です。
こちらのデータは、旧市民会館が解体されることを受けて、それらを3Dデータとして保存するプロジェクトの中で取得されました。
www.city.miyakonojo.miyazaki.jp
こちらのデータ(高密度でないもの)はオープンソースとして公開されています。このデータを利用して、SNSなどで発信する際は、「#3DDA #旧都城市民会館」 で投稿するとよいそうです。
3.2. truevis様のページ
以下のページでは、より小規模な点群がpts形式でダウンロード可能です。
4. ptsファイルをMATLABで読み込んで閲覧してみよう
3.1で述べた、旧都城市民会館の点群ファイルをプログラミングにて読み込み、閲覧したいと思います。言語はMATLABを利用します。ASCII形式なので、readmatrix関数で簡単に読み込むことができます。pointCloud関数で、point cloud変数にして、pcshow関数で表示できます。
clear;clc;close all
%% 読み込み
xyzirgb = readmatrix("旧都城市民会館_屋外.pts","FileType","text");
%% point cloud変数を作成
pt = pointCloud(xyzirgb(:,1:3),"Color",xyzirgb(:,5:7)/255,'Intensity',xyzirgb(:,4));
%% RGB表示
figure;pcshow(pt);title('RGB表示')
%% intensity表示
figure; pcshow(pt.Location,pt.Intensity);title('intensity表示');hold on
colorbar
以下の動画は、pcshow関数で、点群を表示したときの様子を示します。
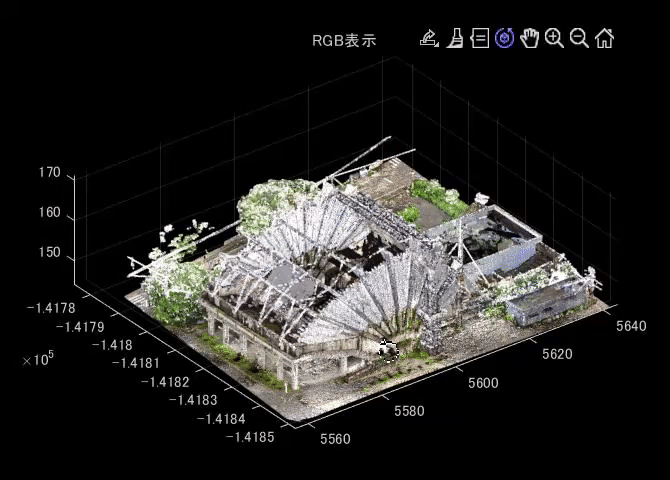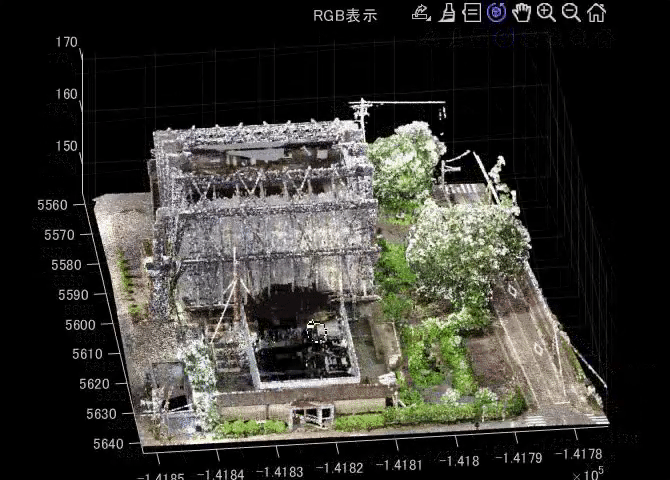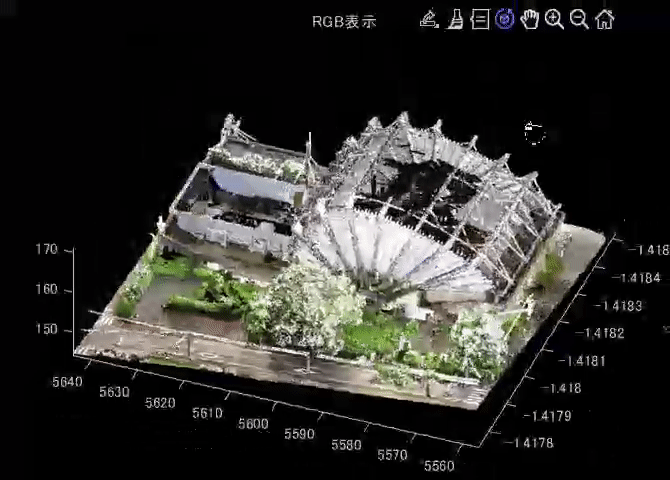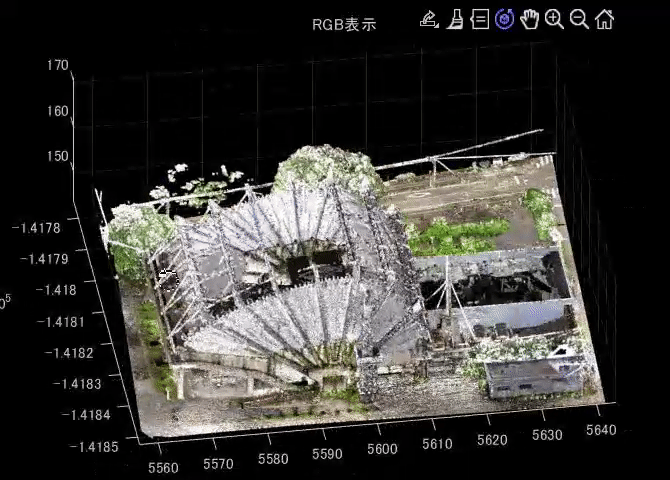
データについて
本記事では、旧都城市民会館の点群を利用させていただきました。
3次元点群のフォーマットであるLAS形式について
0. はじめに
LiDAR(Light Detection and Ranging)や写真測量技術を使って取得される点群データは、建設、測量、インフラ管理、考古学、ゲーム開発など、広範な分野で活用されています。これらのデータは、各点の座標(X, Y, Z)やその他の属性情報を含み、現実の物体や環境を高精度に記録するために重要です。
点群データを保存・共有するためのフォーマットも多岐にわたります。よく利用されるフォーマットには、LAS、LAZ、TXT、E57、PTS、PTX、XYZなどがあり、それぞれ異なる特徴と用途があります。特にLASファイルは、LiDARデータの標準フォーマットとして広く利用されており、効率的なデータ圧縮や属性情報の管理が可能です。
本記事では、LASファイルを中心に、点群データを扱う際に知っておくべき基本的なフォーマットの特徴を紹介するとともに、LASファイルの中身を詳細に解説します。LASファイルがどのように座標値や属性データを格納しているのか、また他のフォーマットと比較してどのような利点があるのかを紹介していきます。
LAS以外の主要なフォーマットである、E57やptsについては以下の記事で紹介しています。
1. LASファイルについて
LASファイルとは、3次元点群を格納するための代表的なフォーマットである。また、LASファイルを圧縮したLAZファイルもよく用いられる。
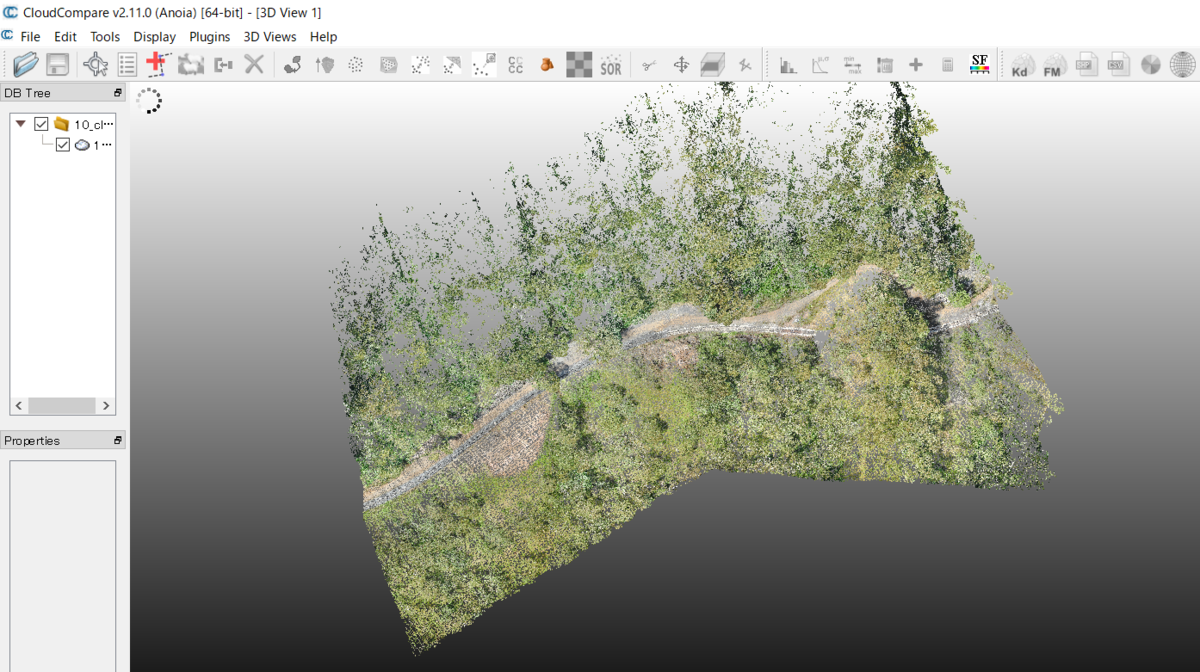
例えば、以下の図は、Cloud Compareにて、3次元点群を閲覧している時の様子を示す。
静岡県や長崎県、東京都、埼玉県などのオープンデータはLAS形式でダウンロードすることができる。
以下は埼玉県より公開されている点群データをダウンロードする時の様子を示す。
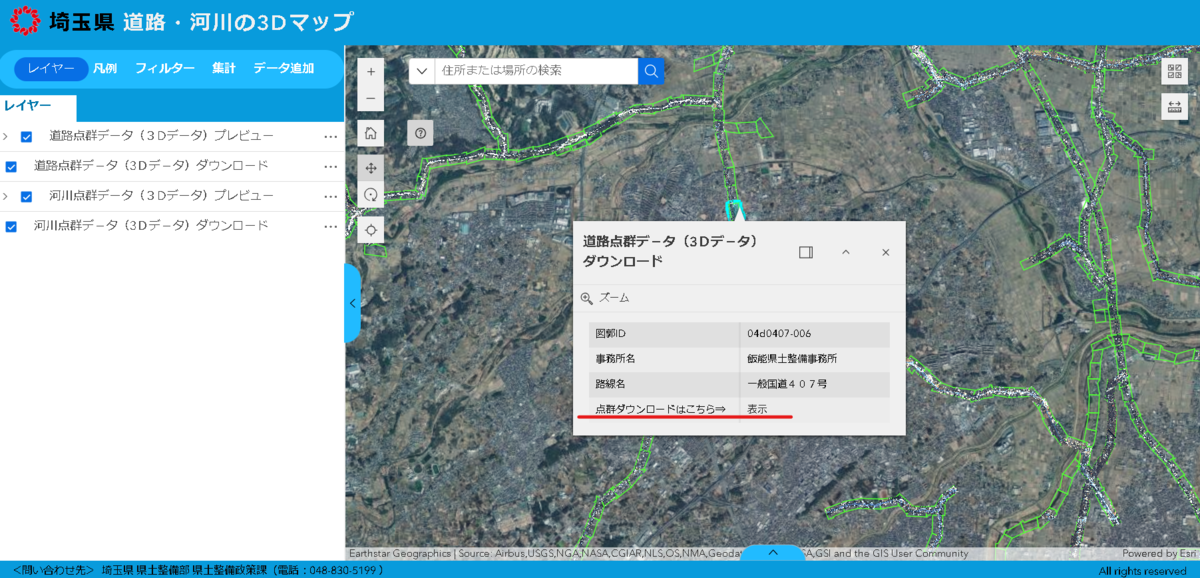
例えば、埼玉県の点群ファイルは以下のURLからダウンロードすることができる。
以下のようにLAS形式のファイルを得ることができる。

LAS形式に関する基本情報は以下のとおりである。2章以降でその詳細について説明する。
| Name | 内容 |
|---|---|
| ASCII/BINARY | BINARY |
| 開発者(団体) | American Society for Photogrammetry and Remote Sensing (ASPRS) |
| Initial release | May 9, 2003 |
| Latest release | July 9, 2019 (Version 1.4) |
| 開くことのできるオープンソフトウェアの例 | CloudCompare, Potree, PotreeDesktop, QGIS など |
| データに含まれる情報 | X, Y, Z座標, Intensity(反射強度), RGBカラー, 分類コード(地面、植生など), GPSタイムスタンプ, スキャン角度など |
2. LASファイルの基本的な構成について
LASファイルを構成する要素は以下のとおりである。
| 構成要素 | 必須か | 説明 | 具体例 |
|---|---|---|---|
| Header | 必須 | LASファイルの基本情報を格納 | 点数、点の範囲 |
| Point data records (Records) | 必須 | LASファイルの中核となる部分で、実際のLiDARの点群データを格納 | X, Y, Z 座標、Intensity、Classification |
| Variable Length Records (VLR) | 任意 | ファイル全体に関する追加の情報を格納。可変長。 | 空間参照系や、その他のメタ情報 |
| Extended variable length records (EVLR) | 任意 | VLRと似た役割。ファイルの末尾に配置され、あとから情報の追加が可能。 | - |
2.1. Header
LASファイルのバージョン(1.1, 1.2...など)や点数、点の範囲などの基本的な情報を有している。以下に、LASのHeaderを読み込んだ時の例を示す。
| ヘッダーの項目 | 内容の例 | コメント |
|---|---|---|
| 'File Signature' | 'LASF' | LASF (LAS File)と記載されている必要がある |
| 'File Source ID' | 0 | - |
| 'Global Encoding' | 0 | - |
| 'Project ID - GUID data 1' | 0 | プロジェクトのGUID(グローバル一意識別子)。 |
| 'Project ID - GUID data 2' | 0 | - |
| 'Project ID - GUID data 3' | 0 | - |
| 'Project ID - GUID data 4' | ' ' | - |
| 'Version Major' | 1 | LASの major バージョン (= LAS 1.2) |
| 'Version Minor' | 2 | LASの manor バージョン(= LAS 1.2) |
| 'System Identifier' | 'PDAL’ | どのようなシステムや機器を使って点群データが取得または処理されたかを記録する |
| 'Generating Software' | 'PDAL 2.6.2 (Releas)’ | データを生成したソフトウェア |
| 'File Creation Day of Year' | 6 | 年初から数えた時のLASファイルが作成された日 |
| 'File Creation Year' | 1980 | LASファイルが作成された年 |
| 'Header Size' | 227 | ヘッダーのサイズ(バイト単位) |
| 'Offset to point data' | 548 | ヘッダーの終わりから最初のポイントデータまでのオフセット(バイト単位) |
| 'Number of variable length records' | 4 | 可変長レコード(VLR)の数 |
| 'Point Data Format ID' | 130 | 点群データの形式ID |
| 'Point Data Record Length' | 26 | 各点群データレコードの長さ(バイト単位) |
| 'Number of point records' | 196314863 | 記録された点の数 |
| 'Number of points return 1' | 196314863 | 最初のリターン(反射光)の点の数 |
| 'Number of points return 2' | 0 | 2番目のリターンの点の数 |
| 'Number of points return 3' | 0 | 3番目のリターンの点の数 |
| 'Number of points return 4' | 0 | 4番目のリターンの点の数 |
| 'Number of points return 5' | 0 | 5番目のリターンの点の数 |
| 'X scale factor' | 0.001 | X座標のスケール |
| 'Y scale factor' | 0.001 | Y座標のスケール |
| 'Z scale factor' | 0.001 | Z座標のスケール |
| 'X offset' | -10000 | X座標のオフセット |
| 'Y offset' | -30000 | Y座標のオフセット |
| 'Z offset' | 0 | Z座標のオフセット |
| 'Max X' | -17525.216 | 点群データ内の最大X座標値 |
| 'Min X' | -17667.633 | 点群データ内の最大Y座標値 |
| 'Max Y' | -36439.896 | 点群データ内の最大Z座標値 |
| 'Min Y' | -36546.117 | 点群データ内の最小X座標値 |
| 'Max Z' | 41.15 | 点群データ内の最小Y座標値 |
| 'Min Z' | 31.018 | 点群データ内の最小Z座標値 |
LASファイルのバージョンが異なると、機能やサポートするデータの種類が変わります。
例えば、LAS1.3から波形データ(Waveform Data)に関連するフィールドが追加されています。
また、バージョン1.4では、後述するVLRがさらに拡張されたEVLRもサポートされ、より大きなデータにも対応します。
分類コードも255までサポートされています。これにより、さらに細かな分類が可能となり、より多様なアプリケーションでの利用が期待されます。
フォーマットの更新については、以下のLASのドキュメントに記載があります。
LAS SPECIFICATION VERSION 1.3
https://www.asprs.org/a/society/committees/standards/LAS_1_3_r11.pdf
LAS Specification 1.4 - R14
https://www.asprs.org/wp-content/uploads/2019/03/LAS_1_4_r14.pdf
2.1.1. Scaleとoffsetについて
LAS/LAZファイルにおけるscale(スケール)とoffset(オフセット)は、点群データの精度とサイズを効率的に管理するために使われる重要な概念である。ここではLiDARデータを効率的に格納し、各点のXYZ座標の数値範囲を縮小するために、スケールとオフセットを利用している。
1. Scale(スケール)

- スケールは、点群の座標値を適切な範囲に縮小するための係数である。LASファイル内では、点の位置は整数として保存されているが、この整数は実際の座標値を表すためにスケールファクタを掛け合わせて変換される。
- スケールの主な役割は、データサイズの削減と精度の維持である。LiDARデータは非常に高精度な情報を含むため、直接座標値を格納すると、ファイルサイズが大きくなる場合がある。しかし、スケールファクタを用いることで、元の座標値をより小さな数値で格納できる。
- 例えば、スケールファクタが
0.01の場合、ファイル内で格納されている数値が500であれば、実際の座標値は500 * 0.01 = 5ということになる。 - XYZ座標は32ビット(4,294,967,296)の整数で記録される。そのため、X (Y, Z) scale factorや、X (Y, Z) offsetを用いて、もとの座標に直すことができる。
2. Offset(オフセット)

- オフセットは、点群データ全体の基準点を定め、各点の座標値がその基準点からの相対的な位置として保存されるようにする値である。これにより、座標値が非常に大きくなる場合でも、オフセットを用いることで小さな数値として格納でき、効率性が向上する。
- オフセットを使うことで、全ての座標値は相対的な数値で保存される。例えば、オフセットが
1000で、格納されている座標値が10であれば、実際の座標は1000 + 10 = 1010となる。
3. スケールとオフセットの使用例
例えば、LASファイルである点のX座標がスケール 0.01、オフセット 1000 の場合、ファイル内で格納されているX座標値が 500 であれば、実際の座標は以下のように計算されます:
実際の座標値 = (格納されている値 * スケール) + オフセット
この場合、
X = (500 * 0.01) + 1000 = 5 + 1000 = 1005
したがって、この点の実際のX座標は 1005 となります。
- スケールとオフセットは、特に広い範囲のLiDARデータを扱う場合に重要である。例えば、都市全体のLiDARデータを扱う際、直接数値を保存するとデータサイズが大きくなる可能性があるため、スケールとオフセットを適切に設定して効率的にデータを保存する。
- また、スケールファクタの精度設定によって、どれだけ細かいレベルで座標値を記録するかを調整できる。高精度な測定が必要な場合はスケールを小さくし、大まかなデータであればスケールを大きく設定することができる。
これらの仕組みにより、LASファイルは高精度な座標データを効率的に格納し、かつサイズを抑えつつ正確な位置情報を保持できるようになっている。
2.1.2.ソフトウェアでLASファイルを読み書きした場合の例
2.1.2.1. 点群を読み込む場合: CloudCompareやQGISを利用
CloudCompareのv2.13でLASファイルを読み込んだ時の例を示す。
Headerに含まれる以下の項目をこのウィンドウの赤丸で囲った部分から確認することができる。
- Version
- Point format
- Number of points
2.2にて後述するPoint data recordsに含まれるデータのカラムに関してもこのウィンドウの赤い四角で囲った部分から確認することができる。
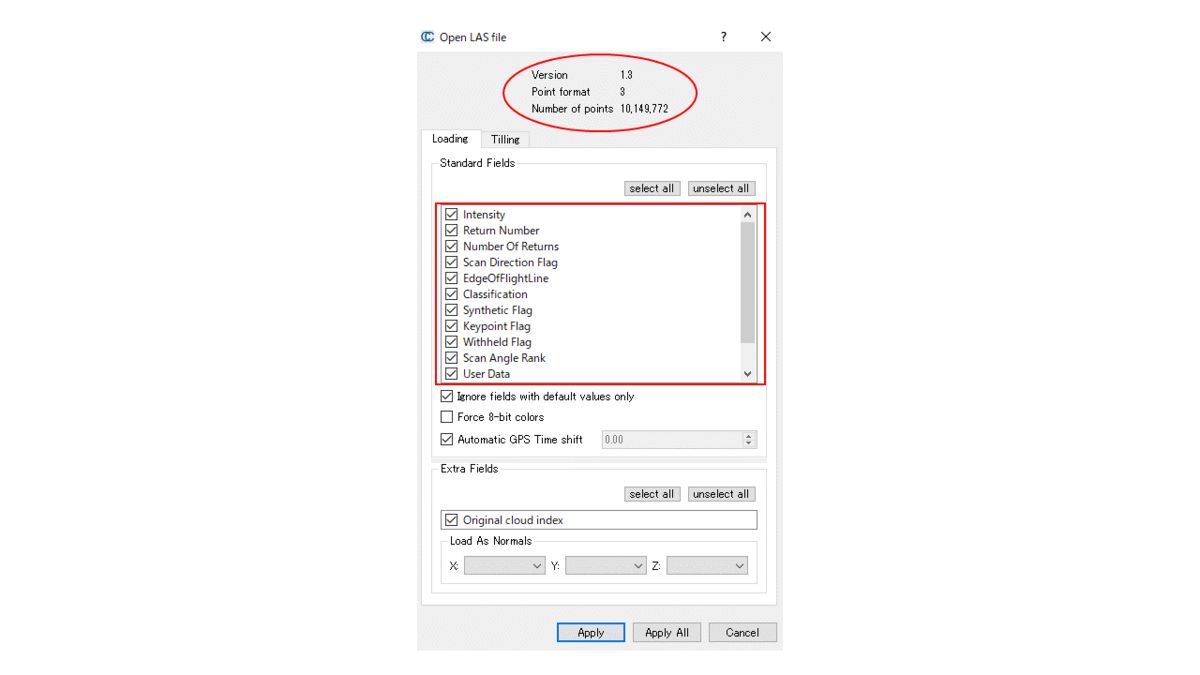
また、先述したoffsetの値が、ここでのShiftの値として記載されている。ここでYesとすることで、CloudCompare上にシフトした状態の点群を読み込むことができる。また左下に Preserve global shift on saveとあるように例えばシフトした状態の点群を編集し、さらにその結果を書き込む場合は、ここで一時保存されているシフトの値を加味したうえで点群が保存される。
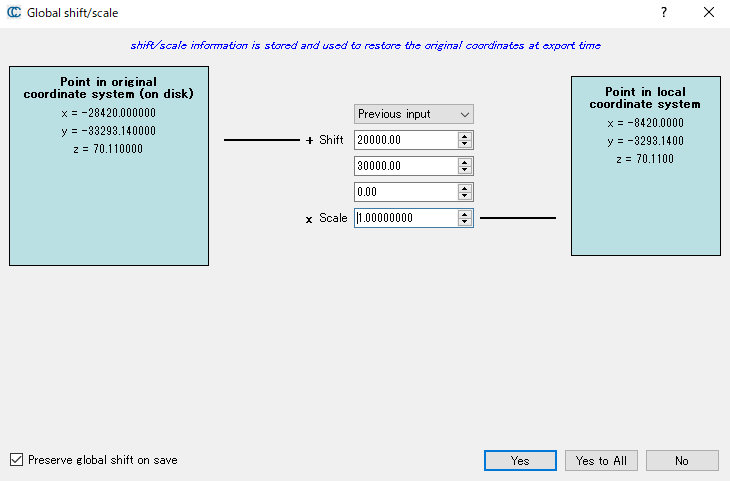
次に、QGISでLASファイルを読み込んだ時の様子を示す。OpenStreetMapと重ね合わせて表示させている。
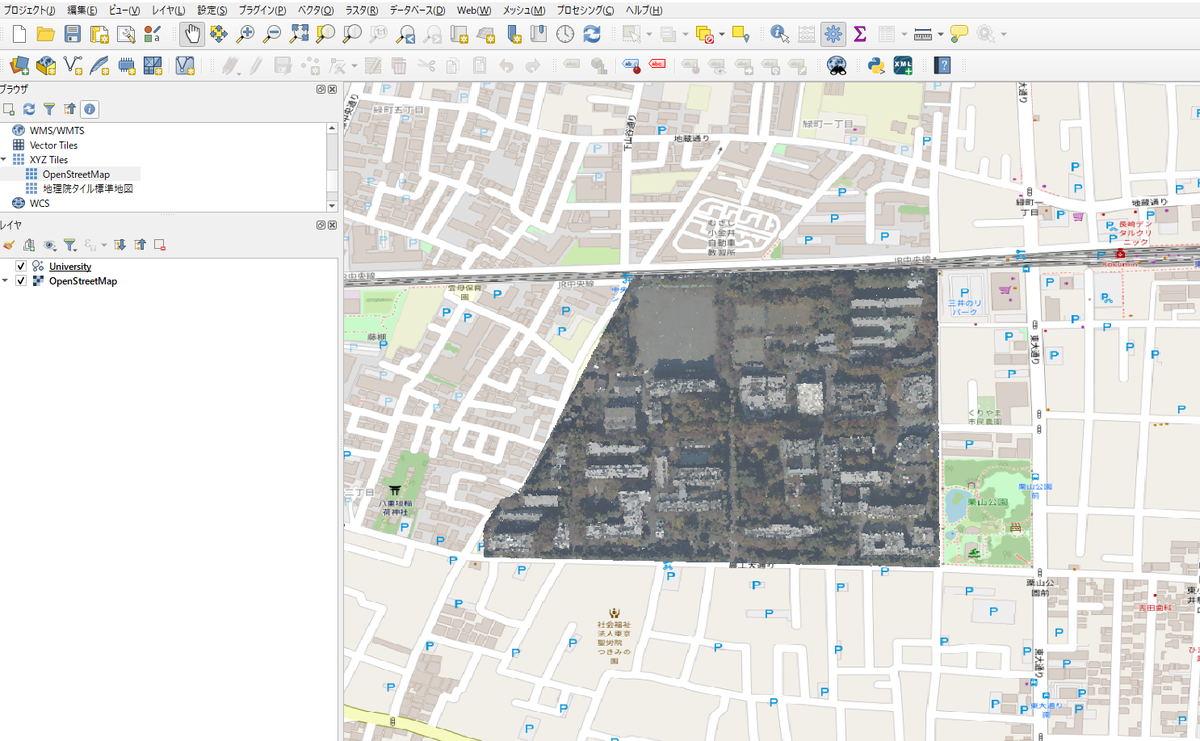
プロパティを見ると、同様に、ScaleとOffsetが記載されていることがわかる。
2.1.2.2. 点群を書き込む場合
CloudCompareにて、File>Saveの順にクリックすることで点群を保存することができる。
Basic Paramsを見ると、Scaleなどが指定できることがわかる。点群のXYZ座標をより詳細に保存したい場合は、この値を0.1mmなどにするとよい。一方で、点群が街全体などを示すデータで、あまり解像度も高くない場合であればこのScaleの値を0.1mなどにするとよい。
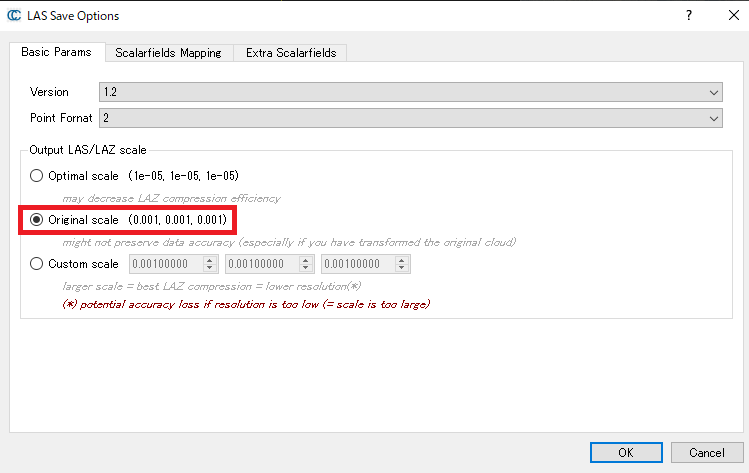
2.2. Recordについて
Recordには、3次元点群データのメインのデータが格納されている。主なものについて以下に説明する。
2.2.1. xyz座標について
LAS形式ではXYZ情報は32ビットの整数で表されており、先述したように、offsetやscaleの値を利用して、再スケーリングしている。
2.2.2. intensityについて
照射したレーザービームの反射強度を示す。
2.2.3. return numberについて
例えば、航空機LiDARでは、空中から地上にレーザービームを照射したとき、複数のレーザービームの反射(リターン)を得ることができる。
- ファーストリターン:はじめに、地上部の物体に到達し、反射してきたもの。地面や植生の上部から返ってくることが多い。
- セカンドリターン以降:植生からの多重の反射を受けて返ってくる。
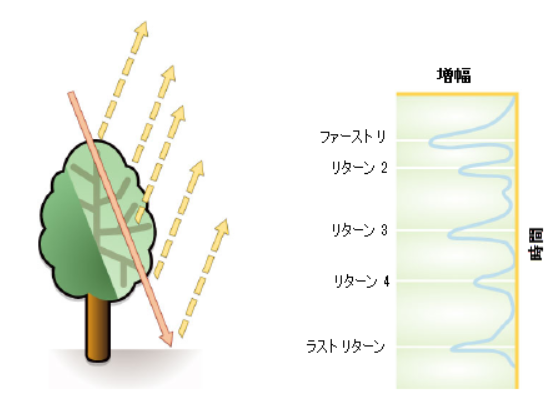
図出展:LIDARデータとは
リターンごとの傾向
以下の図は、各リターンから得られた時の点群を上から見たときの図である。
- Return1(右下)は全方面から得られている。また、水面からはうまく反射が得られず、欠落していることがわかる。
- LiDARの波長は900 nm付近を利用しているものも多い(例:velodyne, yellow scan)。この波長は水に吸収されやすいためである。
- Return2は植生から得られていることが多い。
- Return3も植生から得られていが、Return2よりも、割合が低いことがわかる。

図出典: lidar return number and classification
2.2.4. classificationについて
主な分類のクラスについて
- その点がどのクラスに属するかを示している。ASPRS基準でどの分類をどの番号を割り当てるかがあらかじめ決められている。
- 10, 11, 13以降は特に指定されていないため、特別な解析の際はその番号を使うことも可能である
- 例)電線や線路の検出

- 例)電線や線路の検出
画像出典:ASPRSより
⚠️ TellaScanなどの他のソフトウェアとの兼ね合いもあり、未分類のクラスに関しては、0と1の両方が用いられる場合がある。
Flagについて
各分類に対して、さらに情報を与えることができ、例えば、ある点をKey-pointであると指定すると、点の間引き処理を行ったときも、その点は削除されない。また、Withheld (保留)のFlagをオンにすると、その点は解析に用いられない。

画像出典:ASPRSより
2.2.5. User Dataについて
ユーザーが独自に格納することのできるフィールドである。しかし、LASのバージョンにもよるが、user_dataは8ビット(0-255)であることが多く、自由に値を格納できないことが多いことに注意する。
2.2.6. gps_timeについて
その点が取得されたときの時間
2.2.7. red, green, blue
その点の持つ色情報。16bitで保存されていることが多い。
2.3 Variable Length Records (VLR)について
VLRとは、空間参照系や、その他のメタ情報など、ユーザーの目的に応じて、点群に対する情報を付加することができる。
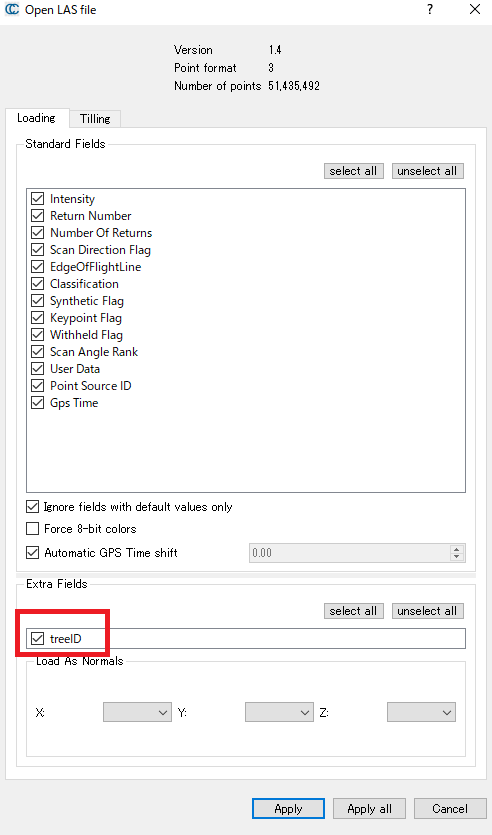
例えば、樹木の解析を行い、各点に樹木のID(treeID)を割り当てたい場合、独自のVLRを定義することができる。ここではtreeIDという値を格納している。
以下の図は、プログラムにて各点に樹木のID(treeID)を割り当て、そのIDごとに異なる色で示した例である。

以下のように、CloudCompareで開くと、treeIDがExtra Fieldsに表示されていることがわかる
その他のVLRの例を示す。このデータおよびコードはMATLABの例題から得たものである
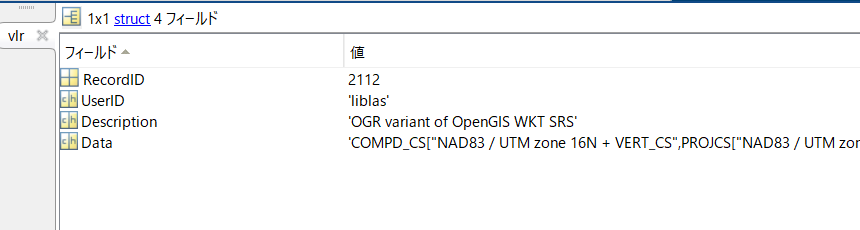
- Dataの中身を一部を以下に示す
UTM zone 16Nなどの情報が確認できる
'COMPD_CS["NAD83 / UTM zone 16N + VERT_CS", PROJCS["NAD83 / UTM zone 16N", GEOGCS["NAD83", .... (続く)
8. 座標参照系 — QGIS Documentation ドキュメント
VLRの一覧の例
| Record ID | 説明 |
|---|---|
| 0 | クラス分類ルックアップのデータ(文字列形式) |
| 3 | テキストエリアの説明データ(文字列形式) |
| 100-354 | 波形パケット記述子のデータ(ビット数、圧縮タイプ、サンプル数、時間間隔、デジタイザのゲイン・オフセットなど) |
| 2111 | OGS数式変換WKTのデータ(文字列形式) |
| 2112 | OGS座標系WKTのデータ(文字列形式) |
| 34735 | GeoKeyDirectoryTagのGeoTiffキー値(バージョン、キー数、エントリなど) |
| 34736 | GeoDoubleParamsTagの数値データ(double型) |
| 34737 | GeoAsciiParamsTagのデータ(文字列形式) |
2.4. Extended variable length records (EVLR)
VLRと類似している。VLRに比べて、大きなビット数を利用しており、より大きな値を格納することができる。
- las1.3で導入された
- 定義できるEVLRは1つのみ
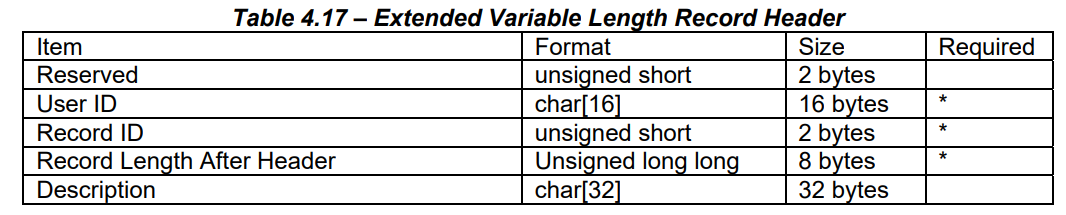
画像出典:ASPRSより
3. まとめ
LASファイルは、LiDARデータの標準フォーマットとして広く利用されており、効率的なデータ圧縮や属性情報の管理が可能です。
LASファイルの基本構成要素は以下のとおりです:
- Header:ファイルの基本情報(点数、範囲、バージョンなど)を含みます。
- Point Data Records:実際の点群データ(X, Y, Z座標、Intensity、Classificationなど)が格納されています。
- Variable Length Records, VLR:空間参照系やメタデータなど、追加情報を格納する任意の領域です。
- Extended Variable Length Records, EVLR:VLRと似ていますが、より柔軟に情報を追加できます。
スケール (Scale) とオフセット (Offset)
- スケールは、座標値を適切な範囲に縮小するための係数で、データサイズの削減と精度の維持に役立ちます。
- オフセットは、点群データ全体の基準点を定め、各点の座標値をその基準点からの相対位置として保存します。
- 座標値は32ビットの整数で保存され、スケールとオフセットを用いて実際の座標値に変換されます。
ポイントデータレコードの主な内容:
- XYZ座標:スケールとオフセットを用いて実際の座標値を計算します。
- Intensity(反射強度):レーザービームの反射強度を示します。
- Return Number(リターン番号):レーザービームが物体に当たって反射して戻ってくる回数を示します(ファーストリターン、セカンドリターンなど)。
- Classification(分類コード):各点が地面、植生などどのクラスに属するかを示します。
- User Data:ユーザーが独自の情報を格納できます。」
- RGBカラー:各点の色情報を保存します。
可変長レコード (VLR) と拡張可変長レコード (EVLR):
- VLRは、空間参照系やその他のメタ情報など、ファイル全体に関する追加情報を格納します。
- EVLRは、VLRと似ていますが、ファイルの末尾に配置され、より大きなデータを格納できます。
Reference
https://www.asprs.org/a/society/committees/standards/asprs_las_format_v12.pdf
Potree Desktop: 概要とダウンロード方法
1. Potree Desktopとは
Potree Desktopでは、点群の閲覧を行うことができる。3次元点群の閲覧にはCloudCompareが有名ですが、Cloud Compareに比べ、
- LAS形式で10GBを超えるような容量の大きな点群でもサクサクと点群を閲覧することができる
- 分類別に可視化したときの色分けがきれいに見られる
- 点が見やすいため計測ツールが使いやすい
といったメリットがある。
参考: github (PotreeDesktop)
github.com
2. セットアップについて
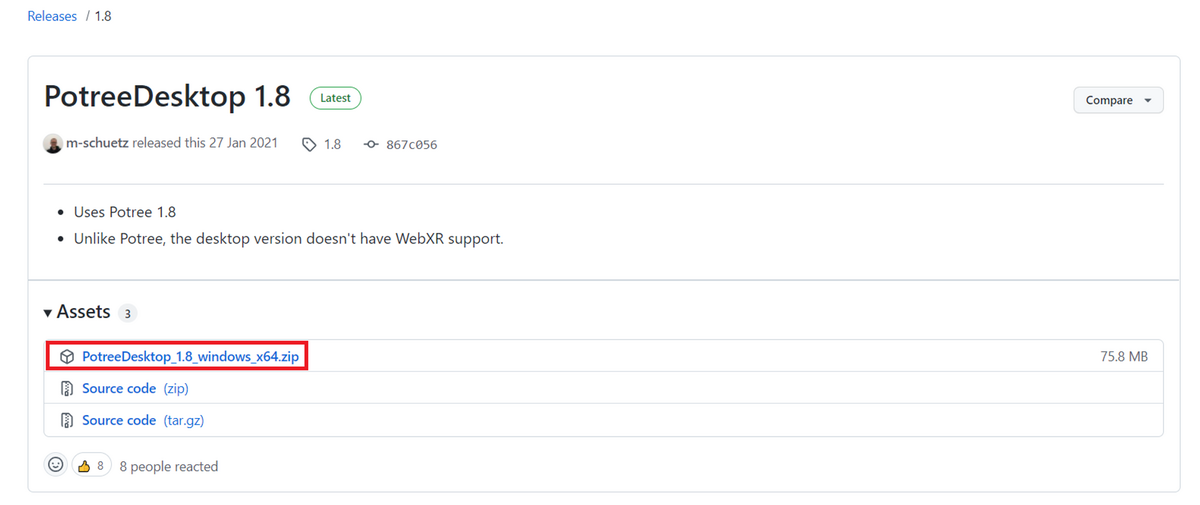
2.1. ダウンロードについて
以下のページからダウンロードすることができる
最新版をダウンロードするとよい
2.2. インストールのためにNode.jsが必要
以下のページからダウンロードします。
Node.jsについてや、そのインストール方法については以下の記事がわかりやすかったです。
2.3. 点群ファイルについて
LASやLAZ形式の点群ファイルを用意してください。
ファイル名が日本語の場合や、BoundingBoxの情報が破損している場合などはうまく表示できない場合があります。
3. Potree Desktopの基本的な操作方法
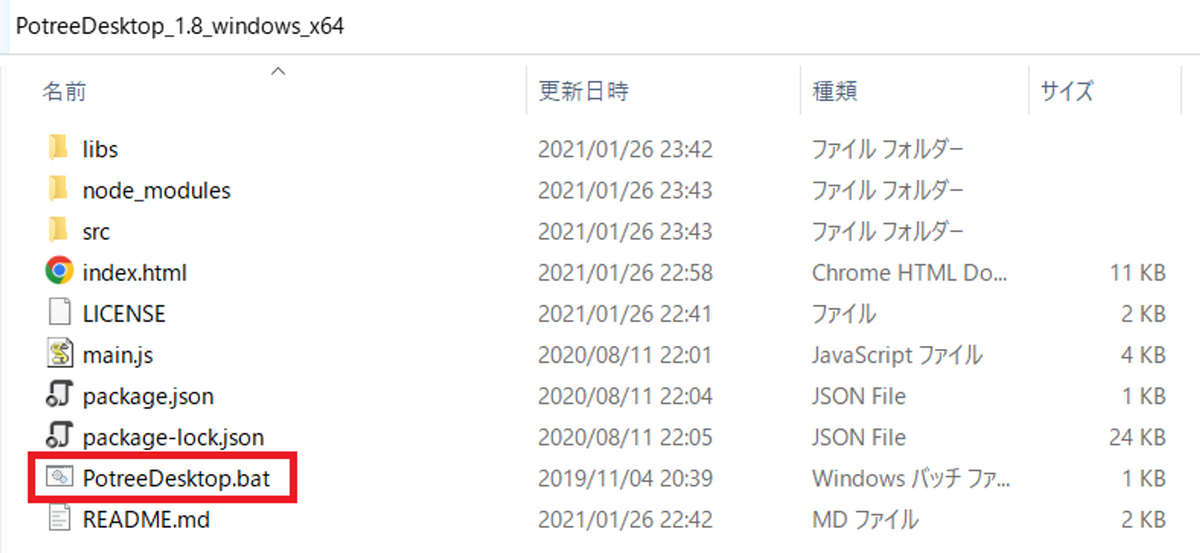
3.1. 立ち上げ
PotreeDesktop.batをクリックすると立ち上がる
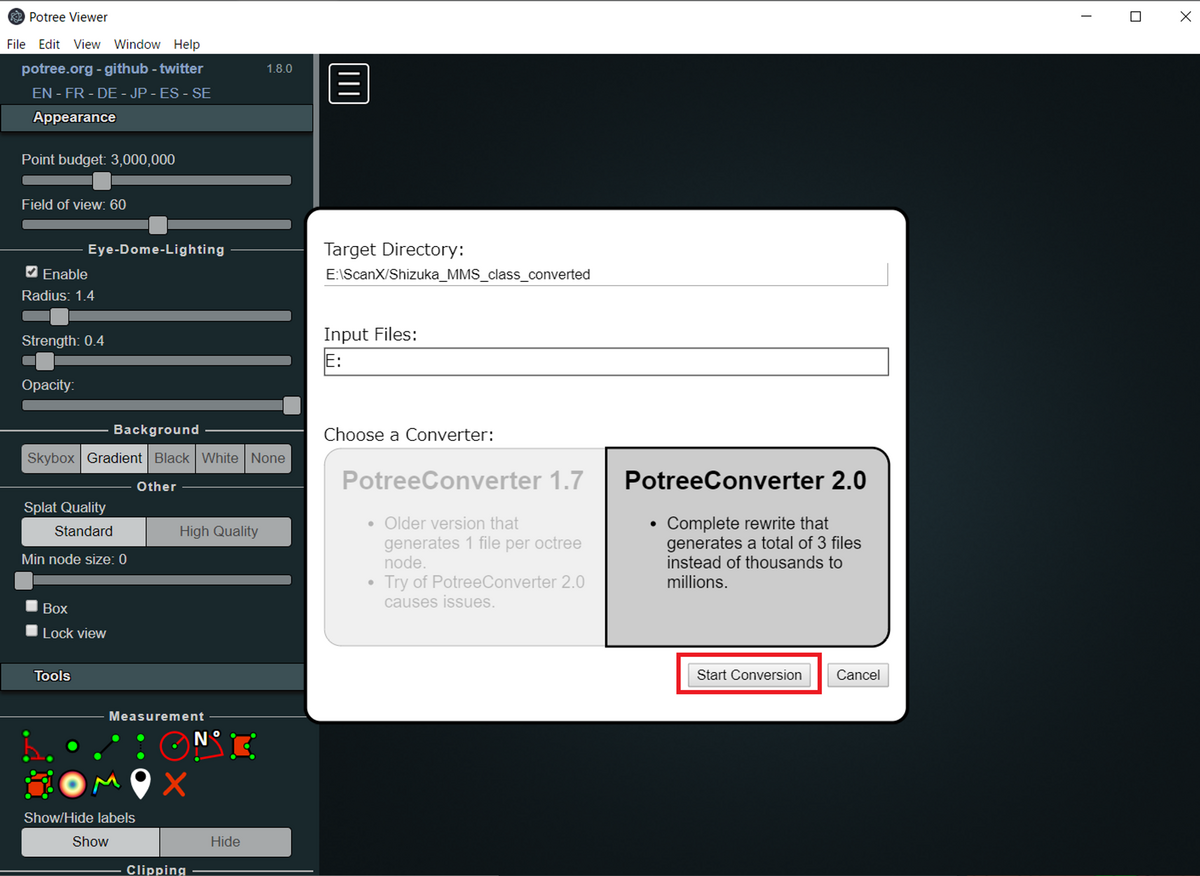
3.2. ファイルの読み込み
ドラッグ・アンド・ドロップにてファイルを読み込む
ファイルのパスに日本語が入っていると表示されない

3.3. Start Convertionをクリックする
3.4. 点群が表示される

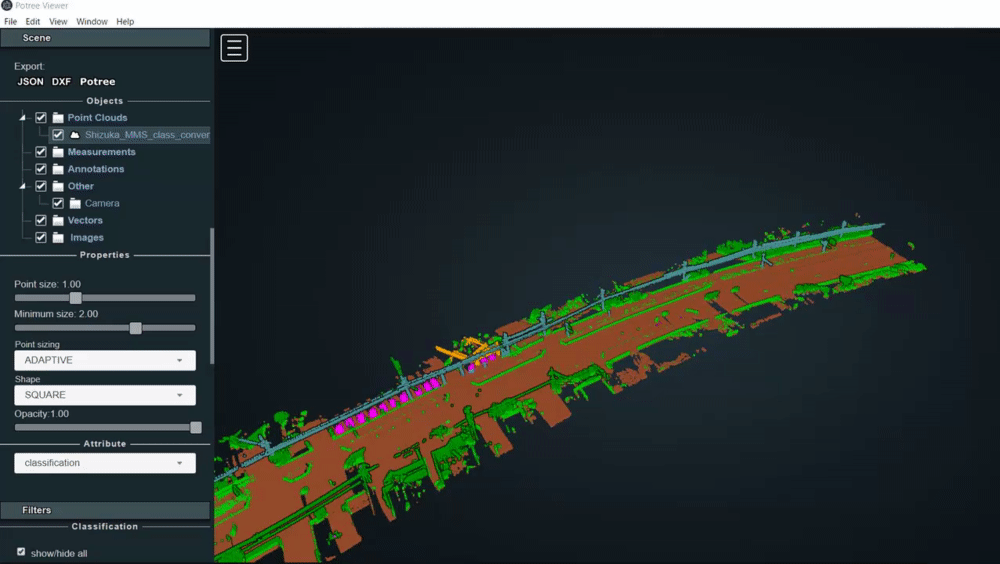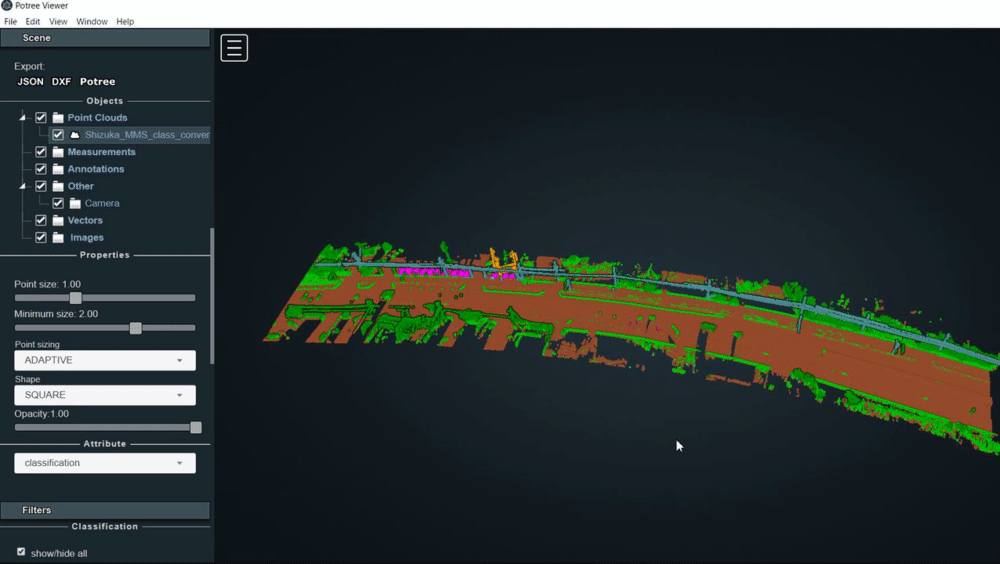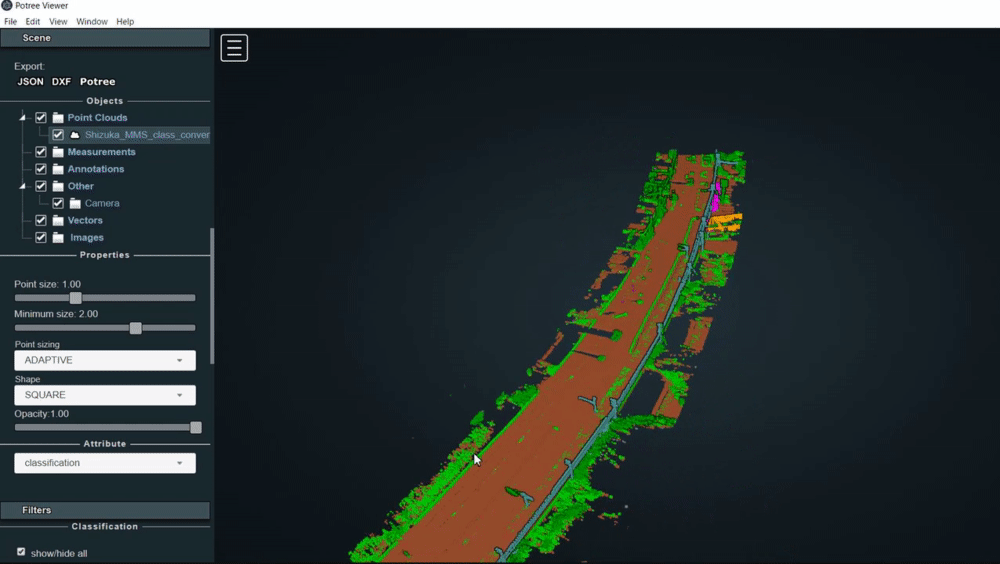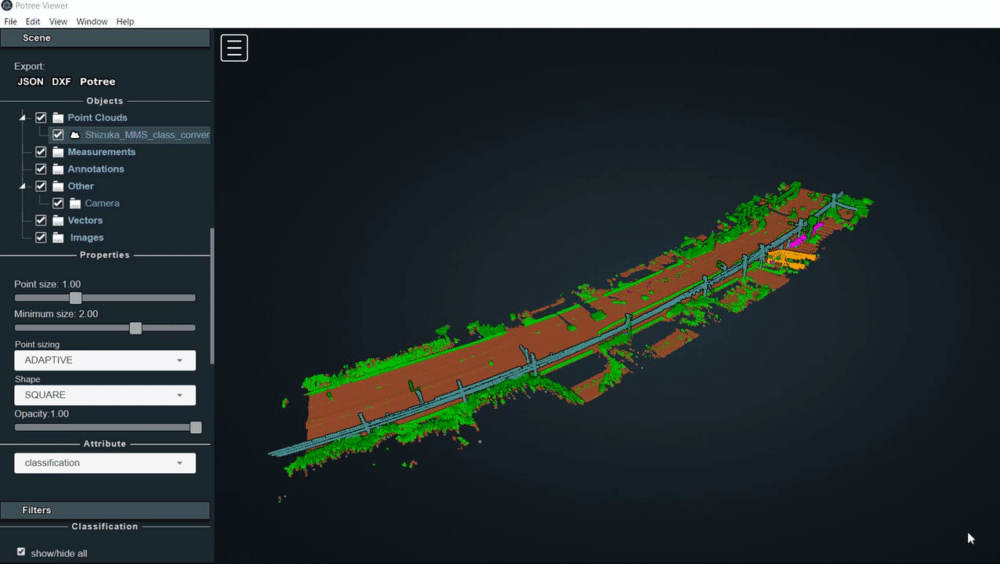
3.5. 分類情報を表示させる
PotreeDesktopでは、LASやLAZファイルの様々なフィールドの情報を可視化することができます。
例として、分類情報を表示する方法を述べます。
読み込んだ点群ファイル名をクリックする
classificationをクリックする

4. 便利な機能
4.1. 可視化
ダブルクリック拡大
- 左クリックをダブルクリックすることで、点群を拡大することが出来る
- 特に、マウスがない場合に便利
点群の高さごとの色分け
- elevationを使う
点群のクリップ
- キューブ内の点群をクリップすることが出来る
- 建物の裏側など、他の点と重なって見づらい対象を見る時に非常に便利な機能
4.2. 計測ツール
角度表示
- 角度表示機能で建物の角度を表示できる
- 建壁と地面の角度が約90度になっており、正確な角度を示していると考えられます。
- この機能を使用することで、円弧の中心角などの、一目ではわかりにくい角度も簡単に表示できそう
建物の高さを表示
- 高さの計測のアイコンを選択
- 直線を斜めに引いても、高さを正確に表示してくれるので、とても便利です
点群の長さ表示
- 長さの計測のアイコンを選択
- 複数個所の長さを簡単に図ることが出来て非常に便利
点群の体積表示
- 選択した範囲の体積を量ることが出来ます
- 直感的に操作しやすいレイアウトで、簡単に体積を計測することが出来る
5. その他
5.1. WEB公開の方法
以下の方法で点群をWEB公開できるそうです。DAIJUさまの記事です。
謝辞
本記事では、静岡県より公開されている VIRTUAL SHIZUOKA データセットおよび、東京都デジタルツインプロジェクトより公開されている点群を利用しました。
MATLABでVelodyne LiDARのデータを可視化してみよう
この記事はMATLAB/Simulink Advent Calendar 2023の15日目の記事として書かれています。
また、本記事のスクリプトなどは以下のページにアップロードされています。
はじめに
LiDAR(Light Detection and Ranging)は、主にレーザー光線を物体に照射することで対象までの距離を測定します。それにより、周辺の障害物を検知したり、その環境の3次元的な地図を作成したりすることができます。
LiDARは多くの種類がありますが、その中でもVelodyne LiDARが有名です。本記事では、Velodyne LiDARのパケットキャプチャ(pcap)ファイルを再生し、3次元点群データを可視化する方法について紹介します。
MATLABにてVelodyne LiDARのデータを可視化した時の様子を示します。MATLABを利用すれば、特別なセットアップも必要なく、簡単に可視化することができます。
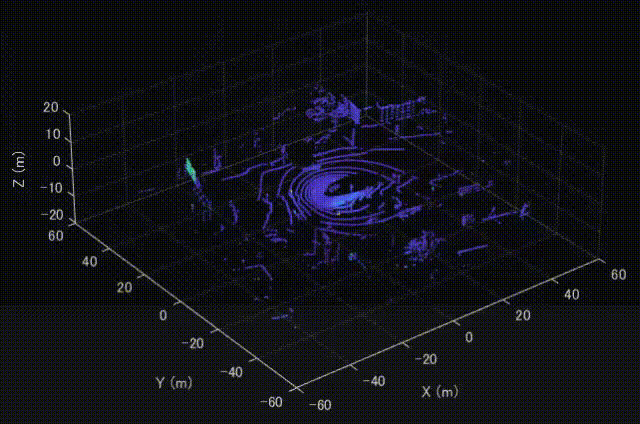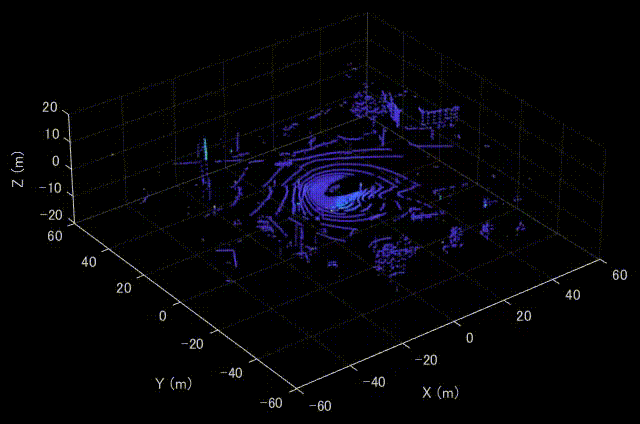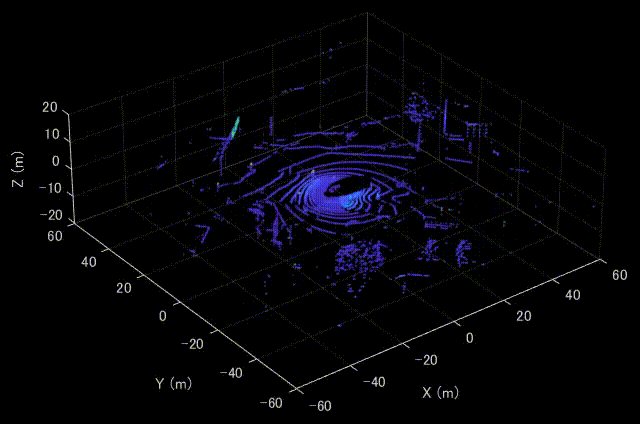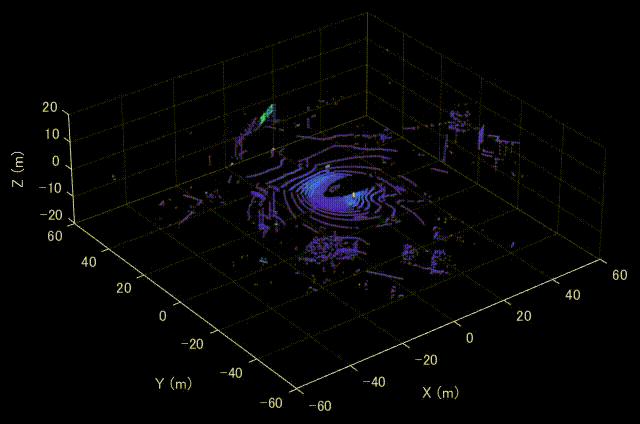
Velodyne HDL32Eについて
以下にVelodyne HDL32Eの画像を掲載します。

また、塩沢ら(2013)にてまとめられたVelodyne HDL32Eの性能について以下に掲載します。
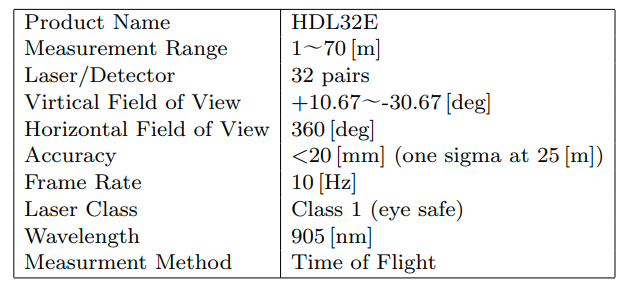
塩沢ら(2013): Velodyne レーザスキャナを用いた上空からの三次元再構成
その他のLiDARについてや、LiDARの利活用の例などについて以下のページがわかりやすかったです。
MATLABを利用したVelodyne HDL32Eデータの可視化
点群の可視化について
- pcplayer を利用して、時系列の点群データを再生することができます。
- xlimitsなどを定義することで可視化する点群の範囲を指定できます。
点群の読み取りについて
- velodyneFileReader を利用することで、Velodyne LiDARのデータを読み取ることができます。
- ここでは、HDL32Eという機種名を設定しました。
- readFrame 関数で1つずつ点群を読み取っていきます。
フレームごとの表示ついて
- view 関数で、さきほど定義したpcplayerを入力し、さらにそのプレイヤー上で見せる点群のXYZ情報や色付けするときのベースとなる反射強度(intensity)の情報を入力します。
まとめると以下のようになります。
clear;clc;close all % Velodyne Lidarデータの読み取りと可視化のためのMATLABコード % Velodyneファイルリーダーの作成 veloReader = velodyneFileReader('lidarData_ConstructionRoad.pcap','HDL32E'); % 可視化のための座標軸範囲の設定 xlimits = [-60 60]; ylimits = [-60 60]; zlimits = [-20 20]; % 点群データの可視化用のプレイヤーオブジェクトの作成 player = pcplayer(xlimits,ylimits,zlimits); % 座標軸ラベルの設定 xlabel(player.Axes,'X (m)'); ylabel(player.Axes,'Y (m)'); zlabel(player.Axes,'Z (m)'); % フレームごとにVelodyneデータを読み取り、可視化 for frameNumber = 1:veloReader.NumberOfFrames % フレームごとの点群データの読み取り ptCloudObj = readFrame(veloReader, frameNumber); % 点群データの可視化 view(player, ptCloudObj.Location, ptCloudObj.Intensity); % 表示の更新と一時停止(0.1秒) pause(0.1); end

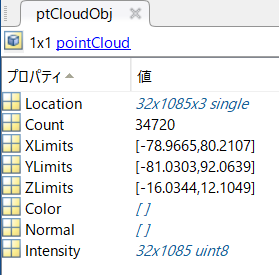
pointCloudオブジェクトの中身について
ここで、上で読み取った点群のフレームについてもう少し見てみます。
読みっとった点群はpointCloudオブジェクトとして読み取られます。
そこでは、点群を構成する点のXYZ情報(Location)や点の数(Count)、範囲(Limits)や色情報や法線ベクトルの情報、反射強度が格納されています。
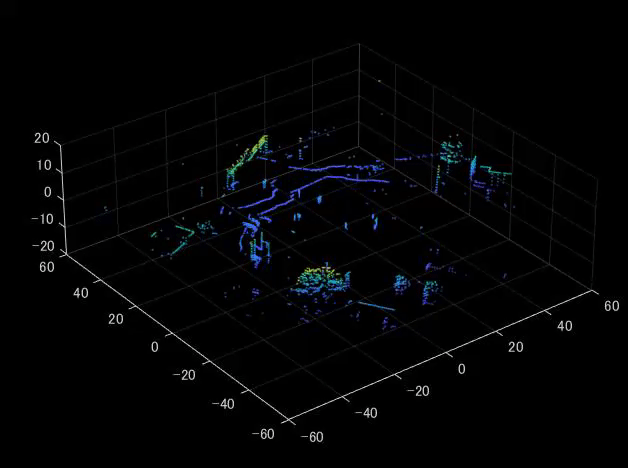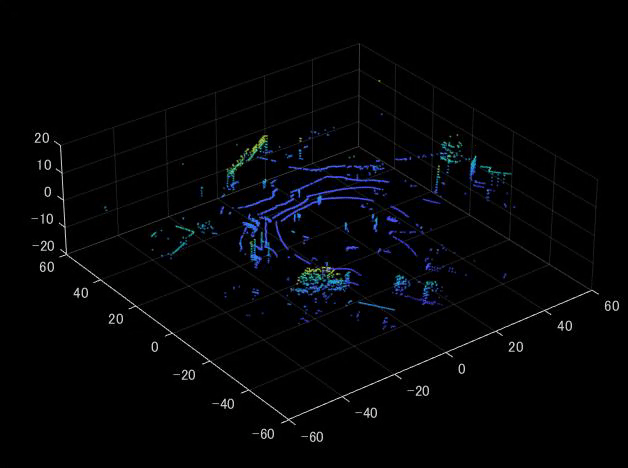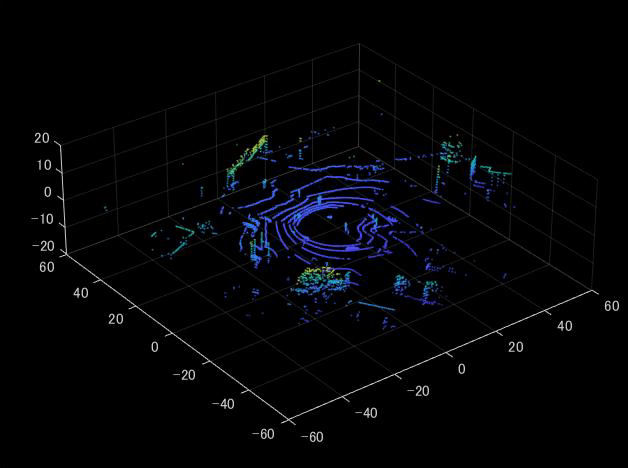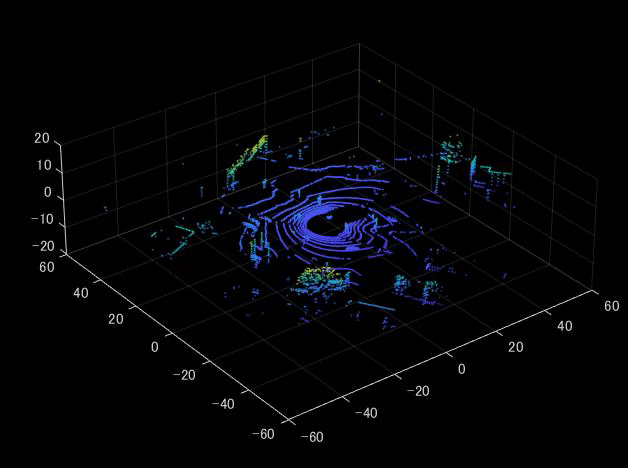
Locationが以下の図では32×1085×3になっています。これは何でしょうか。
以下の図は、Velodyne VLP16の図です。16 beamsとあるように、
上下方向に16本のレーザービームがあり、それが高速に(10Hz)回転しています。
ここでは、Velodyne HDL32Eを利用しているため、32本のレーザービームごとに点が分かれていることを示しています。

それでは、32本のレーザービームを上から読み取って、可視化していきます。
% 新しいfigureを作成し、ライブスクリプトの外側で表示するように設定 figure('Visible','on'); % 1から32までのスキャンIDにわたるループ for scanId = 1:32 % ptCloudObjから指定されたスキャンIDに対応する点群データを取得 scan_i = ptCloudObj.Location(scanId,:,:); % 3D行列から2D行列に変換 scan_i = squeeze(scan_i); % 新たに点群を表示し、現在の点群を保持 pcshow(scan_i);hold on; % x、y、zの軸範囲を指定 xlim(xlimits); ylim(ylimits); zlim(zlimits) % 描画を更新 drawnow; end
実行すると、以下のように上側のスキャンから点群が可視化されていくことがわかります。
まとめ
この記事では、Velodyne LiDARのデータをMATLABを利用して可視化する方法について紹介しました。便利な関数が多く用意されており、特別なセットアップもなく、可視化ができました。
その他
この記事は、MATLABのライブスクリプトを利用して執筆されました。ライブスクリプトにてテキストや図、コードを書き、以下のコマンドで、マークダウン形式にエキスポートしています。
このマークダウン形式のデータをはてなブログにコピーアンドペーストすると効率よくブログ執筆を行うことができます。
export("visualizeHDL32E.mlx","README.md","EmbedImages",false)
参照座標系(EPSGコード)について
この記事はMATLAB/Simulink Advent Calendar 2023の16日目の記事として書かれています。
1. はじめに
3次元点群データは、XYZの点の集まりで表現されますが、「地球上での位置」を示すこともできます。
以下の図は、無料のGISソフトウェアであるQGISを利用して、地図上に3次元点群データを表示しています。
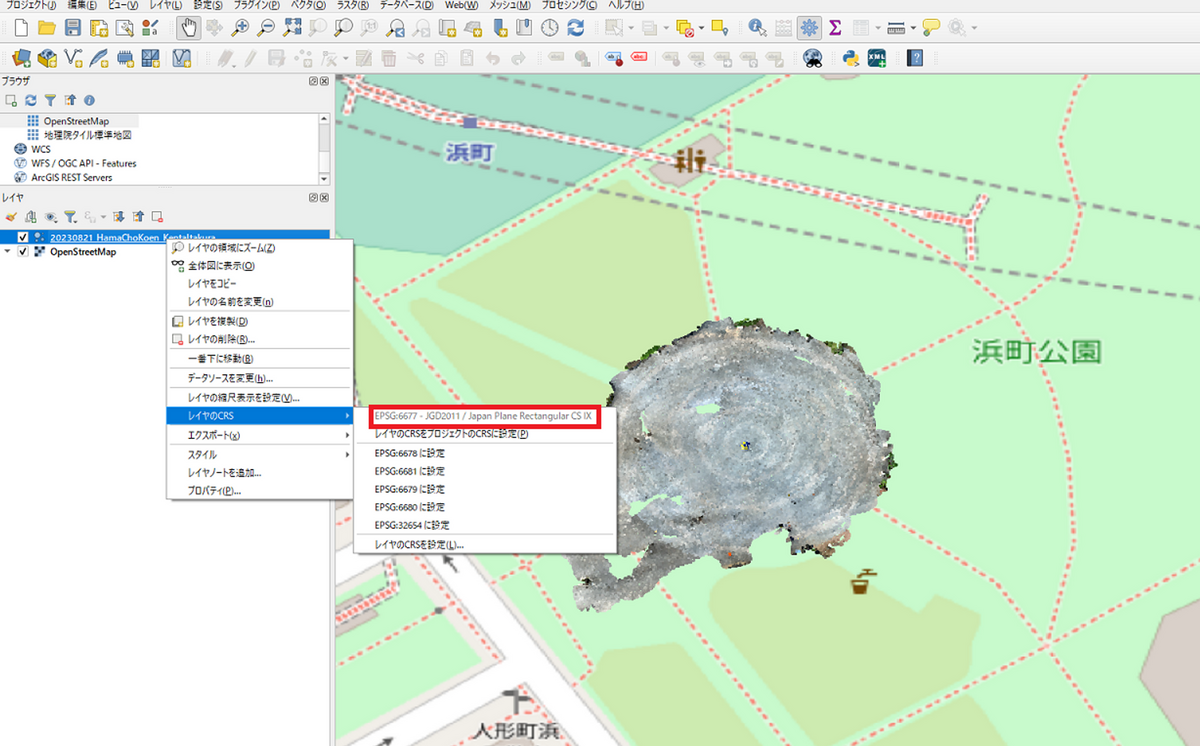
この際に、座標参照系(CRS)やEPSGコードというものを設定する必要があります。
この記事では、3次元点群データを地図上で見るために必要な座標参照系(CRS)やEPSGコードについてまとめます。
3次元点群データはiPhoneに搭載されたLiDARを利用して取得することもできます。
3次元点群データをiPhoneからエキスポートする様子については以下の記事をご覧ください。
2. EPSGコードについて
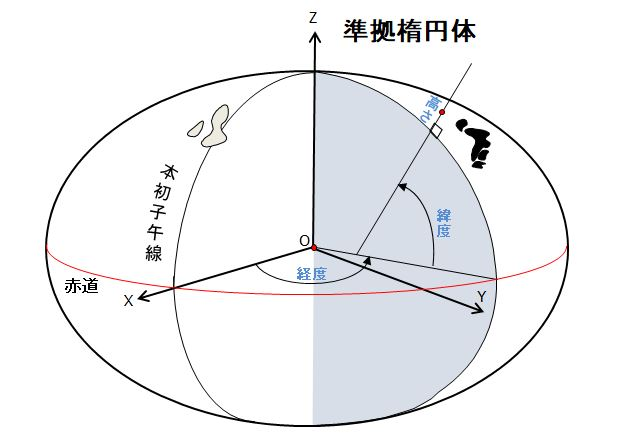
2.1. 地球上での点の位置を表す
取得した点群を地図上で表示させるためには、その点群が地球上のどこに位置するかを表す必要があります。以下の図のように、地球上の位置は、経度や緯度、高さの情報などを用いて表すことができます。以下の図では、きれいな楕円体の中での、位置を求めていますが、実際は、場所によって高低差があったり、複雑な地形をしていたり、単純に楕円体で地球を表すことは簡単ではありません。
また、シンプルかつ、地球の形状をうまく表現する楕円体を用意したのち、3次元的な地球(儀)で位置を表現するよりも、一部の領域であれば、2次元の平面に投影してしまっても実用上問題はありません。このように地球上での点群の位置を表すためにはいくつか方法があり、どのような方法をもとに表しているかを示す番号(のちに説明するEPSGコードに相当)があると便利そうです。地球上での位置を表す方法について、測地系と座標系に分けて説明します。
2.2. 測地系
測地系とは
- その経度・緯度の座標で表す時の座標の基準(点)
- 地球を楕円体とみなすときの形状
などを定義するための基準です。これにより、地図を作成する時や、測量時において、共通して地球上の位置を表現することができます。これにより、点群を正しく地図上で閲覧することができます。
測地系の中でも、世界測地系や局所測地系などが存在します。世界測地系は、国際的に定められた測地系です。一方、局所測地系は、その地域の近傍に対して適用できる測地系です。
局所測地系の例として、改正測量法の施行前は、明治時代に採用したベッセル楕円体という楕円体を地球を表すために用いていました。そして、これをもとにして、東京天文台の経度・緯度が、天文観測にて求められ、日本の原点の位置として決められました。
その後、VLBIや人工衛星などの技術の進歩により、より正確な地球の形状や大きさが求められるようになり、地球全体によく適合した測地基準系として、世界測地系が構築されました。
2.3. 座標系
地球上の点の座標を定める上で、測地系の他に、座標系について考える必要があります。座標参照系は大きく分けて、「地理座標系」「投影座標系」の2種類があります。この節では、この2種類の座標系について述べます。
2.3.1 地理座標系
地理座標系では、その点の位置を経度や緯度を用いて表します。
2.3.2 投影座標系
投影座標系では、一部の(限られた)範囲を2次元の平面へ投影する狭い範囲の一部を平面へ投影したときの座標を示します。ここでは、その投影した時の原点からのx方向およびy方向の値をもって、その点の位置を示すことができます。

投影の方法は複数存在し、以下の図のように
- 円筒図法
- 円錐図法
- 方位図法
といった投影方法が存在します。
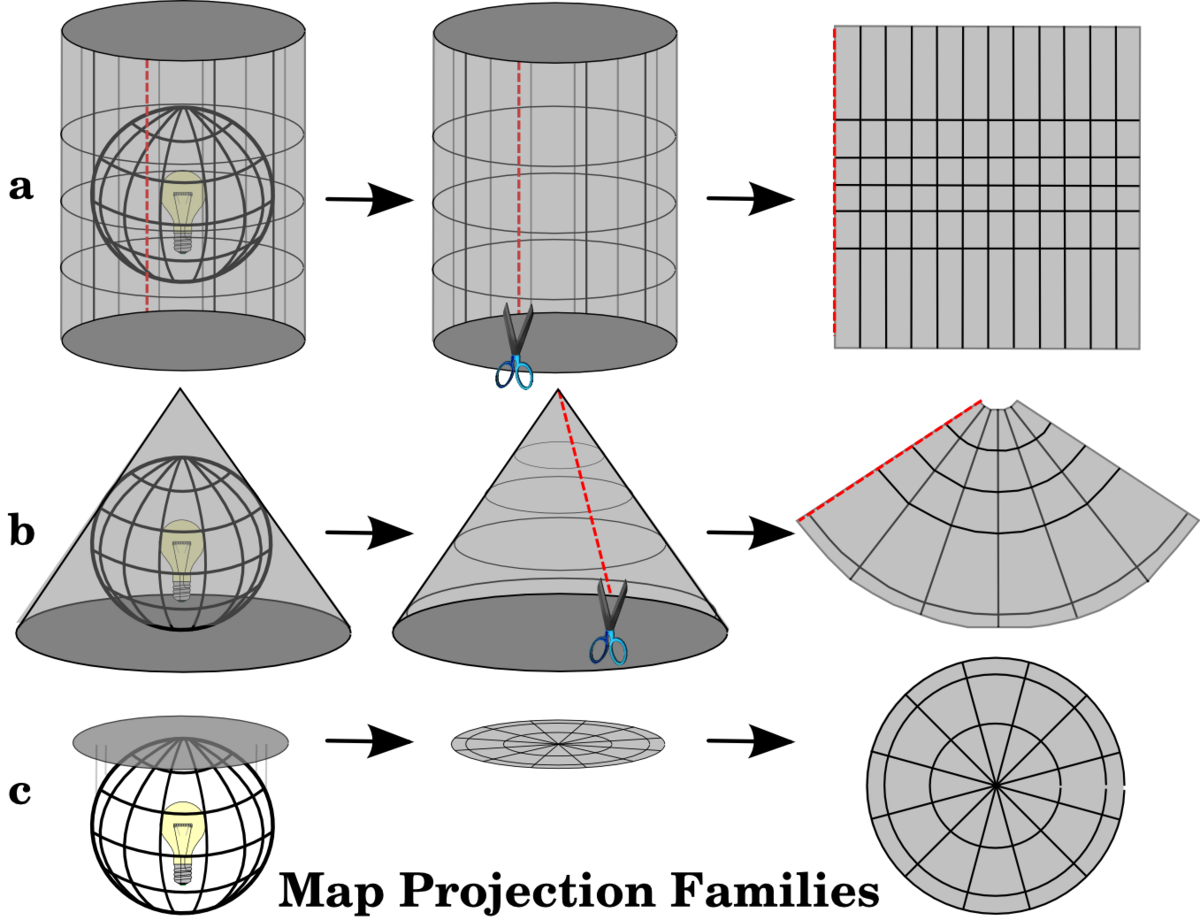
図出展: QGI documentation Coordinate Reference Systems ********(https://docs.qgis.org/2.8/en/docs/gentle_gis_introduction/coordinate_reference_systems.html)
2.4. 空間参照系
2.2で述べた測地系や2.3で述べた座標系の組み合わせによって、空間参照系を定義することができます。
測地系では、
- 地球を楕円体とみなした時の形状の詳細
- 楕円体とみなした時の原点
などが決められ、
座標系では、
- 経度や緯度を用いて表す
- 投影座標を用いて表す
- どのような投影方法を用いるのか
- どの場所を投影するときの原点とするのか
といったことが決められるのでした。
このような掛け合わせを経て、地球上の点の位置を定めるためのパターンは非常に多く存在します。そこで、空間参照系を識別するためのコードがあると便利です。

本図は、地図のワークブック 空間参照系(測地系/座標系/投影法)について (https://lonlat.info/spatialreferencesystem/) を参考に作成されました。
3. MATLABで点群の座標を経度・緯度に変換する
MATLABで点群の位置座標を変換してみます。データは、iPhone LiDARのアプリである、iPhone LiDARのアプリである、Scaniverseを利用して取得された点群を利用します。 主に、Mapping Toolboxを利用します。
以下のように対象の点群をMATLAB上でくるくると回すことができます。Scaniverseで取得された取得された点群をLAS形式でエキスポートした場合、UTM座標系が利用されます。

この点群のXYZ座標を読み取り、経度・緯度に変換したいと思います。
利用した点群データは以下にアップロードされています。ぜひダウンロードして、以下のコードを実行してみてください。
流れは以下の通りです。
- readPointCloud 関数を利用して点群の読み取り
- projcrs 関数を利用して、UTM54Nの projcrs オブジェクトを作成する
- projinv 関数を利用して、UTM54Nの座標を経度・緯度に変換する
- geoscatter 関数を利用して、地図上にプロット
clear;clc;close all % las/lazファイルを読み込むためのlasFileReader objectを作成する lasReader = lasFileReader('treeTrunk.laz'); % las/lazファイルの、xyzおよび色情報を読み込み ptCloud = readPointCloud(lasReader); % projcrsオブジェクトを作成する utm54N = projcrs(32654); % projinv 関数を利用して、UTM54Nの座標を経度・緯度に変換 [lat,lon] = projinv(utm54N,ptCloud.Location(:,1),ptCloud.Location(:,2)); % スムーズに可視化するため、点をサンプリング idx = randperm(ptCloud.Count,100000); % 色の取り出し ptCol = ptCloud.Color(idx,:); % 地図上にプロット geoscatter(lat(idx),lon(idx),1,single(ptCol)./2^16)
以下のようにプロットすることができました。軸ラベルを見ると、単位が、経度・緯度になっていることがわかります。

参考ページ
地図のワークブック 空間参照系(測地系/座標系/投影法)について
3次元点群の形式の1つであるE57ファイルについて
はじめに
この記事はMATLAB/Simulink Advent Calendar 2023の9日目の記事として書かれています。
LiDARなどにより取得される3次元点群ファイルの有名なフォーマットにe57があります。
e57は、XML データ形式に基づいて点群や各種データを階層ツリー構造で格納します。米国試験材料協会 (ASTM) によって定められています。
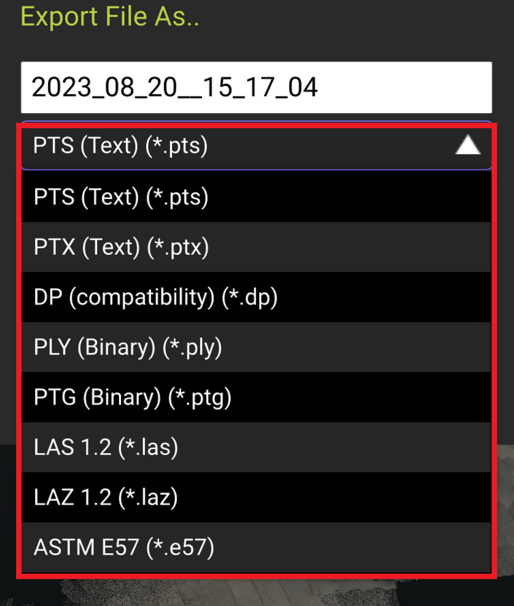
例えば、Leica社のCycloneで点群をエキスポートするときや、iPhone LiDARのアプリである、Dot3Dで点群をエキスポートするときにE57形式を選択することができます。
以下の図は、Dot3Dで点群をエキスポートするときの様子です。一番下にE57があることがわかります。
E57形式について
E57は、ヘッダー、バイナリーセクション、XMLセクションに分かれています。

画像出典:e57FileReader
https://jp.mathworks.com/help/lidar/ref/e57filereader.html
ヘッダーには、バージョン番号や、ファイルのフォーマットの名前などの情報が格納されています。
MATLABでE57形式の点群を読み込むと以下のようになります。
また、データ構造は以下のようになっています。Dota3Dという3次元的なデータと、Images2Dとあるような2次元的なデータに分かれています。高密度点群の標準的なフォーマットであるLAS形式の違いとして、スキャンごとの点群やその点群を取得した時の位置や姿勢、また、画像に関する情報が分かれていることが挙げられます。
LAS形式では、スキャンごとの点群は合成され、また、各点にRGBの色情報が投影された状態で保存されます。

画像出典:e57FileReader
https://jp.mathworks.com/help/lidar/ref/e57filereader.html
E57形式では、点群がスキャンごとに保存されるので、例えば以下のように2か所から計測した場合は、それぞれの点群とその時のスキャナの位置や向き、画像などが計測されます。
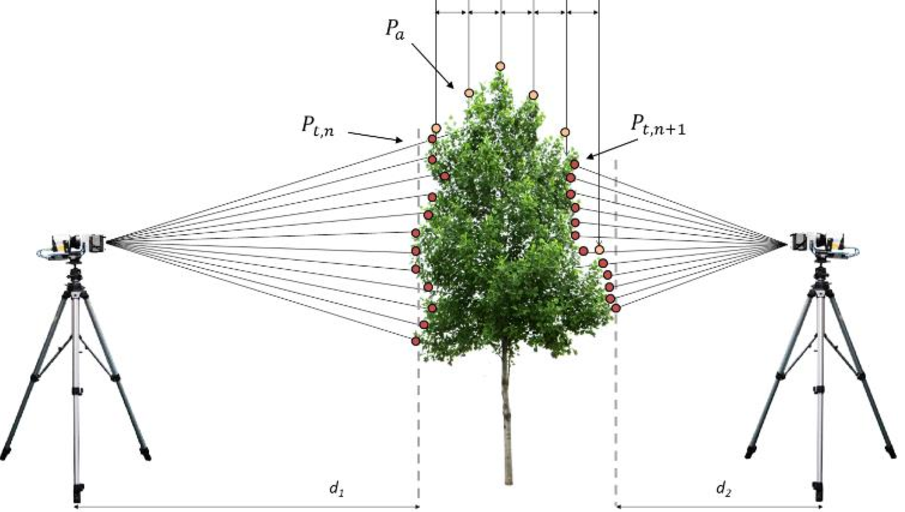
画像出典:Paris, C., Kelbe, D., Van Aardt, J., & Bruzzone, L. (2017). A novel automatic method for the fusion of ALS and TLS LiDAR data for robust assessment of tree crown structure. IEEE Transactions on Geoscience and Remote Sensing, 55(7), 3679-3693.
E57に関して、以下の記事がわかりやすかったです。
Interoperability around the E57 Scanning Format
https://www.cadinterop.com/en/formats/cloud-point/e57.html
姿勢情報について
E57形式ではスキャンが行われた時の位置や向きが格納されていると述べました。
MATLABでE57形式の点群を読み込み、さらに、Data3Dから姿勢情報を読み取りました。
また、点群とその姿勢情報(スキャンしたときのデバイスの位置と向き)を可視化しています。
表示における技術的な内容や、MATLABでのコーデイング方法については後述しています。
なお、このE57形式の点群は、iPhone LiDARのアプリである、Dot3Dを利用して取得されました。
Dot3Dを利用したスキャンの方法やエキスポートの方法については以下の記事をご覧ください。
デバイスの位置と向きはカメラのアイコンで示しています。iPhone LiDARのデータであるため
スキャンしたポイントが多く、たくさんのカメラのアイコンが表示されています。

近くで見ると、オレンジの枠で囲われた場所では、奥の自動販売機をスキャンしていて、
青色の場所では右側の自動販売機をスキャンしていることがわかります。

このように、それぞれスキャンされた点群とその位置や姿勢がわかるため、それらをつなぎ合わせることで、
1つの高密度な点群を合成することができます。
例えば、以下の画像では、3つのスキャンのみをランダムに取り出して、その姿勢情報を利用して変換することでうまくつなぎ合わせています。
赤色は自動販売機、青色は天井、緑はエレベーターをそれぞれスキャンしていることがわかります。
このような操作をE57形式の点群に含まれるすべての点群に対して繰り返すことで、スキャン全体の点群を得られます。

以下の動画は、iPhone LiDARにより取得された点群をスキャンごとに取り出し、さらにその時の位置とiPhoneの姿勢の情報を利用して重ね合わせています。
最終的に生成されたデータをアプリ上ではエキスポートすることができます。

回転と移動の行列について
E57ファイルには、スキャンした時のデバイスの位置や向きが格納されていますが、その表し方について説明します。
以下の図は2つのカメラの位置関係を示しています。この時、左のカメラの位置を基準として、右のカメラの位置を示すことを考えます。カメラを回転させる行列と平行移動させる行列があればそれを実現することができます。
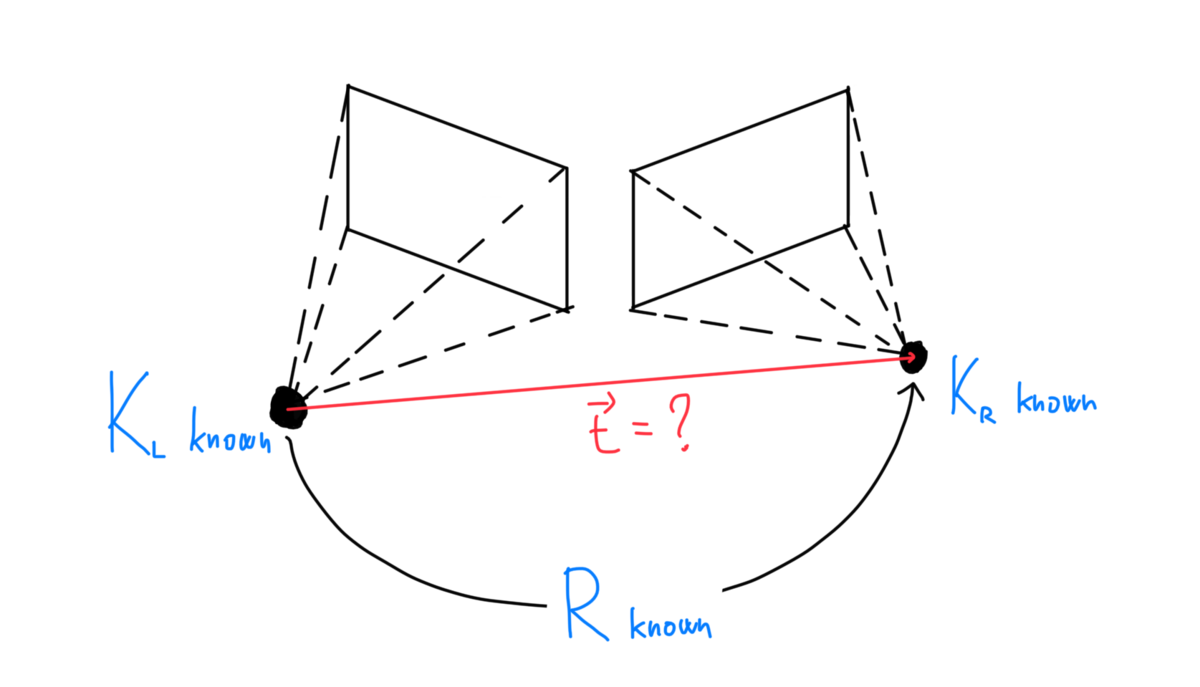
回転行列は3次元上で行うと3×3になり、平行移動は3×1です。それらを合わせると以下のような行列になります。
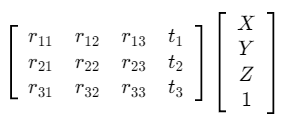
MATLABにて実践する
それでは、実際に上記の作業を行ってみます。
ポイントとして、以下のことが挙げられます。
- e57FileReader と readPointCloud で、E57形式の点群を読み込む
- pcMetadataにある、RelativePoseから姿勢情報の行列を取得する
- 行列の情報をもとに、点群を変換する
- 行列の情報をもとにデバイスの位置と向きを可視化する
また、ここでのサンプルファイルを以下に格納しています。適宜ダウンロードしてお使いください。
https://drive.google.com/file/d/1Ym1e2t5u6vcMlrsblqmGA3Q7RNi54mZp/view?usp=sharing
clear;clc;close all % e57ファイルから点群データを読み込むためのe57Readerオブジェクトを作成します。 e57Reader = e57FileReader("lobby.e57"); % 点群データ(ptCloudArr)および対応する姿勢(tformArr)を格納するための変数を初期化します。 ptCloudArr = []; tformArr = []; % 点群データを読み取ります。 for i = 1:e57Reader.NumPointClouds % e57ファイルからi番目のフレームの点群データ(ptCloud)とメタデータ(pcMetadata)を読み込みます。 [ptCloud, pcMetadata] = readPointCloud(e57Reader, i); % 各点群データと対応する姿勢をそれぞれの配列に追加します。 for j = 1:numel(ptCloud) ptCloudArr = [ptCloudArr ptCloud(j)]; tformArr = [tformArr pcMetadata.RelativePose]; % 相対姿勢を用いてカメラをプロットします。 cam = plotCamera(AbsolutePose=pcMetadata.RelativePose, Opacity=0, Size=0.1); hold on end end % 点群データと対応する姿勢を用いて点群の合成を行います。 pcMap = pcalign(ptCloudArr, tformArr); % 合成した点群を表示します。 figure;pcshow(pcMap)
補足
デバイスが3つだけ可視化された画像を作成するためのコードを示します。
ptCloudArr = []; tformArr = []; absTform = rigidtform3d; % 点群データを読み取ります。 figure; indices = [1 100 170]; colorList = {"red","blue","green"}; for ii = 1:3 i = indices(ii); [ptCloud,pcMetadata] = readPointCloud(e57Reader,i); for j = 1:numel(ptCloud) ptCloudArr = [ptCloudArr ptCloud(j)]; tformArr = [tformArr pcMetadata.RelativePose]; color_i = colorList{ii}; cam = plotCamera(AbsolutePose=pcMetadata.RelativePose,Opacity=0,Size=0.1,Color=color_i);hold on end end pcMap = pcalign(ptCloudArr,tformArr); pcshow(pcMap)

SOLOv2を利用した猫のセグメンテーション
はじめに
この記事はMATLAB/Simulink Advent Calendar 2023の2日目の記事として書かれています。
SOLOv2とは
画像中の物体ごとに色塗り(インスタンスセグメンテーション)をするネットワークです。
インスタンスセグメンテーションの有名な方法として、この他にMask R-CNNなどが知られています。
SOLOについては以下の記事がわかりやすかったです。
MATLABではSOLOv2モデルを非常に簡単に動かすことができます。

本記事ではSOLOv2を利用して以下のようなセグメンテーション結果を得る方法ついて説明します。また利用したコードや動画は以下のページに格納しています。
MATLABでSOLOv2を実行する
前準備:アドオンのインストール
はじめに、Computer Vision Toolbox Model for SOLOv2 Instance Segmentation をインストールしておく必要があります。
コードの実行
動画に対して、SOLOv2のモデルを実行し、猫の部分を色塗りしてみます。
ポイントは以下の通りです。
- solov2関数でSOLOv2モデルを読み込む
- segmentObjects関数で画像に対してSOLOv2を実行する
clear;clc;close all % solov2関数でSOLOv2モデルを読み込む net = solov2("resnet50-coco",InputSize=[800 800 3]); % 猫の動画を読み込む準備 catVideo = VideoReader("catVideo.mp4"); % 出力結果を保存する準備 v = VideoWriter('segmentationResult.avi','Motion JPEG AVI'); v.FrameRate = 10; open(v) % 猫を塗る色の指定 maskColors = "blue"; % ビデオから1フレームずつ読み取り、SOLOv2を実行 while hasFrame(catVideo) % フレームの読み込み frame = readFrame(catVideo); % フレームのリサイズ frame = imresize(frame,[800 800]); % SOLOv2の実行 [masks,labels,scores] = segmentObjects(net,frame,Threshold=0.2); % 猫のマスクの取り出し catMask = masks(:,:,labels=="cat"); % 猫のエリアの可視化 overlayedMasks = insertObjectMask(frame,catMask,MaskColor=maskColors,Opacity=0.3); % 画像の表示 imshow(overlayedMasks); % 動画への書き込み writeVideo(v,overlayedMasks) end close(v)