露出補正の最先端手法を勉強&動かしてみた (Afifi et al., CVPR, 2021)
はじめに
この記事は、MATLAB/Simulink Advent Calendar 2021(カレンダー2)の25日目の記事として書かれています。
間違いなどがあれば、教えていただけますと幸いです。 こちらの記事で用いたコードはこちらにアップロードしています。勉強会やまとめ資料用、ゼミ活動など、何かの役に立てば嬉しいです。
ここでは、低解像度の画像を高解像化する手法について勉強したため、そのまとめとして紹介します。詳細はもとの論文である、Maffi et al (2021) をご覧ください。
今回の課題
明るい写真
こちらの写真は、夜に大学のある建物を撮影したものです。キレイではありますが、少し明るすぎますね。iphoneで撮影するときに明るくしすぎてしまったようです。せっかくのいい風景なので、いい感じに明るさを補正したいです。

暗い写真
次は三毛猫です。呼ぶと布団の中まで遊びに来てくれます。とてもかわいいです。しかし、布団の中ということもあり、とても暗いです。せっかくのいい写真なので、こちらも明るく、そして三毛猫の3つの色をきれいに補正して見てみたいです。

参考:写真・動画撮影で重要な露出(露光)について理解しよう
露出補正
以下の画像は、出典情報にもあるとおり、一眼レフの教科書さまからの引用です。上の建物と猫の画像では、カメラに入る光の量がうまく調整できておらず、明るすぎ/暗すぎる状態になっています。本来的には、以下の画像のように、カメラのパラメータや撮影方法を変更して最適な明るさで撮影されるべきですが、目的に応じて、後から補正したくなった/その場のカメラ/スマホのディスプレイの感じだとよくわからなかった、ということもあろうかと思います。

画像出典:一眼レフの教科書「一眼レフ初心者必見!露出補正で写真表現力を身につける」
深層学習による補正
カメラのパラメータの調整やHDRなど、適正な明るさの画像を取得する方法はありますが、ひとまず、それらは置いておいて、深層学習によって後処理的に露出補正することを本記事では考えます。
本論文のイントロダクションの和訳
露出補正について学ぶために、本論文のイントロダクションを和訳してみます。
撮影時の露出は、最終的な写真の明るさに直接影響する。デジタルカメラでは、主に次の3つの要素で露出を制御している。①シャッタースピード、②F値、③ISO値(受信画素信号の増幅率を制御する)の3つで行われます。 写真撮影では、露出設定を露出値(EV)で表し、各EVは同じ露出効果をもたらすカメラのシャッタースピードとF値の異なる組み合わせを意味する。写真撮影では「等光露出」とも呼ばれる。
デジタルカメラでは、撮影した画像の明るさを変化させる目的で露出値を調整することができる。この調整は、ユーザーが手動で行う場合と、自動露出(AE)モードで自動的に行われる場合がある。AEを使用する場合、カメラは、シーンから受け取った光の量を測定するTTL(Through-the-Lens)モードを用いて、撮影したシーンの明るさの低さや高さを補正するために露出の度合いを調整する[53]。
露出のエラーは、TTL測光の測定誤差、難しい照明条件(極端に低い照明や逆光など)、シーンの輝度レベルの急激な変化、ユーザーによるマニュアルモードでの誤差など、いくつかの要因で発生する。このような露出のエラーは撮影の初期段階に起こるもので、最終的な8bitの画像をレンダリングしたのちに補正することは困難である。なぜなら、最終的な8bitの標準RGB(sRGB)画像[32]をレンダリングするために、カメラのISP(イメージ・シグナル・プロセッサー)が高度な非線形演算を行うためである。
図 1 は、露出エラーのある画像の典型例である。図1において、露出誤差は、最終的なレンダリング画像において、露出オーバーによる非常に明るい画像領域、または、露出アンダーによる非常に暗い領域のいずれかを生じさせる。このような誤差のある画像を補正することは、定評のある画像補正ソフトウェアパッケージをもっても困難な作業である(図9参照)。露出オーバーと露出アンダーはともに写真撮影ではよくあることであるが,先行研究のほとんどは,主に露出アンダーのエラー[23, 60, 62, 70, 71]の修正,または一般的な画質向上[10, 17]に絞って議論している。
貢献
我々は、露出オーバーと露出アンダーともに適用可能な、coarse-to-fineなディープラーニング手法を提案する。我々のアプローチでは、露出補正問題を2つの主要な問題に分けて定式化する。(i) 色彩補正と(ii)詳細補正である。エンドツーエンドで学習可能なディープニューラルネットワーク(DNN)モデルを提案し、グローバルな色情報を補正することから始め、その後、画像の細部を補正する。ここで提案するDNNモデルに加え、露出補正問題への重要な貢献は、これまでのデータセットよりも広い露出範囲を持つ異なる露出設定でraw-RGBからsRGBにレンダリングした24000枚以上の画像を含む新しいデータセットである。このデータセットに含まれる各画像には、対応する適正露出の参照画像がペアとして利用可能である。最後に、提案手法の評価とablation studyを、最新の技術とも比較しながら行う。本手法は、露出アンダーの画像に特化した従来の手法と同程度の結果を達成し、露出オーバーの画像では大幅な改善をもたらすことを実証する。さらに、我々のモデルは、我々のデータセット以外の画像に対しても良好に汎用化することができる。
その他の先行研究もまとめたかったのですが、時間の都合上割愛させていただきます。後日追記できればと思います。下の図は、Maffi et al (2021) の図1からの引用です。左上の、露出オーバーの画像は、右上のように補正され、左下の露出アンダーの画像は右下のようにうまく補正されています。

試してみた結果
以下の図は、この論文の手法を自分のデータで試した時の結果です。
この論文の著者によるオリジナルの実装は以下のgithubレポジトリにあります。
左側の画像はカメラに入るカメラが多く、全体的に白くなってしまっています(露出オーバー)。右側の画像では、それらの色が補正され、より美しい画像になっていることがわかります。

一方、以下の例は、右側の画像が非常に暗い場所で撮られていて、画像全体が非常に暗いことがわかります(露出アンダー)。

左側の画像は、ここで紹介する手法によって補正されたときの結果です。三毛猫の色も非常に忠実に再現されていて、大変うまく補正ができていることがわかります。
以下のリンクでは、自分で左右の線を動かすことができるので、ぜひ試してみてください。
これらのように、明るすぎた/暗すぎた画像もうまく補正できていてすごいです。三毛猫にいたっては、三毛猫の3つの色もほぼ完ぺきに再現できていて、驚くばかりです。深層学習では、その特定のデータセット内ではうまく行っても、新規のデータ(布団の中に入ってきてくれた猫)にはうまく行かないことも多いのですが、今回は、ここでお見せした画像以外でもうまく行っています。
この手法のポイント
簡単にポイントを述べると
- 深層学習による方法で、適正露出の画像と露出オーバー/アンダーの画像をペアにして学習させている
- 露出オーバー/アンダーの画像のどちらともに対応できる
- 入力の画像をラプラシアンピラミッドにより、異なる周波数特性を持つ画像に分解し、訓練/推論させている
- ラプラシアンピラミッドにて、画像を異なる周波数成分の画像に分解し、それぞれに対して補正を行うことで、1) 色の補正、2) 詳細の補正をうまくネットワークに分担させている
- 前回のブログ記事で紹介したような、image-to-image回帰的な方法に加え、GANの技術(Adversarial Loss)を導入し、精度を向上させている
などといったことが挙げられると思います。
この手法のポイント:ラプラシアンピラミッドについて
下の図は、もとの論文の図3より引用しています。図Aは露出オーバーの画像と、そこから得られるラプラシアンピラミッド、図Bは適正露出の画像とそのラプラシアンピラミッドです。一方、図Cは露出オーバーのAの画像のラプラシアンピラミッドの最後のピラミッドのみをBの者と入れ替え、再構成をしたときの結果です。Dは最後の2つを交換し、再構成したときの結果です。色味に関しては、ラプラシアンピラミッドの最後の成分を補正すればうまく、露出の補正自体も行えそうです。つまりこの手法では画像を各周波数成分に分解し、それらを補正することを目指します。

ラプラシアンピラミッドについてもう少し詳しく
この手法では、画像そのものを入力にするのではなくて、ラプラシアンピラミッドにて画像を以下のように分けて入力しています。
以下の記事を参考にラプラシアンピラミッドを作成します。ラプラシアンピラミッド(やガウシアンピラミッド)では、画像のエッジ処理のよなことを繰り返し行い、周波数成分に分けていきます。
この論文の実装では、以下のフィルターを用いて、ガウシアンピラミッドおよびラプラシアンピラミッドを作成しています。
f = [0.0025 0.0125 0.0200 0.0125 0.0025
0.0125 0.0625 0.1000 0.0625 0.0125
0.0200 0.1000 0.1600 0.1000 0.0200
0.0125 0.0625 0.1000 0.0625 0.0125
0.0025 0.0125 0.0200 0.0125 0.0025]
また、MATLABのimpyramid関数では、Burt and Adelson の論文の 533 ページで指定されるカーネルを使用します。OpenCVでもカーネルの記述がありましたが、少しカーネルの定義が異なるかもしれません。
ラプラシアンフィルタにより、画像の2次微分に相当する操作を行います。しかし、その前準備として、ガウシアンフィルタを用いて、ガウシアンピラミッドを作成する必要があります。画像は、虹色の旋律 さまの、ガウシアンピラミッドを使った画像処理より引用させていただいております。入力の画像に対して、上のフィルタにて演算をし、出力のサイズを縦横共に半分にしていきます。それを自分で設定した数だけ繰り返し、以下のようなピラミッドのような連なりを作成していきます。

画像出典:虹色の旋律 さま「ガウシアンピラミッドを使った画像処理」
上のピラミッド中の各画像を2倍に拡大すると以下のようになって、ガウシアンカーネルにて計算することで、画像がどんどん滑らか(エッジがなくなっていている)になっています。別の言い方をすると、高周波な画像から低周波な画像に分解できていることがわかります。

画像出典:虹色の旋律 さま「ガウシアンピラミッドを使った画像処理」
次に、以下のように、n番目と、n-1番目の演算結果を引き算します。これが画像の2次微分に相当します。
そして、この分解した画像を再構成する際には以下のように、単にラプラシアンピラミッドの各画像を足し合わせます。その際、ガウシアンピラミッドの画像は、引き算するときに2倍に拡大してサイズをそろえます。
 ICHI.PROさま:レビュー:LAPGAN —ラプラシアン生成的敵対的ネットワーク(GAN)中の図を改変
ICHI.PROさま:レビュー:LAPGAN —ラプラシアン生成的敵対的ネットワーク(GAN)中の図を改変
この手法では、画像そのものを入力にするのではなくて、ラプラシアンピラミッドにて画像を以下のように分けて入力しています。
以下の記事を参考にラプラシアンピラミッドを作成します。ラプラシアンピラミッド(やガウシアンピラミッド)では、画像のエッジ処理のようことを繰り返し行い、周波数成分に分けていきます。
実際に自前の画像で確認
今回紹介する方法では、入力の画像に対して、画像の2次微分に相当する操作を行い、ラプラシアンピラミッドを作成すると述べました。例えば、猫の画像のラプラシアンピラミッドを可視化すると以下のようになります。

また、ラプラシアンピラミッドから入力の画像を再構成できると述べたのですが、左が入力画像、右がラプラシアンピラミッドに分解後、再び入力画像を復元したものです。ラプラシアンピラミッドにて周波数ごとに分解したのちに、再び復元することができています。以下のネットワークでは、これらの特性を生かし、各ラプラシアンピラミッドをエッジ成分の補正、色成分の補正、など、それぞれの役割分担をし、補正→再構成をします。RGB画像をそのまま入れるのではなく、このように周波数特性を考慮しながら補正を行っていきます。

ラプラシアンピラミッドに関しては、以下の記事などが参考になりました。
また、より詳しく、流れに沿って理解したいときに以下の書籍(デジタル画像処理)の5章が参考になりました。
なお、本章の説明は以下のMATLABのブログを参考にしました。 blogs.mathworks.com
この手法について
入力画像の処理の流れ
以下にこの手法のネットワークの図を示します。この手法では、1)全体的な色の補正 および 2)詳細の補正 の2つの役割に分けられていて、下の黄色のネットワークが1)の全体的な色の補正に使われる、と論文中にあります。
ただ、これは明示的に黄色のネットワークにRGBの補正の操作をさせているわけではなく、まずはラプラシアンピラミッドのn番目(公式の実装では n = 4)の画像が色味を多く有するので結果的に一番初めの、黄色の部分で色の補正をしていることになっているものだと思います。
1 . n番目のラプラシアンピラミッド(露出オーバーや露出アンダーのもの)を入力し、それを適正露出の画像(つまり正解データ)から得られたn番目のラプラシアンピラミッドに変換
2 . n-1番目のラプラシアンピラミッドを入力し同様の操作を行う
3 . 1番目のラプラシアンピラミッドまで繰り返す
という流れだと思います。 ここで、黄色のネットワークでレベルnのピラミッドを処理しYnを生成、紫のネットワークでアップサンプリング(拡大)したあとに、レベルn-1のピラミッド(Xn-1)を足し合わせています(Yn+Xn-1)。そして、次のレベルのピラミッドを推論することを目指します。 ここでの Yn+Xn-1 とは、つまり、n-1番目のガウシアンピラミッドということになります。

損失関数について
ここでは、損失を3つに分けて定義しています。
Reconstruction Loss
再構成誤差。訓練データセットでは、露出アンダー/オーバーの画像と適正露出のペアが与えられています。そのため、このネットワークで再構成して画像と、それに対応する適正露出の画像を比べて、L1損失を計算します。

Pyramid Loss
ピラミッドに関する損失。上の再構成誤差のみで最適化するよりもこの損失を入れる方が結果が安定するようです。このネットワークでは、サイズの小さい、つまり、n番目(最後)のピラミッドから入力していきます。そこからn-1番目...のピラミッドを再構成したときの誤差を最小化していきます。
Adversarial Loss
ここで、GANの仕組みが導入されています。以前のブログ記事でも、触れましたが、単にimage-to-imageな回帰で、損失関数を平均二乗誤差にすると、「ありそうな」画像を平坦化してような画像ができてしまい、少しエッジがなまった画像が生成されがちだと述べていました。
一方、こちらの論文では、判別器(discriminator)を用意し、学習の過程でそれが今回のネットワークで補正された画像なのか、それとももともと適正に補正されたもの(正解データそのもの)かを判別します。
つまり、ミニバッチで補正した画像Xとそれの正解データ(対応する、適正露出の画像)Yの両方をdiscriminatorに投げて、補正をする生成するネットワークから生み出されたものか、それとも正解データなのかを判別させて、生成モデルのほうを鍛えていきます。
srcファイルの中のmodelGradients.mの24行目に偽物かどうかの判別器を動かしています。
dlYPred = forward(dlnetDiscriminator, dlY_D);
また同ファイルの31行目でその時の損失(Loss)を計算しています
[lossGenerator, lossDiscriminator, Rloss, Gloss] = final_Loss(dlY, dlXGenerated, dlYPred, dlYPredGenerated);
学習済みモデルの可視化について
学習済みモデルを可視化して、例えば、入力のサイズを確認してみます。以下のようにモデルをインポートして、analyzeNetworkを用います。
load('models/model.mat') % windowsにて実行
analyzeNetwork(net)
すると、以下の黄色で囲われているように、アクティベーションのところで、512×512×12であることがわかります。512というのは画像の縦と横のサイズです。12というのは、RGBの3チャンネルが4つ分のことです。先ほど説明したように、RGBの画像をラプラシアンピラミッドで4つの画像に展開しているためです。この4というパラメータは自前のデータで行う場合は適宜変更することができます。また、ここでの実装では、画像のサイズを128, 256, 512の3つのパターンを行って学習を完了をさせており、マルチスケールでの学習を行っています。

また、同様に出力も512×512×12で、入力と同じであることがわかります。

実際に動かしてみる
まずは、こちらのinstall_.mというファイルを実行します。installとあるので、何かをダウンロードするのかと思いましたが、そうではなく、scrという名前のフォルダを参照できるように、addpathします。

そのあとに、demo_single_image.mを実行すれば、example_imagesファイル内の画像に対して、補正が行われます。bgu, demo, ...といったファイルの見える場所で実行して、パスの位置だけ確認すれば、特に特別な設定も必要なく動きました。
今後の課題
- 以下の図の上段のように、光が多すぎて、男性の顔の周辺の情報が失われている場合はうまく補正できなかったり、下段のように暗すぎるとノイズが発生することが今後の課題として挙げられています。同時に他の手法でも難しいと述べられています。
- 特に顔などは、情報がないと復元は直感的に考えてできないので、ある程度は仕方ないのかもしれないですね。

まとめ
- 今回は、Afifiら (2021)の方法を勉強し、動かしてみました
- 簡単に、かつ、非常にうまく色の補正ができて、非常に素晴らしい手法だと感じました
- 特に三毛猫の色までうまく再現できていて、とても嬉しかったです
- コメントや勉強会のお誘いなどございましたら、linkedinやmatlab central、githubにあるメールアドレスなどからご連絡いただけると幸いです。 kentapt.hatenablog.com
参考文献
pix2pixを勉強&線画から顔画像を生成してみた:前半
この記事は、MATLAB/Simulink Advent Calendar 2021の23日目の記事として書かれています。
はじめに
この記事では、pix2pixについて勉強したのでそのまとめと、線画から画像に変換する課題にpix2pixを適用してみようと思います。pix2pixは以下の論文です。間違いなどがあれば教えていただけますと幸いです。
pix2pixの論文の冒頭で、それを試した時の入力と結果の例があります。以下は、論文の図1からの引用です。ラベルから風景に変換したりするだけでなく、線画や時間帯などを変換した例があり、いろいろなシーンで使えそうですね。この手法では、深層学習やGANと呼ばれる手法を用いていて、一対一対応する、画像とラベルのペアを用いて学習を行います。

pix2pixを勉強するうえで、顔の線画から顔の画像に変換することを試しに行ってみました。前半ではpix2pixについて述べ、後半ではこのデモについて紹介します。

ここでは、CelebAMask-HQ Datasetを用いています。
GANについて
pix2pixはGANの一種で、画像の生成器だけでなく、もとの(正解の)画像と生成した画像が生成したものか、もともと用意した画像かどうかを判別します。GANについては、ここでは割愛いたします。以下の記事などがわかりやすかったです。
pix2pixについて
大まかな流れ
以下の図はpix2pixの流れを簡単にまとめたものです。
- 訓練データ:入力するデータ(例:線画)とその結果(例:線画のもとになってる画像)のペア
- Generatorは入力画像(例:線画)からそれに対応する正解(例:線画のもとになってる画像)を生成することを目指す
- Discriminatorは、その画像が生成されたものか、もともと用意している正解画像かを見分ける
- Generatorは、正解画像とできるだけ同じ画像を生成できるよう学習していく
- Discriminatorは、生成画像をFake, そうでない画像をRealと判別できるよう学習

生成器(ジエネレーター)について
後半のデモで、線画の変換を行うので、ここでも線画っぽい絵を例にします。以下の左の図を右の図に変換することを考えます。ジェネレーターは畳み込み込みや逆畳み込みを用いて画像から画像の変換を行います。pix2pixでは、Unet構造を用います(以下の図ではそうなってませんが)。

Unetの構造に関しては以下の記事がわかりやすかったです。
下の図は、後半のデモで用いるネットワークを可視化したものです。入力は縦横が256×256で、チャンネル数は3(RGB)になっています。グレースケール画像なので、チャンネルを1にすることも可能ですが、特にそのような変更は行っていません。ジェネレーター側は、画像から画像を生成しているんだなという理解でひとまず良いと思います。また下の構造をみると、確かにスキップコネクションのような線が下に伸びていることもわかります。

識別器(ディスクリミネーター)について
上の流れの図でもありましたが、識別側では、生成されたであれば、Fake、もともと用意した画像ならRealと予測するように学習していきます。単純にCNNで分類するのもよいですが、pix2pixでは、入力の画像と生成された(又は正解画像)をチャンネル方向に重ねてから分類を行います。ちょうど下の図のようなイメージです。

論文では以下の図で説明されています。

実際にネットワークの構造を見てみます。一番上の段をみると、入力の画像が6チャンネルになっていることが確認できます。

また、上の図の最後の段を見ると、16×16×1になっています。Real / Fakeの見極めであればサイズは1であれば良さそうですが、pix2pixの論文ではPatchGANというセクションがあります。そこでは、以下のことが述べられています
- L1やL2損失のみを用いてimage-to-image変換をしようとすると全体的にぼやけた画像が生成されやすい
- (ぼやけていないところである)高周波成分をうまく識別器が捉えるべく、識別側に工夫を加える
- 画像をパッチに分けて、その領域ごとに Real / Fakeか見分ける
- 特に識別器の構造を作り変えるわけではない
確かに、高周波成分をうまく捉えて、ぼやけた生成画像を認識することができたら、より鮮明な画像が生成できそうです。その方策として、以下のように述べられています。
We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D.
ここで、重要なのが先ほどの識別器の出力サイズで、16×16になっていると述べました。画像全体に対して、1つの出力(Real / Fake)を出すのではなく、各パッチごとにその推論を行います。このように出力を調整すれば、ちょうど各パッチごとに推論していることと等しいことを行うことができます。損失の計算では、各パッチの損失をそれぞれ計算し、足し合わせます。
下の図は、パッチのサイズを変えたときの結果です。16×16の時が最もよかったとのことです。パッチサイズが大きいほど、細かいところまで見れるので良さそうですが、大きすぎると画像の全体的な良さを評価できないというトレードオフの関係にあります。複数のステージを設けて、複数のパッチの平均でもよさそうですね。

ノイズベクトルzについて
GANを勉強し始めると、ノイズベクトルzというのをはじめに目にすると思います。そのzを起点に生成したり、そのノイズベクトルによって生成する画像をある程度制御できたりします。しかし、pix2pixでは、ノイズベクトルzに関しては以下のように書かれています。
Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time.
つまり、dropout層によって、ランダムに出力を落としてランダム性を加えていると述べられています。また、ここでは、テストの段階でもドロップアウトを用いるとあります。そのため、たとえばDCGANに出てくるノイズベクトルzを思い浮かべながらpix2pixをみると少し違和感があるかもしれません。
損失について
pix2pixでは、入力と出力のペアの訓練画像があります。生成器の損失としては、出力の画像と生成画像の差分をとって(L1)、それらの差異も損失に加えます。
前半まとめ
- pix2pixの流れや方法についてまとめました
- Conditional GANの一種ではあるものの、ノイズベクトルzを明示的には使わず、入力の画像から目的の画像に変換するよう設計されていることがわかりました。
- 論文のイントロダクションにもあるとおり、多くのコンピュータービジョンのタスクは画像の何らかの変換、というふうに言い換えることができて、そのような課題一般にpix2pixを応用することができます。汎用性の高い非常に便利な手法だと思いました。 また、画像だけでなく、シミュレーションの結果とも合わせて変換をするような研究もあり(以下のPDF)、画像に留まらず、音の生成などでも使えるかもしれないですね
https://www.jstage.jst.go.jp/article/pjsai/JSAI2019/0/JSAI2019_4K3J1302/_pdf
後半では、顔画像のデータセットから線画を作成し、訓練させ、線画から顔画像を生成するpix2pixのモデルを作成しました。以下のようになっていて、上手く顔画像の生成ができました。しかし、少し文量が多くなったため、次回に回そうかと思います。
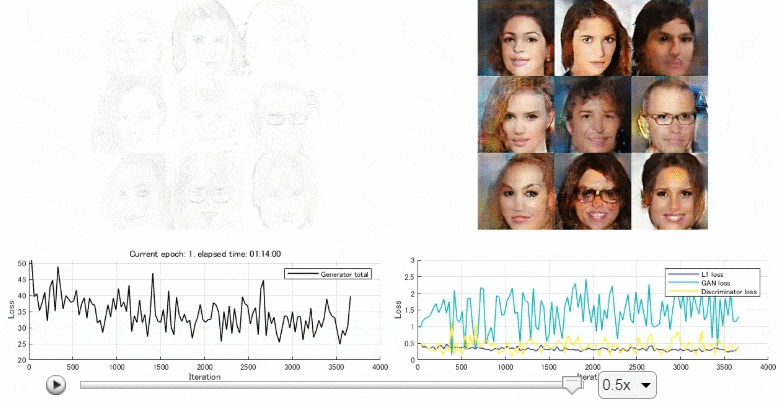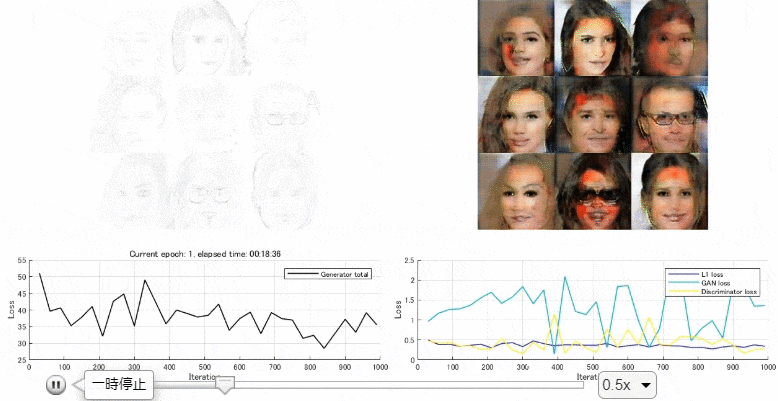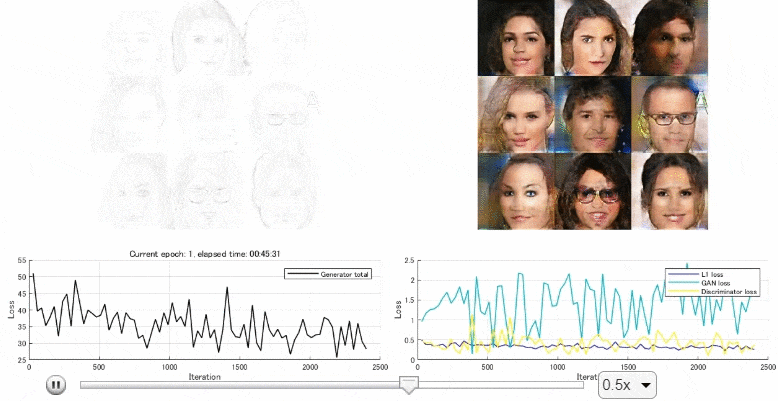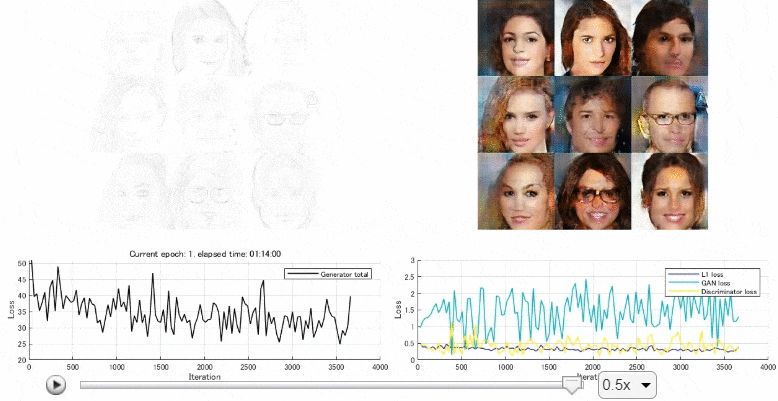
kentaPtのブログ トップ
本ブログでは、普段勉強したことなどを備忘録としてまとめています。
深層学習系
検出系
Spatial CNNを用いた車線検出
 kentapt.hatenablog.com
kentapt.hatenablog.com物体検出の指標である平均適合率について勉強&自分で実装してみた
姿勢推定
- シンプルかつ高精度な手法を勉強&動かしてみた
 kentapt.hatenablog.com
kentapt.hatenablog.com
説明可能AI
- LIMEを用いた判断根拠の可視化のまとめと実装
 kentapt.hatenablog.com
kentapt.hatenablog.com - Score-CAMを用いた判断根拠の可視化のまとめと実装 kentapt.hatenablog.com
単眼超解像
- 単眼超解像の手法(VDSR)について勉強&動かしてみた

露出補正
露出補正の最先端手法を勉強&動かしてみた (Afifi et al., CVPR, 2021)
- 左側の画像はカメラに入るカメラが多く、全体的に白くなってしまっています(露出オーバー)。右側の画像では、それらの色が補正され、より美しい画像になっていることがわかります。この投稿では、深層学習による露出補正の手法を用いて、明るすぎた/暗すぎた画像を自動的に補正を行います。
pix2pix
pix2pixを勉強&線画から顔画像を生成してみた
- pix2pixとよばれる、生成モデルの一種を勉強したので、まとめ、さらに線画から顔写真を生成してみました。
データ拡張
CNNのためのデータ拡張法を勉強&簡単に実装してみた (RandomErasing, CutOut, MixUp, Sample Pairing)
- 過学習を防ぎ、認識能力を高めるために、多くのデータ拡張の方法が提案されています。ここでは、RandomErasing, CutOut, MixUp, Sample Pairingを簡単に紹介し、実装もしてみたので共有したいと思います。
統計
主成分分析をわかりやすく説明したい&自分で実装して理解を確かめてみる
コンジョイント分析を用いて、消費者の好みを分析してみよう (勉強まとめ & pythonコード)
GIS系
- MATLAB Mobileとpythonを用いてドライブの軌跡をプロットしてみた
 kentapt.hatenablog.com
kentapt.hatenablog.com
入門系
- 自然言語処理に入門してみた
 kentapt.hatenablog.com
kentapt.hatenablog.com
単眼超解像(Single Image Super Resolution)手法のVDSR (Kim et al., 2016, CVPR) について勉強&動かしてみた
はじめに
この記事は、MATLAB/Simulink Advent Calendar 2021(カレンダー2)の22日目の記事として書かれています。
こちらの記事で用いたコードや画像、この記事の原稿ファイルはこちらにアップロードしています。勉強会やまとめ資料用、ゼミ活動など、何かの役に立てば嬉しいです。
ここでは、低解像度の画像を高解像化する手法について勉強したため、そのまとめとして紹介します。詳細はもとの論文である、Kim et al (2016) [1]をご覧ください。以下の図は、そのイメージです。低解像度の画像を nearest neighborにより拡大したものと、今回紹介する手法によって高解像度化したものを重ねています。(深層学習を使わず、バイキュービック補間で拡大した場合でも、ある程度よい結果が得られます。)まだまだ勉強中で、誤った点や不十分な記述があるかもしれません。その場合は教えていただけますと幸いです。
図の説明:単眼超解像のイメージ。VDSRとよばれる方法を用いて高解像度化した画像と、画像サイズの小さい画像を、nearest neighborによって拡大したものを重ね合わせている。評価の際はバイキュービック補間で拡大したものとの比較を行う。
単眼超解像の手法について
単眼超解像に関する先行研究に関しては、以下の記事などが非常に参考になりました。こちらの記事では、VDSRのみ取り扱うため、他の手法との比較については、他の記事を参考にいただけると幸いです。
トップ学会採択論文にみる、超解像ディープラーニング技術のまとめ
Deep Learningによる超解像の進歩
www.slideshare.net
コンピュータビジョンの最新論文調査 Single Image Super-Resolution 前編
イントロダクションの和訳
本論文の位置づけや新規性を理解すべく、以下に、私の勝手な解釈に基づいた論文のイントロダクションの和訳を掲載します。意訳なども含むのでご注意ください。
本研究では、単眼超解像(Single Image Super Resolution: SISR)と呼ばれる、低解像度(Low Resolution: LR) 画像から、高解像度画像を生成する問題について扱う。単眼超解像(SISR)は、コンピュータビジョンにおいて広く利用されており、その場の要求に応じて高解像度な画像が必要になるセキュリティや監視、さらに医療画像解析など多岐にわたる。そのため、単眼超解像はコンピュータービジョンの界隈で広く研究されてきた。黎明期から使われてきた手法には、バイキュービック補間などの補間手法や、ランチョス・リサンプリング[7]などの統計的に割り出された画像の前提条件 [20, 13]/internal patch recuurence [9]を利用したより強力な手法などがある。
現在、低解像度なパッチから高解像度なパッチへのマッピングをモデル化するために、学習法が広く用いられている(筆者追記:パッチとは、画像を切り出した小さな画像やその集まりのこと)。Neighbor embedding [4,15]はパッチ部分空間を補間する方法である.スパースコーディング法[25, 26, 21, 22]は、スパースな信号表現に基づくコンパクトな辞書を学習する方法である。最近では,ランダムフォレスト[18]や畳み込みニューラルネットワーク(CNN)[6]も用いられ,精度が大きく向上している。
その中で、Dongら[6]は、CNNを用いて低解像度画像から高解像度画像への変換をエンドツーエンドで学習できることを示した。SRCNNと呼ばれる彼らの手法は、他の手法で一般的に必要とされる(手動で)定義された画像の特徴を必要とせず[25, 26, 21, 22]、最先端の性能を発揮するものである。確かに、SRCNNは超解像(SR)問題に深層学習技術を導入することに成功したが、3つの側面において、いまだ改善の余地がある。第一に、小さな画像領域のコンテキストに依存している、第二に、学習の収束が遅すぎる、第三に、ネットワークは単一のスケールに対してのみ機能する、ということである。本研究では、これらの問題を実用的に解決するための新しい手法を提案する。
コンテクスト
非常に大きな画像領域にわたる文脈情報(筆者追記:非常に小さな領域を見るのではなくて、少し周りの連続性とか、こういうパターンになってるとか、そういう"文脈"を捉えますよ、という意味に近い?)を我々の手法では利用する。スケールファクターが大きい場合(筆者追記:例えば、非常に小さな画像を、もっと大きな解像度のものに変換しようとすること)、小さなパッチ(ここでは、画像を小さく切り出したもの)に含まれる情報だけでは画像の詳細の復元には不十分である場合が多い(不良設定問題:ill-posed)。一方、本研究で提案する手法は、大受容野を用いた、深いネットワークであり、より広域な画像のコンテキストを考慮したものとなる(受容野については以下の図を参照ください。ここでは、畳み込みのときに見られる側のエリア、くらいの意味でもよいかもしれません)。

引用:アフシンアミディ・シェルビンアミディ 著 畳み込みニューラルネットワーク チートシート
学習の収束について
学習を高速化させる方法として、残差学習型CNN(筆者追記:ここでは、差分を学習する、という意味合い)および、非常に高い学習率を用いた手法を提案する。低解像度画像と高解像度画像は多くの場合、同じ情報を共有(筆者追記:例えば、解像度は違っても同じエリアには、猫の耳っぽい似た輝度値のピクセルがたくさんある)しているため、高解像度画像と低解像度画像の差分を明示的にモデル化し学習させるすることが効果的である。そのため、筆者らは、入出力の画像が似ている場合に効率よく学習できるネットワーク構造を提案する。さらに、我々の初期学習率はSRCNN[6]の104倍である。これは、残差学習と勾配クリッピングによって可能となる。
スケールファクター
我々は1つのモデルのみによる(筆者追記:アンサンブルではない、という意味合い?)、単眼超解像の手法を提案する。高解像度化するときの倍率は、通常、ユーザが指定し、端数も含めて任意に設定できるべきである。例えば、画像ビューアでのスムーズなズームインや、特定の大きさへのリサイズができるとよい(筆者追記:例えば、何らかのアプリを使って、ユーザーが好きな倍率でズームインをして、その時々でキレイに高解像度化されたものがみれるといいよね、みたいな感じだと思います)。全ての起こりうるパターンに備え、多くのスケール依存のモデルを学習・保存することは非現実的である(筆者追記:ユーザーが1.5, 2, 3, 4, 5, ... 倍にズームする可能性があるので、それぞれ専用のネットワークを用意するのは現実的ではないよね、という意味)。そのため、複数の倍率にも対応できる、畳み込みネットワークによる単眼超解像の手法を考案した。
貢献
要約すると、本研究では、非常に深い畳み込みネットワークに基づく高精度な単眼超解像の手法を提案する。非常に深いネットワークは、小さな学習率を用いると収束が遅くなりすぎる問題がある。一方、高い学習率で収束率を高めると勾配爆発が起こり、うまく学習できなくなるため、残差学習と勾配クリッピングでこの問題を解決する。さらに、一つのネットワークでマルチスケールの超解像の問題に対応可能な方法を示す。図1にあるように、本手法は最先端の手法と比較しても、比較的高精度かつ高速であることがわかる。

イントロダクション補足
イントロダクションでは、Dong ら(2015)のSRCNNとよばれる手法について述べられていました。以下の図のような非常にシンプルで浅いネットワークで超解像化を行った論文です。2021年12月現在では5000以上の引用がされていてすごいです。その3層のものに比べて、20層の「非常に層の深い」モデルを本論文では提案しています。現在は、20層で深いネットワークと表現することは少ないですが、いろいろとCNNに改良が重ねられて現在のもっと深いネットワークがあるのだなあと感じました。Dongらの論文でも、より深いネットワークも試されましたが、それはうまくいかなかった、と論文中に記述があります。
The effectiveness of deeper structures for super resolution is found not as apparent as that shown in image classification [17]. Furthermore, we find that deeper networks do not always result in better performance.
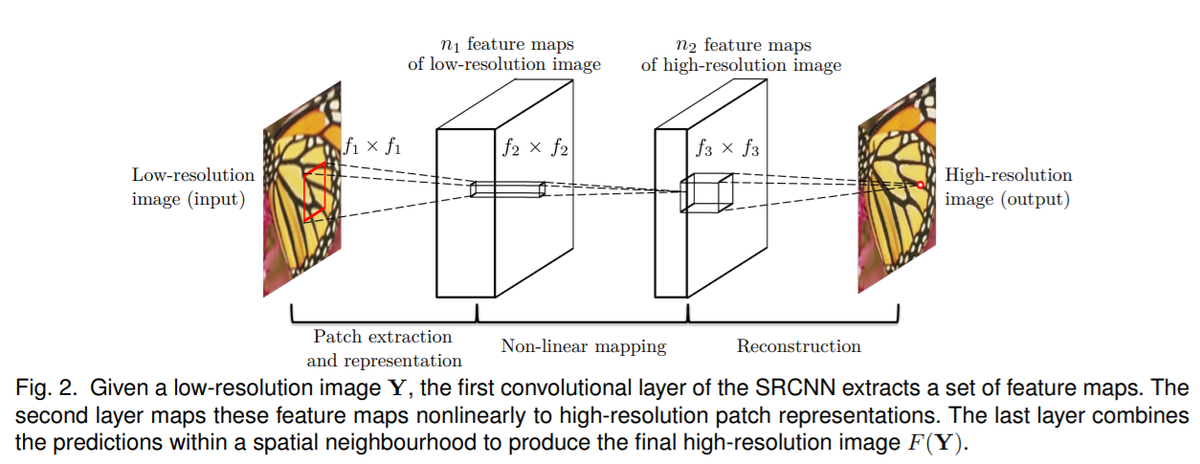
図出典:Dong et al., (2015) [2] より
ここで紹介する手法(VDSR)の流れについて
以下に、Kimらの方法の流れの図を示します。入力の画像があって、畳み込み演算などをするとともに、下側に分岐があって、グレーの画像と+されていることがわかります。まずはこれについて述べます。

図出典:Kimら (2016) [1] より
残差の学習について
このネットワークでは、直接的に高解像度化された画像を推論するのではなく、イントロダクションにあったように、その差分を学習します。つまり
(学習するもの)=(高解像度な訓練用の正解データ)- (それに対応する低解像度の画像をバイキュービック補間により拡大したもの)
になります。下の図にもマイナス(ー)のマークがありますが、それが差分を取っていることを示します。ここで得た差分を"Residual"と表現されています。

図出典:MATLABドキュメンテーションより
入出力について
入力:低解像度をバイキュービック補間により拡大したもの
出力:入力の各ピクセルに対する、高解像度画像との差分
になっていて、その出力に入力の画像の値を足し合わせると、高解像度な画像になるように設計されています。前述したプラス(+)のマークに相当します。
また、ここでは、RGBではなく、RGB の色の値を YCbCr 色空間に変換し、その輝度のチャンネルのみを用いています。
人間の目は、色よりも明るさに敏感だからだそうです
This is because human vision is more sensitive to details in intensity than in color.
入力のサイズについて
ここでは、画像全体を入力するのではなく、画像を小さな領域に区切って(パッチ)、それを入出力としています。例えば画像から、41×41ピクセルのパッチを複数きりだし、それらを学習させます。
マルチスケールについて
イントロダクションにもあったように、特定の倍率、例えば2倍にしかできません、だと実用性がさがるため、学習の際は、複数の倍率で高解像度な画像を縮小させ、学習させています。
手法の分類について
このように、今回の超解像の手法では、高解像度な画像があれば、ラベリングも必要なく学習ができるため、自己教師あり学習と分類することもできます。ただ、いろいろと考え方はあると思うので、ひとまず本稿ではそうする、というニュアンスでお願いします。
以下の図のように単眼超解像の手法も分類できるそうで、今回は自己教師あり学習ですが、他にも方法は多く存在します。

画像出典:AI-SCHOLAR「ペア画像はいらない!実用的な超解像技術の提案」(Navier(ナビエ)株式会社 様による解説記事)
参考情報:非常に勉強になる記事でした。ありがとうございました。 ai-scholar.tech
結果の例
以下に、VDSRによる結果の例を論文から引用します。一番右の結果がVDSRによるもので、確かに角の先も含め鮮明に高解像度化できていることがわかります。
 図出典:Kimら (2016) [1] より
図出典:Kimら (2016) [1] より
評価指標を用いての定量評価については割愛します。評価については、以下の論文が非常に勉強になりました。
川嶋先生、中村先生「深層学習を用いた衛星画像の超解像手法」 www.jstage.jst.go.jp
GANとの違いは?
上の手法の分類図でも、GAN(敵対的生成ネットワーク)による方法も多く提案されていました。今回のように、画像から画像を推論(image-to-image)をする手法と比べ、Generator(生成ネットワーク)とDiscriminator(識別ネットワーク)にて競うように学習させていく方式とどのような違いがあるのでしょうか。
例えば以下はLedig et al., (2017)より [3] 引用した図ですが、MSE(Mean Squared Error: 平均二乗誤差)をもとに最適化していくと、ピクセル単位での評価の総和になるため、各ピクセルが「ありそうな」ピクセル値の平均的なところに収束してしまい、全体として、滑らかな画像になってしまう、という旨の記述がありました。これは、赤枠で示されてるように、単眼超解像によって生成すべきものが一意に定まらないことが原因です。
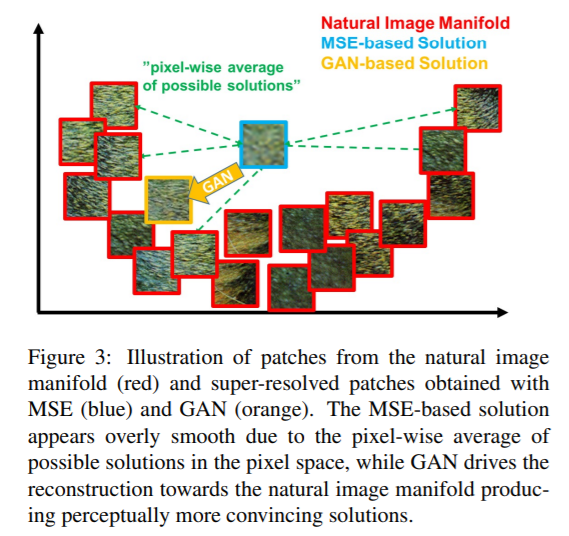
画像出典:Ledig et al., (2017)より [3]
画像で示すと、以下のような例があります。これは、右側がGANの要素を取り入れたときの結果で、L2損失を最小化したときの結果(左)よりも良好で、かつ、左側はぼやけた結果になっていることがわかります。

画像出典:Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T. and Efros, A.A., 2016. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2536-2544).
また、同様の議論は、VAE(変分オートエンコーダ―)とGANの比較でもあります。例えば、以下の文章は、巣籠先生著「詳説ディープラーニング」[4] からの引用です。
(VAEの)誤差関数には2乗誤差あるいは交差エントロピー誤差の項が用いられることになりますが、これを最小化しようとすると、全体的に画素を曖昧にさせた方が画像全体としての誤差は小さくなります。そのため、VAEではどうしても生成画像がぼやける傾向が出てきてしまうのです。
VAEでも画像を生成することはできますが、ここでも全体的に画像が滑らかな感じになりがちで、キレイなエッジなどが生成しにくい、という事だと思います。
実際にVDSRを動かしてみよう
こちらのMATLABの公式ドキュメントを参考に動かしてみました。おそらく多くの場合、下のURLの中のcopy commandでコマンドをコピーし、MATLAB上でペーストすれば該当のコードが開き、RUNボタンを押せばうまく動くと思います。 jp.mathworks.com
しかし、2ギガバイト弱のデータなどをダウンロードすることがデフォルトになっており、ダウンロードに少し時間がかかってしまいます。
今回は、ネットワークの構造をanalyzeNetworkで可視化したり、テストが画像の推論に絞ったものを以下のページにアップロードしています。なお、コードの内容はほとんどもとのドキュメンテーションの内容と同一です。
まとめ
- シンプルな方法で精度よく高解像度化ができる論文で非常に勉強になりました。
- 今回は、imresize関数を用いて縮小しているため、実際に低解像度な撮り方をしたものではありません。実際に解像度の違う画像ペアでも学習/テストしてみたいと思いました。
- この記事では、Very Deep Super Resolution (VDSR)とよばれる、画像から画像を推論する単眼超解像の手法について述べてきましたが、GANを用いた方法も近年は多く発表されており、今後はそちらの勉強もしていきたいと思いました。
- コメントや勉強会のお誘いなどございましたら、linkedinやmatlab central、githubにあるメールアドレスなどからご連絡いただけると幸いです。 kentapt.hatenablog.com
その他:参考にさせていただいたネットの記事
勾配クリッピングについて
masamunetogetoge.com 不良設定問題について
参考文献
[4] 巣籠 悠輔:詳説ディープラーニング ■生成モデル編
コンジョイント分析を用いて、消費者の好みを分析してみよう (勉強まとめ & pythonコード)
この記事は、Python Advent Calendar 2021の17日目の記事として書かれています。
はじめに
コンジョイント分析と呼ばれる手法や、pythonによるコーディングについて勉強したため、ここに自分用のまとめとして残したいと思います。間違いなどがあれば教えていただけますと幸いです。参考にさせていただいた記事は末尾にも、掲載しています。
コンジョイント分析とは、いくつかの製品属性を組み合わせた複数の代替案を回答者に提示し、好ましさをランク付けしてもらい、回答者の選好を分析する手法です。コンジョイント分析を用いることで、製品の価格や色、デザイン、品質などの要因が、それぞれどのくらい選好に影響を与えているかを調べることができます(グロービス経営大学院の記事より引用)。
コンジョイント分析の基本的な内容は、以下の書籍がわかりやすかったです。
また、閲覧可能な記事としては以下の、マーケティングリサーチの学び場『Lactivator』さまの記事がわかりやすかったです。
この記事では、pythonコードも記述しており、コンジョイント分析をより包括的に知りたい場合は、他の参考サイトや上の書籍を見ていただけると幸いです。
今回使用したコードやデータ、記事の本文などはこちらのアップロードしています。個人的な勉強や、ゼミ活動、勉強会などで役立つと幸いです。
想定する状況
ここでは、不動産会社になったつもりで、より多くの大学生に対して満足のいく下宿先を提供したいとします。そのためには、新入生や自宅から通う大学生がどのような下宿先の条件に注目しているか知る必要があります(ここではわかりやすい例としてあげていて、実際に私はそういう経験がないのでわかりません。あくまで例としてご理解ください)。
下宿先の家の条件として、家賃やセキュリティー、学校までの距離、築年数などがあるでしょう。万人には当てはまらないにしても、ペットを飼ってもいいか、というのも重要な学生も一定数存在しそうです。ただ、それらが、どれくらい学生にとって重視されているか、よくわかりません、下宿先でペットを飼いたい人がどれくらいいるのかもわからないので調査してみたくなったとします。
それらの条件(例:家賃や築年数)の重要度を調べるためには以下の方法が考えられます:
考えられる条件をすべて書いて、たくさんの学生に順位付けしてもらう
ただ、この調査にはいくつか問題があります。例えば、
- . たくさんありすぎて回答する自分でもよくわからなくなる
- . 単純にめんどくさくなって適当になっちゃう
- . 1番目と5番目に重視する内容が具体的にどれくらいの重要度の差があるのかわからない
- . その順位を集めた結果があっても、ある条件をもった家(家賃が安くて、少し古くて、大学から少し遠くて、、、)がどれくらい魅力的なのかわからない
といった問題が考えられます。そこでコンジョイント分析では、コンジョイントカードというカードを用意して、それに対してスコア(魅力度)をつけるなどして、消費者(ここでは学生)の好みやトレンドを分析します。
コンジョイントカード
以下にコンジョイントカードとそれを使った調査の例を示します。実験対象者はこのようなカードを見せられて、具体的にその魅力度のスコアを付けてもらいます。その場合、実際に家を選ぶ時の条件に似ていますね。また、家賃などの条件の羅列をみて順位付けするよりも正確なフィードバックが得られそうです。
また、コンジョイントカードを用いるメリットとして、実際の質問の総パターンよりも少ない枚数のカードで済みます。例えば2択の質問が6つあるだけでもそれらを全て網羅しようとすると、2の6乗で64枚ものカードのスコアを付けるのはとても大変です。

画像出典:マーケティングリサーチの学び場『Lactivator』:
購入決定を左右する商品要素を知る~コンジョイント分析の流れを徹底解説~
直交表について
コンジョイント分析では、あり得るコンジョイントカードを漏れなく、被験者に答えてもらうのではなく(大変な作業なので全パターンを聞くのは避けたい)、それよりもっと少ない(例:全8枚の内、4枚だけでよい)数で済むことがポイントでした。
直交表の例
下の表は、コンジョイントカードの質問の例です。2択の項目(質問)が7つあり、それに対して8枚のコンジョイントカードを用意します。このような表を直交表といいます。例えば、家賃が6万か8万の2択だったとすると、1の場合は6万、-1の場合は8万、といったふうに対応づけられていて、これによってコンジョイントカードの内容がわかります。

直交表のルール
総当たりで質問すると膨大な量になっていたものが、少数になると非常に嬉しいですね。さきほどの直交表をみてコンジョイントカードのパターンが決定されますが、感覚的には、同じ条件ばかりにならず、かつ他の項目との出現のパターンも毎回異なっていると少ないカード数で済みそうです。逆に、いつも家賃の値が8万で、さらにいつも8万&駅チカの物件ばかり聞かれても、カードのパターンが重複している気がしますね。このように、それっぽく適当に直交表が作られるのではなく、決まりがあります。
1 . 各項目(縦の方向)の和が0であること
2 . 各項目(縦の列)に関して、任意の2列の単相関係数は必ず0になる
ということです。
1に関しては、各項目で見たときに、例えば家賃8万のコンジョイントカードばかりだと、カードのパターンが偏っていて、6万のほうの影響が計算できないことが想像できます。各項目の出現確率は同じ、つまり縦方向で足し算をすると0になるべきなのは納得がいきますね。
2に関しては、単相関係数が0、ということであれば、単に各列の共分散が0になることを確認できればOKです。違う言い方をすると各列の内積が0であればOKです。共分散が0(相関係数が0)であるということは、各列は全く相関がない、似ていない、ということになりますね。逆に、各列が似ている場合を考えてみましょう。コンジョイントカードを眺めてみて、家賃6万&駅から近い、という条件のカードばかりだと、似通った質問しかできていない気がしますね。そして、相関が0であれば、毎回全然ちがうパターンの例(ここでは下宿先の物件)を被験者に提示できているので、それであれば少ない枚数で、効果的に総当たり方式での質問をしたときのような成果が得られそうですね。
データについて
上のgithubのページのdataというフォルダ内に、data.csvという練習用のデータを格納しています。適当にL8 24×3型を作成してみました。 直交表にもいろいろなパターンやそれに伴うパターン名がありますが、ひとまずここでは割愛させていただきます。- のマークは単に選択肢がないという意味です(2択)。

下宿先の部屋の候補を想定して、オートロックがあるか、大学までの距離、駐車場の有無、下宿先の家賃をもとに、そこに住みたいかのスコアを付けます。以降のセクションでは、実際に私が練習用に作った回答(二人分)をもとに、コンジョイント分析を行っていきたいと思います。
なお、コードに関しては、こちらの記事が大変参考になりました。 wannko5296.hatenablog.com
コンジョイント分析を用いて、消費者の好みを分析してみよう
以下は、コンジョイント分析を行うためのpythonコードです。
- pythonのバージョンは3.8
- 他のモジュールのバージョンについては、githubにアップロードしているファイルをダウンロードして、myenv.txt をご確認ください。
- コードは以下のページにあります。
モジュールのインポート
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import statsmodels.api as sm
データの読み込み
df = pd.read_csv('./data/data.csv') # x, y の指定 y = pd.DataFrame(df['score']) x = df.drop(columns=['score']) x.head(20)
| auto-lock | distToUniv | isParking | fee | |
|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 2 |
| 1 | 1 | 1 | 2 | 1 |
| 2 | 1 | 2 | 1 | 1 |
| 3 | 1 | 2 | 2 | 3 |
| 4 | 2 | 2 | 2 | 2 |
| 5 | 2 | 2 | 1 | 1 |
| 6 | 2 | 1 | 2 | 1 |
| 7 | 2 | 1 | 1 | 3 |
| 8 | 1 | 1 | 1 | 2 |
| 9 | 1 | 1 | 2 | 1 |
| 10 | 1 | 2 | 1 | 1 |
| 11 | 1 | 2 | 2 | 3 |
| 12 | 2 | 2 | 2 | 2 |
| 13 | 2 | 2 | 1 | 1 |
| 14 | 2 | 1 | 2 | 1 |
| 15 | 2 | 1 | 1 | 3 |
このデータは2人分、合計16個の回答を示しています。例えば一番上のauto-lock 1, distToUniv 1, isParking 1, fee 2では、
オートロックあり、大学からの距離がちかい、駐車場あり、家賃8万(1~3があって、それぞれ、6,8,10万に対応)という条件を示しています。これに対して、それぞれ被験者(今回は私が勝手に回答)が魅力度のスコアを付けます。
ダミー変数への変換
ここでは、pd.get_dummies関数を用いて、そのカードに、該当の項目が書かれているかどうかを 0/1で示します。
one-hotベクトルに直しているのと似ています。
drop_firstをtrueにして、その項目のはじめの要素は削除するようにしています。例えば、駐車場の有無では、駐車場がある、という要素が0である場合と、駐車場がない、という要素が1である場合は同じ意味です。
x_dum = pd.get_dummies(x, columns=x.columns, drop_first=True)
x_dum.head()
| auto-lock_2 | distToUniv_2 | isParking_2 | fee_2 | fee_3 | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 1 | 0 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 |
# drop_firstを無効にした場合を確認。_1のものが残っていることがわかる。ここではこのデータは使わない x_dum_noDrop = pd.get_dummies(x, columns=x.columns, drop_first=False) x_dum_noDrop.head()
| auto-lock_1 | auto-lock_2 | distToUniv_1 | distToUniv_2 | isParking_1 | isParking_2 | fee_1 | fee_2 | fee_3 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
df.describe() #要素の平均や標準偏差などの基本的な統計データを表示させる
| score | auto-lock | distToUniv | isParking | fee | |
|---|---|---|---|---|---|
| count | 16.000000 | 16.000000 | 16.000000 | 16.000000 | 16.000000 |
| mean | 7.187500 | 1.500000 | 1.500000 | 1.500000 | 1.750000 |
| std | 2.644964 | 0.516398 | 0.516398 | 0.516398 | 0.856349 |
| min | 2.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 25% | 6.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 50% | 7.000000 | 1.500000 | 1.500000 | 1.500000 | 1.500000 |
| 75% | 8.625000 | 2.000000 | 2.000000 | 2.000000 | 2.250000 |
| max | 12.000000 | 2.000000 | 2.000000 | 2.000000 | 3.000000 |
切片を追加
また、コンジョイントカードに記載されている内容に加えて、その他の影響がある場合に備えて、定数項も加えます。
この操作によってフィッティングするときの切片を計算することができます。
https://www.statsmodels.org/stable/generated/statsmodels.tools.tools.add_constant.html
x_dum=sm.add_constant(x_dum) # constという要素を追加 x_dum.head(10) # constが追加されたことを確認
x = pd.concat(x[::order], 1)
| const | auto-lock_2 | distToUniv_2 | isParking_2 | fee_2 | fee_3 | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1.0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 1.0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 1.0 | 0 | 1 | 1 | 0 | 1 |
| 4 | 1.0 | 1 | 1 | 1 | 1 | 0 |
| 5 | 1.0 | 1 | 1 | 0 | 0 | 0 |
| 6 | 1.0 | 1 | 0 | 1 | 0 | 0 |
| 7 | 1.0 | 1 | 0 | 0 | 0 | 1 |
| 8 | 1.0 | 0 | 0 | 0 | 1 | 0 |
| 9 | 1.0 | 0 | 0 | 1 | 0 | 0 |
OLS (Ordinary Least Squares) でフィッティング
model = sm.OLS(y, x_dum) # フィッティングを実行 result = model.fit() # 結果の一覧を表示 result.summary()
C:\Users\itaku\anaconda3\envs\py38_geopanda\lib\site-packages\scipy\stats\stats.py:1541: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
| Dep. Variable: | score | R-squared: | 0.959 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.938 |
| Method: | Least Squares | F-statistic: | 46.32 |
| Date: | Mon, 03 Jan 2022 | Prob (F-statistic): | 1.35e-06 |
| Time: | 13:46:07 | Log-Likelihood: | -12.272 |
| No. Observations: | 16 | AIC: | 36.54 |
| Df Residuals: | 10 | BIC: | 41.18 |
| Df Model: | 5 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 9.7500 | 0.368 | 26.463 | 0.000 | 8.929 | 10.571 |
| auto-lock_2 | 0.7500 | 0.330 | 2.276 | 0.046 | 0.016 | 1.484 |
| distToUniv_2 | -3.0000 | 0.330 | -9.104 | 0.000 | -3.734 | -2.266 |
| isParking_2 | 0.3750 | 0.330 | 1.138 | 0.282 | -0.359 | 1.109 |
| fee_2 | -1.6875 | 0.404 | -4.181 | 0.002 | -2.587 | -0.788 |
| fee_3 | -4.8125 | 0.404 | -11.924 | 0.000 | -5.712 | -3.913 |
| Omnibus: | 0.797 | Durbin-Watson: | 2.795 |
|---|---|---|---|
| Prob(Omnibus): | 0.671 | Jarque-Bera (JB): | 0.028 |
| Skew: | -0.010 | Prob(JB): | 0.986 |
| Kurtosis: | 3.205 | Cond. No. | 4.54 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
結果の一部を取り出し
結果を見てみるセクションで議論するため、weightとp値を取り出します
df_result_selected = pd.DataFrame({
'weight': result.params.values
, 'p_val': result.pvalues
})
df_result_selected.head(10)
| weight | p_val | |
|---|---|---|
| const | 9.7500 | 1.369002e-10 |
| auto-lock_2 | 0.7500 | 4.610362e-02 |
| distToUniv_2 | -3.0000 | 3.732512e-06 |
| isParking_2 | 0.3750 | 2.816648e-01 |
| fee_2 | -1.6875 | 1.884264e-03 |
| fee_3 | -4.8125 | 3.101164e-07 |
可視化のための準備
コンジョイント分析の結果を可視化するための準備を行います。上のdrop_Firstを有効にして、_ 1 がつく変数は落とされていました。グラフで表示させるため復帰させます。これらの重みは0とします。
for s in df_result_selected.index: partitioned_string = s.partition('_') if partitioned_string[2] == "2": valBase = partitioned_string[0] + "_1" df_valBase = pd.DataFrame(data =np.zeros((1,2)), index = [valBase], columns = ["weight","p_val"]) df_result_selected = pd.concat([df_result_selected,df_valBase]) df_result_selected.head(20)
| weight | p_val | |
|---|---|---|
| const | 9.7500 | 1.369002e-10 |
| auto-lock_2 | 0.7500 | 4.610362e-02 |
| distToUniv_2 | -3.0000 | 3.732512e-06 |
| isParking_2 | 0.3750 | 2.816648e-01 |
| fee_2 | -1.6875 | 1.884264e-03 |
| fee_3 | -4.8125 | 3.101164e-07 |
| auto-lock_1 | 0.0000 | 0.000000e+00 |
| distToUniv_1 | 0.0000 | 0.000000e+00 |
| isParking_1 | 0.0000 | 0.000000e+00 |
| fee_1 | 0.0000 | 0.000000e+00 |
p値に応じてバーの色を変える:
p値が0.01以上、0.05以下の場合はシアン、0.01以下の場合は青、0.05以上(あまり信用できない)の場合は赤に設定します。
bar_col = [] for p_val in df_result_selected['p_val']: # print(p_val) if 0.01 < p_val < 0.05: bar_col.append('Cyan') elif p_val < 0.01: bar_col.append('blue') else: bar_col.append('red') # p値が0.05以下のものを青、そうでないものを青とする df_bar_col = pd.DataFrame(data = bar_col, columns=['bar_col'], index = df_result_selected.index) df_result_selected = pd.concat([df_result_selected,df_bar_col], axis=1) df_result_selected.head(20)
| weight | p_val | bar_col | |
|---|---|---|---|
| const | 9.7500 | 1.369002e-10 | blue |
| auto-lock_2 | 0.7500 | 4.610362e-02 | Cyan |
| distToUniv_2 | -3.0000 | 3.732512e-06 | blue |
| isParking_2 | 0.3750 | 2.816648e-01 | red |
| fee_2 | -1.6875 | 1.884264e-03 | blue |
| fee_3 | -4.8125 | 3.101164e-07 | blue |
| auto-lock_1 | 0.0000 | 0.000000e+00 | blue |
| distToUniv_1 | 0.0000 | 0.000000e+00 | blue |
| isParking_1 | 0.0000 | 0.000000e+00 | blue |
| fee_1 | 0.0000 | 0.000000e+00 | blue |
部分効用値を表示させる
_ 1 とつくものが基準になっているので、それをもとに同一カテゴリが正または負の影響があるか見てください。
# プロットするときに日本語でも文字化けしないように設定 from matplotlib import rcParams plt.rcParams["font.family"] = "MS Gothic" # アルファベット順位 df_result_selected = df_result_selected.sort_index() xbar = np.arange(len(df_result_selected['weight'])) plt.barh(xbar, df_result_selected['weight'], color=df_result_selected['bar_col']) index_JP = ["駐車場なし","駐車場あり","家賃10万","家賃8万","家賃6万","大学から遠い","大学から近い","定数項","オートロックなし","オートロックあり"] plt.yticks(xbar, labels=index_JP[::-1]) # 順番があうように順番を逆にする plt.show()

結果を見てみる
上のOLS Regression Resultsについて(result.summary()で表示したところ)
- R-squaredは約0.96と高い値を示している => 良いフィッティング結果を得ることができた。簡単なデータではあったが、スコアを決定する要因の全体の9割以上を説明することができている。私の重視する家賃、大学までの近さがともに入っているためだと考えられる。ただ、これが私の家選びの傾向を完全に理解した、ということにはならないと思います(「考えたこと」章を参照ください)
- P>|t| は、isParking_2以外、統計的に有意である(有意水準を5%とした場合)ことがわかります。 => isParkingは個人的にどちらでも良いので、私がこの練習用データを作るときは、ほとんど見ずに回答していました。そのため、この限られたデータではうまくフィッティングできなかったのではないかと考えられます。もしより多くの似た考えをもつ回答者がいれば、このp値もより小さく(有意になり)、かつ重みが小さな値に収束していくはずです。P>|t|の欄の値が大きいものばかりだと、たまたま重みが大きくなっただけの偶然であることが否定できず、コンジョイント分析から多くの示唆を得ることができないため、今回はよい練習データになっていてよかったです。
- 多重共線性について:Cond. No.(Condition number)を確認します。statsmodelsのドキュメンテーションによると、
One way to assess multicollinearity is to compute the condition number. Values over 20 are worrisome (see Greene 4.9).
とあります。今回は20以下なので、多重共線性についてもひとまず大丈夫そうです。
https://www.statsmodels.org/stable/examples/notebooks/generated/ols.html
- 最後の色に分けられたグラフでは、私が家賃安め&大学から近め を優先してよいスコアを付けたので、納得のいくグラフです。駐車場がない場合が少しポジティブな方向に出ていますが、特に私は考えず記入していました。ここでは、p値が0.05より高く赤で示されていて、特に考えず記入しなかったことともつじつまがあっています。
考えたこと
この分析を勉強してみて考えたことを以下に記載します。この分析は勉強中なので的外れなところもあるかもしれませんのでご注意ください。
コンジョイント分析全体について
- 今回はpythonによる実装を中心に議論しましたが、解析の中身自体は重回帰をして、その重みをもって議論しているため、比較的シンプルな方法なのではないかと思いました。
- 機械学習でいう、LIMEとアイデア似ているところが多いな思いました。LIMEでは、例えば画像の場合、ランダムにブラックアウトさせて、そのときのスコアの変動を見ます。そこでも線形回帰が使われていて、その重みを用いて機械学習や深層学習による判断根拠の可視化を行います。
疑問点や改良点について
- 今回は、被験者の少ないデータを自作し、テストしています。しかし、被験者が多くなった場合は、スコアのベースラインも被験者によって異なるのでその補正が必要だと思います。例えば、被験者によって、高めに点を付ける人、そうでない人が存在すると、各被験者のスコアの平均で割り算したり、何らかの標準化が必要です。
- 重回帰による重要度の議論について:上で述べたLIMEでは、線形回帰をするために重回帰を用いたり、決定木を用いています。コンジョイント分析でも、うまく重回帰ではフィッティングできず、決定係数の低い場合は決定木を用いてみても良いのかもしれませんね。
- 今回の練習データでは決定係数も高く、P>|t|の値も良好でした。ただ、この結果から私の家選びの基準を完全に推論できるかというとそうでもなくて、例えば、家がキレイか、ユニットバス/セパレートか、なども個人的に重視するポイントです。確かに家賃も気にはするものの、そういったコンジョイントカードにはない要素が自身の家選びにおける重要項目であることも多いです。そのため、スコア自体がどの要素から来ているかいう予測というよりかは、今回勉強したコンジョイント分析では、カードにある各要素どうしを比較する、という目的で使うことを意識する必要がありそうですね(?)
- コンジョイント分析では、コンジョイントカードの内容がカテゴリーデータなので、数値(例:家賃)が混じるとバリデーションが少なくなったりしてしまいますね。また、今回は等間隔に刻んだので問題なさそうですが、解析上は家賃の差分2万円ということは考慮せず、単にことなるカテゴリーデータとして扱うので、少し違和感がありました。また継続して勉強してみたいと思います。
まとめ
- この記事では、コンジョイント分析を学んだうえで、pythonによるコーディングを行いました。
- コンジョイント分析はここで求めた重みをもとに以下の分析をする手法でした(菅先生「多変量解析」より:冒頭のURLを参照のこと)
① 予測値の算出
② 関係式に用いた項目の目的変数に対する影響度
③ 関係式に用いたカテゴリーの目的変数に対する貢献度 - 家賃を2万円上げることと、大学から遠くなることの負のインパクトがそれぞれ同じくらい、とかどちらのほうが影響が大きい、などが議論できそうです
- 再度のお願いになりますが、間違いなどがあれば教えていただけますと幸いです。
他の記事の一覧はこちらです。 kentapt.hatenablog.com
参考記事
グロービス経営大学院:コンジョイント分析
Pythonでコンジョイント分析に挑戦
説明可能なAI:Score-CAMによる判断根拠の可視化 (Wang et al., CVPR workshop, 2020)
この記事は、MATLAB/Simulink Advent Calendar 2021(カレンダー2)の18日目の記事として書かれています。
はじめに
この記事では、深層学習(ここでは、畳み込み込みニューラルネットワーク)で画像分類を行ったときの、判断根拠の可視化に関して扱います。CAMやgrad-cam, LIMEなどが有名ですが、今回はScore-CAMと呼ばれる手法について勉強したのでここにまとめたいと思います。また、勉強のために、私自身で実装も行いました。

LIMEに関しては、私の別の記事で扱っており、こちらも見ていただけますと幸いです。
実装のためのコードやデータはこちらにアップロードしてあります。 深層学習の結果に対する「なぜ?」を扱う、説明可能AIについては、例えば以下の記事がわかりやすかったです。
本稿で紹介する論文は以下のものです。
こちらのブログで掲載したコードはここにアップロードしています。
著者らによる公式の実装はこちらになります。私のコードもリンクしていただいているようです。 github.com
イントロダクションの和訳
深層学習を用いた画像分類の判断根拠の可視化の方法はいくつか有名なものがあり、本手法との比較などについて気になりました。そこで、以下に、私の勝手な解釈に基づいた論文のイントロダクションの和訳を掲載します。意訳なども含むのでご注意ください。
イントロの中での序論
ディープニューラルネットワーク(DNN)の判断根拠の説明により、人間がそのモデルを解釈する上で重要な、推論におけるいくつかの側面を明らかにすることができる。また、それにより、その推論結果の透明性(や信頼性)を高めることができる。説明の中でも、入力の中で重要な領域や量、または学習された重みを可視化することは、説明性を加えることにおいて、最もわかりやすい方法である。空間畳み込みは、画像処理や言語処理における最先端のモデルを構築するために頻繁に使用される要素技術である。そのため、畳み込み込みニューラルネットワークをよりよく説明するために、多くの研究が行われてきており、勾配の可視化 [15]、摂動(Perturbation:筆者追記ここでは、以前の投稿で紹介したLIMEのこと)[10]、クラス活性化マップ(CAM) [21]の3つが広く用いられてきた。
3つの代表的な方法の概要とその問題点
勾配に基づく方法では、対象のクラスに関わる勾配を逆誤差伝搬し、その推論に影響している画像中の領域をハイライトするものである。(つまり、そこで得られる)Saliency Map (顕著性マップ)[15] は、入力画像に対するターゲットクラスのスコアの微分をを行い、その推論結果を説明している。その他の先行研究[1, 8, 17, 18, 20]では、その勾配情報にさらに操作を加えることで、結果を視覚的に鮮明にする。しかし、これらのマップは一般的に低品質でノイズを多く含む[8]という問題がある。
摂動に基づくアプローチ[3, 5, 6, 9, 10, 19]は、入力画像に摂動を与え、その摂動を与えた画像に対する、予測値の変化を観察する。しかし、最小領域を見つけるために、これらのアプローチは通常は正則化[6]を追加する必要があり、さらに、計算量が多いというデメリットがある。
CAM (Class Activation Mapping) ベースの説明 [4, 12, 21] も同様に、視覚的な判断根拠の説明を得ることのできる方法である。そこでは、単一の入力画像に対して行い、推論時の活性化マップと、そのマップにそれぞれ係数を与え足し合わせたもので組み合わせで判断根拠の説明のためのヒートマップ作成した。しかし、その手法は、適用可能なCNNの構造に制限があり、グローバルプーリング層 [7] が必要である。
提案手法の必要性
Grad-CAM [12]や、そこから派生したもの、例えばGrad-CAM++ [4]などでは、グローバルプーリング層を持たないモデルにもCAMが適用できるように一般化した。これらの研究では、勾配情報の使用を再検討したが、それと同時に、GradCAMは、CAMをさらに一般化するためには、勾配の利用は必ずしも理想的ではない、ということにも言及している。本研究では、勾配の情報をもとに行うアプローチであるCAMの制約に言及し、それに対処するために、新たな判断根拠の可視化手法である、Score-CAMを提案する。Score-CAMでは、局所的な感度測定(=勾配を用いた方法)の代わりに、学習済みのCNNにて特定の画像を推論した時の活性化マップを用いる。その活性化マップにしたがって生成した(微調整した)画像をそのCNNに入力して得たときの結果をもとに、その分類の重要度を可視化する。
Score-CAMのアピールポイント
本研究での、我々の貢献は以下の通りである。
(1) 勾配を用いない、新しい判断根拠の可視化手法を提案する。ここでは、摂動に基づく方法(LIMEなど)とCAMに基づく方法のギャップを埋め(両方のいいところどりをし、という意味に近い?)、そして、活性化マップや重み付けを用いた直感的に理解しやすい方法を開発した。
(2) Average Drop / Average Increase and Deletion curve / Insertion curveなどの指標にて本手法を定量的に評価した。そして、Score-CAMがより良い結果を有することを確認した。
(3) 可視化および判断根拠の位置の正しさを定性的に評価し、両タスクで良好な結果を得ることができた。最後に、CNNモデル自体の解析のためのツールとしてのScore-CAMの有効性を述べる。
以上が、Score-CAMの論文のイントロダクションの和訳になります。CAMは、グローバルプーリング層が最後のほうにないとできないので、使えるモデルが限られてしまったり、その構造を再度追加して、再学習などが必要になりますね。ここでは、「摂動を加える」と表現されている、例えば上の記事で紹介したようなLIMEでは、多くの(例:1000以上)の画像のパターンを作ってそれらの推論結果を使って判断根拠の可視化結果(ヒートマップ)を作る必要があるので、計算時間において課題はありそうです。grad-camも、smooth-gradなどの方法もあるものの、そもそも勾配を直接的に使わない方法はないか?と考えている、という流れだったと理解しました。
Score-CAMの大まかな流れ
1 . テストしたい画像と、学習済みのCNNを用意し、その画像を推論する
下の図はAlexNetを例にCNNの構造をdeepNetworkDesignerで可視化しています。

2 . 1のようにCNNを用意して推論をしていくと、それぞれの層で演算していくと、畳み込み込み演算やプーリングによって、空間的な(XY方向の)サイズが小さくなっていくことがわかります

3 . 後半の活性化マップを取り出します。論文では、l番目の層と書いてありましたが、最後の畳み込み込み層の結果を設定するのがよいとのことです(3.1.の後半 : the last convolution layer is a more preferable choice)。しかし、その層の演算結果がM×N×Cの形をしていれば、計算自体はどの層でも行えそうです。
4 . その活性化マップを入力のサイズまで拡大(上の例ではサイズが13×13で入力が224×224とすると、そのサイズまで拡大する)
5 . その活性化マップを取り出し、それぞれのチャンネルを0~1になるように正規化する(上の例だと256個あるので256回)

6 . 入力画像と上の0\textasciitilde{}1に正規化された画像を掛け合わせ、その画像をCNNで分類し、対象のクラス(例:猫)のスコアを取得する。ここでのスコアとは最後のsoftmax層の後に正規化された値を指します。論文中では以下の記述がありました。
The relative output value (post softmax) after normalization is more reasonable to measure the relevance than absolute output value (pre-softmax).

7 . 各活性化マップにその時の画像で推論したときのスコアを書けて足し合わせる(以下の補足2のところの図によると、もとの画像で推論したときのスコアを引いたうえでこの計算を行っているようです)
例:上の猫の画像の左上のもので推論をして、猫のスコアが0.8だったとする。また、もとの画像で推論を行ったときの猫のスコアを0.7とする。そのとき、左上のものを生成するのに用いた活性化マップと0.1 (0.8-0.70) を掛け合わせる。この操作をすべてのチャンネル(この例では256)に対して行い、足し合わせる。
8 . 7で得たもので0以下の値は0にする
because we are only interested in the features that have a positive influence on the class of interest
まとめると以下の図のようになります。
 図出典:もとの論文Fig. 3
図出典:もとの論文Fig. 3
参考サイト
この章は、下の記事ともとの論文を参考にさせていただきました。
補足
1 スコアの値をsoftmaxの前とするか後とするか
- この論文では、softmax後のスコアを重みとして利用することを述べていました。図5に前と後の値をそれぞれ用いたときの結果を示しています。

2 アルゴリズムの流れ
Algorithm 1にコメントを加えています。
 3. Sanity Check
3. Sanity Check
ここでは、ヒートマップの確からしさをSanity Checkとよばれる方法にて確かめています。
以下のようなわかりやすくまとめている記事がありました。
簡単なまとめ
- 活性化マップを入力画像と掛け合わせ、一部をハイライトした画像を用いて再度推論を行いました
- そのハイライトした画像で推論したときの結果(スコア)をもとに、その活性化マップの重要度を決定しました
- その重要度を掛け合わせ、すべての活性化マップ分だけ足し合わせたものを判断根拠の可視化をした画像として扱いました
MATLABでの実装
ここからは、MATLABで実装したときのコードになります。
再度の掲載になりますが、こちらのコードはここにアップロードしています。
学習済みネットワークのインポート
CNNで分類するための、学習済みのネットワークをインポートします。本実装のライブスクリプトではプルダウンからSqueezeNet, GoogLeNet, ResNet-18, MobileNet-v2が利用可能です。
clear;clc;close all netName = "squeezenet"; net = eval(netName);
画像サイズと活性化マップを得るための層の名前を抽出
activationLayerName という補助関数がスクリプトの最後に定義されています。この関数によって、それぞれのネットワークに適切な層の名前を指定してくれます。これにより活性化マップを得ることができます
inputSize = net.Layers(1).InputSize(1:2); classes = net.Layers(end).Classes; layerName = activationLayerName(netName);
画像の読み込みとリサイズ.
im = imread('CatImg.png');
imResized = imresize(im,[inputSize(1:2)]);
CNNで画像を分類
[PredCategory,scoreBaseLine]=classify(net,imResized); PredCategory
PredCategory =
Norwegian elkhound
CNNで分類された結果のインデックス(番号)を取得します。
classIdx=find((net.Layers(end, 1).Classes==PredCategory)==1);
activation 関数を用いて活性化マップを得る
featureMap = activations(net,imResized,layerName);
MapDim=size(featureMap,3);
idx=randi(MapDim,[1 1]);
figure;imagesc(normalize(featureMap(:,:,idx),'range'));title('example of the feature map');colorbar

入力画像と活性化マップを掛け合わせる
ここでは、以下の計算を行います
- . 活性化マップのあたいを0から1に正規化する(
normalize関数) - . 活性化マップを3チャンネルに拡張(同じモノをチャンネル方向に重なる)
- . それぞれのピクセルどうしを掛け合わせる
featureMap_normalized=zeros([inputSize,MapDim]);
for i=1:size(featureMap,3)
featureMap_resized(:,:,i)=imresize(featureMap(:,:,i),inputSize,'Method',"bilinear");
featureMap_normalized(:,:,i) = normalize(featureMap_resized(:,:,i),'range');
featureMap_layered_i=cat(3,featureMap_normalized(:,:,i),featureMap_normalized(:,:,i),featureMap_normalized(:,:,i));
maskedInputImg(:,:,:,i)=featureMap_layered_i.*double(imResized);
end
その例を表示
figure;idx=randi(MapDim,[12 1]);
exImg=maskedInputImg(:,:,:,idx);
montage(uint8(exImg));title('example of masked images for input')

マスクされた画像にて推論する
classify関数を用いて、対象のクラスのスコアを算出する
% specify minibatch size. Return an error if the memory is not enough % score: (the number of test image)-by-(the number of class (1000)) [PredCategory,score]=classify(net,uint8(maskedInputImg),'MiniBatchSize',32); score_target_class=score(:,classIdx); CIC=score_target_class-scoreBaseLine(classIdx); CIC_norm=softmax(CIC);
各活性化マップとそのマップで加工した結果で推論したときのスコアを掛け合わせる
score_CAM_prep=featureMap_normalized.*reshape(CIC_norm,[1 1 numel(CIC_norm)]); score_CAM_sum=sum(score_CAM_prep,3);
0以下の値を0に丸める(ReLUと同様の操作)
score_CAM_sum(score_CAM_sum<0)=0;
可視化のために、0から1に正規化する
score_CAM_scaled=normalize(score_CAM_sum,'range');
可視化のための下準備
cmap = jet(255).*linspace(0,1,255)'; score_CAM = ind2rgb(uint8(score_CAM_scaled*255),cmap)*255;
入力画像と重ね合わせ
combinedImage = double(rgb2gray(imResized))/2 + score_CAM; combinedImage = normalizeImage(combinedImage)*255;
表示
figure;imshow(uint8(combinedImage));colorbar;colormap('jet')

補助関数
function N = normalizeImage(I) minimum = min(I(:)); maximum = max(I(:)); N = (I-minimum)/(maximum-minimum); end
活性化マップを得るための層の名前を取得する関数
function layerName = activationLayerName(netName)
if netName == "squeezenet"
layerName = 'conv10';
elseif netName == "googlenet"
layerName = 'inception_5b-output';
elseif netName == "resnet18"
layerName = 'res5b';
elseif netName == "mobilenetv2"
layerName = 'Conv_1';
elseif netName == "vgg16"
layerName = 'conv5_3';
elseif netName == "alexnet"
layerName = 'conv5';
end
end
終わりに
- こちらの記事では、Score-CAMとよばれる方法を勉強し、実装した例を示しました
- コメントや勉強会のお誘いなどございましたら、linkedinやmatlab central、githubにあるメールアドレスなどからご連絡いただけると幸いです。 kentapt.hatenablog.com
参考文献
[1] Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., Mardziel, P. and Hu, X., 2020. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 24-25).
[2] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. and Torralba, A., 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2921-2929).
本稿のほかに、MATLAB/Simulink Advent Calendar 2021のために書かれた別の記事もあり、こちらも見ていただけますと幸いです。
ナイーブベイズを用いた迷惑メールの検出をやってみた
この記事は、MATLAB/Simulink Advent Calendar 2021(カレンダー2)の13日目の記事として書かれています。
この記事では、ナイーブベイズと呼ばれる手法を用いて、ある文面をみて、それが迷惑メールかどうかを判別します。 注意 筆者はこの分野の全くの素人で、あくまで「入門してみた」という記事になります。間違いなどがあれば、教えていただけますと幸いです。 こちらの記事で用いたコードはこちらにアップデートしています。何かの役に立てば嬉しいです。
github.com MATLAB file exchangeにも紐づいていて、ここからもダウンロードすることができます。
この例のほかにLSTM(long short term memory)と呼ばれる手法を用いたものもアップロードしてあります。
入門するにあたって勉強させていただいたWEBページ
これらの記事を参考にさせていただきました。
https://jp.mathworks.com/help/textanalytics/ug/classify-text-data-using-deep-learning.html
入門するにあたって読んだ論文
初学者でも読める論文がないか探してみると以下のものが見つかりました [1]。2021年12月12日時点で、引用数は450で、たくさん引用されてるようですし、私も一部読んでみることにしました。
イントロダクションの和訳
以下に、私の勝手な解釈に基づいた論文のイントロダクションの和訳を掲載します。意訳なども含むのでご注意ください。
テキストマイニングとは、テキストデータから有用な情報を探したり、抽出したりするプロセスです。構造化されていない(決まったフォーマットや方式で保存されておらず、意味の理解の仕方が明らかでない、という意味に近い?)テキストから知識を発見しようとするもので、挑戦的な研究分野です。テキストマイニングは、テキストデータマイニング(Text Data Mining: TDM)やテキストデータベースにおける知識発見(Knowledge Discovery in Textual Databases: KDT)とも呼ばれています。KDTは、テキスト理解のような新しいアプリケーションにおいて、ますます重要な役割を果たしています。テキストマイニングのプロセスはデータマイニングと同じですが、データマイニングのための方法は構造化されたデータを扱うように設計されているのに対し、テキストマイニングは電子メールやHTMLファイル、フルテキスト文書などの構造化されていない、または半構造化データセットを扱うことができます。[1]. テキストマイニングは、さまざまな文書リソースから、これまで認識されていなかった新しい情報を見つけるために使用されます。
構造化データとは、その記録やファイル内にある固定された領域に存在するデータのことです。このデータは、関係データベースやスプレッドシートに含まれています。非構造化データとは、通常、伝統的な行および列からなるデータベースに存在しない情報を指し、構造化データとは正反対のものです。半構造化データとは、生データでもなければ、従来のデータベースシステムに入力されたデータでもないデータのことです。テキストマイニングは、データマイニング、機械学習、情報抽出、自然言語処理、情報検索、知識管理、分類などの分野で発生する問題を解決しようとする、コンピュータサイエンスの新しい研究分野です。図1は、テキストマイニングプロセスの概要を示したものです。

図出展:Vijayarani, S et al. (2015)の図1より
本稿の2章以降は、以下のように構成されています。セクション2では、文献レビューを行います。セクション3では、テキストマイニングのための前処理方法を説明します。セクション4では、分類のためのステミングアルゴリズムについて述べます。結論はセクション5で述べます。
1.1 Applications of Text Mining
情報検索
情報検索(IR)の概念は、長年にわたってデータベースシステムとの関連で発展してきました。情報検索とは、テキストベースの多数の文書から情報を関連付けて検索することです。情報検索システムとデータベースシステムは、それぞれ様々な種類のデータを扱います。データベースシステムの問題の中には、同時実行制御、リカバリ、トランザクション管理、更新など、情報検索システムには通常存在しないものがあります。また、非構造化文書、キーワードに基づく推定検索、関連性の概念など、通常のデータベースシステムにはない一般的な情報検索の問題もあります。膨大な量のテキスト情報があるため、情報検索は多くの用途が見出されています。情報検索システムには,オンラインの図書館のカタログシステム,オンライン文書管理システム、そして近年開発されているようなWeb検索エンジンなどがあります[1].
情報抽出
情報抽出では、テキスト内の重要な単語や関係性を特定します。これは、パターンマッチングと呼ばれるプロセスで、事前に定義された単語の連なりをテキスト内で探すことによって行われます。ソフトウェアは、特定されたすべての場所、人、時間の間の関係を推論し、ユーザーに意味のある情報を提供します。この技術は、大量のテキストを扱う際に非常に有効です。従来のデータマイニングでは、マイニングされる(テキストから掘り起こされる)情報がすでに関係データベースの形で存在していることを前提としてきました。しかし、残念ながら、多くのアプリケーションでは、電子情報は構造化されたデータベースではなく、構造化されていない、自然言語の文書の形でしかアクセスすることができません[1]。このプロセスは,図2に示されています.

図出展:Vijayarani, S et al. (2015)の図2より
テキスト分類
文書分類とは、あらかじめ定義されたトピックにドキュメントをあてはめることで、ドキュメントのメインテーマを特定することです。文書を分類する際、コンピュータプログラムは、多くの場合、文書を「単語の袋」として扱います。情報抽出のように実際の情報を処理しようとはしません。それよりむしろ、カテゴリー化は、出現する単語をカウントし、そのカウント結果から、文書の扱う主要なトピックを特定するということをします。文書分類の結果は、事前に定義された用語集に大きく依存することが多く、それを用いて広義・狭義の用語、同義語、関連語を探すことで文書分類が行われる[4]。
自然言語処理(Natural Language Processing: NLP)は,自然言語を理解・操作するために,コンピュータをどのように利用できるかを探る研究・応用分野です。NLPの研究者は,人間がどのように言語を理解し,使用するかについての知識を収集し、コンピュータシステムが自然言語を理解して操作し,望ましいタスクを実行できるような適切なツールや技術を開発することを目的としています[3].
NLPの基礎は,コンピュータ・情報科学,言語学,数学,電気・電子工学,人工知能・ロボット工学,心理学など,さまざまな分野に存在しています。NLPの応用分野には、機械翻訳、自然言語テキスト処理と要約、ユーザーインターフェース、多言語・異言語情報検索(CLIR)、音声認識、人工知能とエキスパートシステムなど、多くの研究分野が含まれています[3]。
上の和訳の一部は、www.DeepL.com/Translator(無料版)を用いて行われました。
非常に高精度で、一から日本語を打つよりもかなり高速に和訳を終えることができました。自然言語処理の研究が進むと、研究や仕事が捗ったり、これまでできないことが可能になったりと無限の可能性がありそうです。上の和訳をしてみて、自然言語処理入門のやる気がわいてきました。
それでは、入門として、以下のセクションから、ある文面が迷惑メールかどうかを自動的に分類してみようと思います。
データのインポート
今回用いるデータは、こちらにある
SMS Spam Collection Dataset Collection of SMS messages tagged as spam or legitimate というデータセットです。
https://www.kaggle.com/uciml/sms-spam-collection-dataset
以下の赤丸のボタンからダウンロードすることができます。
 合計で、5574件のメール/スパムメールが用意されています。上のURLからデータをダウンロードすると、
合計で、5574件のメール/スパムメールが用意されています。上のURLからデータをダウンロードすると、
spam.csvというファイルを得ることができます。それを読み込んで解析を行うので現在のディレクトリにspam.csvを解凍します。
エクセルにラベルやそれに対応する文章が記録されている場合は、readtable関数を使うと便利です。
変数名をdataとして、エクセルファイルの情報を読み込みます。
head関数にて読み込んだファイルの内容の一部を手軽に確認できます。v1列に迷惑メール(spam)かそうでないか(ham)が書いています。
clear;clc;close all
rng('default')
filename = "spam.csv";
data = readtable(filename,'TextType','string');
head(data)
| v1 | v2 | Var3 | Var4 | Var5 | |
|---|---|---|---|---|---|
| 1 | "ham" | "Go until jurong poi... | '' | ||
| 2 | "ham" | "Ok lar... Joking wi... | '' | ||
| 3 | "spam" | "Free entry in 2 a w... | '' | ||
| 4 | "ham" | "U dun say so early ... | '' | ||
| 5 | "ham" | "Nah I don't think h... | '' | ||
| 6 | "spam" | "FreeMsg Hey there d... | '' | ||
| 7 | "ham" | "Even my brother is ... | '' | ||
| 8 | "ham" | "As per your request... | '' |
あとで、データを分割したいので、それを簡略化するために、エクセルファイルの内容である変数dataの6列目に、カテゴリカル型に変更したラベル情報を格納します。
data.event_type = categorical(data.v1);
次に、データセット中のspam/hamの割合を円グラフにて表します。
f = figure;
pie(data.event_type,{'ham','spam'});
title("Class Distribution")
 スパムメールのデータが全体の13%、そうでないものが87%という構成比率のようです。クラス間でサンプル数が不均衡になっていますが、ひとまず気にせず次に進みます。
スパムメールのデータが全体の13%、そうでないものが87%という構成比率のようです。クラス間でサンプル数が不均衡になっていますが、ひとまず気にせず次に進みます。
訓練・検証・テストデータセットへの分割
まず、全データの7割を訓練データとして切り出します。cvpartition関数に、さきほどのspam/ham情報であるdata.event_typeを入力し、分割の割合を0.3 (0.7) とします。ワークスペースには現れませんが、trainingという変数のようなものに、cvpを入力すれば、訓練データに割り振られるべきするインデックスを返すので、それを利用して、dataTrainを得ます。
cvp = cvpartition(data.event_type,'Holdout',0.3); dataTrain = data(training(cvp),:); dataHeldOut = data(test(cvp),:);
同様に、さきほどの分割でわけられた3割のほうのデータを検証データとテストデータに分割します。
cvp = cvpartition(dataHeldOut.event_type,'HoldOut',0.5); dataValidation = dataHeldOut(training(cvp),:); dataTest = dataHeldOut(test(cvp),:);
上で分けたデータから、学習などに使うためのテキストデータやラベル情報を取り出します。上の表でも示した通り、v2という列にメールの文章が格納されているので、その情報を参照します。
textDataTrain = dataTrain.v2; textDataValidation = dataValidation.v2; textDataTest = dataTest.v2; YTrain = dataTrain.event_type; YValidation = dataValidation.event_type; YTest = dataTest.event_type;
wordcloud関数で、訓練データに含まれている単語やその頻度を可視化します。単語の大きさは、その頻度に対応しています。
figure
wordcloud(textDataTrain)
title("Training Data")

テキストデータの前処理
テキストデータを処理する際は、前処理が非常に重要であるそうです。例えば、こちらは、以下のブログからの引用ですが、図にあるような前処理が考えられます。
 画像出典:Hironsanさま「自然言語処理における前処理の種類とその威力」より
画像出典:Hironsanさま「自然言語処理における前処理の種類とその威力」より
このほかにも、以下のブログなどが参考になりました。
さきほど和訳した論文にも、詳しく前処理の種類が解説してあります。ただ、今回は「入門してみた」のところまで到達したいため、割愛させていただきます。
ひとまず、こちらの詳細は置いておいて、以下の前処理を行い、解析に移っていきます。
このドキュメントの最後に補助関数として置いているpreprocessTextを用いて、テキストデータの前処理を行っていきます。
例えば、訓練データである4000件ほどのテキストに対して、以下の3つの操作を行います。
1.それぞれの文章を字句にわける。例)an example of a short sentence => an + example + of + a + short + sentence
- それぞれの分けた文字列を小文字にする 例)Hello World => hello world
3. 句読点や、「 ’ 」を消す
documentsTrain = preprocessText(textDataTrain); documentsValidation = preprocessText(textDataValidation); documentsTest = preprocessText(textDataTest);
こうして処理した文章のうち5つを例として表示します。大文字やコンマがないことが確認できます。
documentsTrain(1:5)
ans =
5x1 tokenizedDocument:
6 個のトークン: ok lar joking wif u oni
32 個のトークン: free entry in 2 a wkly comp to win fa cup final tkts 21st may 2005 text fa to 87121 to receive entry question std txt rate t cs apply 08452810075over18 s
11 個のトークン: u dun say so early hor u c already then say
13 個のトークン: nah i dont think he goes to usf he lives around here though
33 個のトークン: freemsg hey there darling its been 3 weeks now and no word back id like some fun you up for it still tb ok xxx std chgs to send 螢 150 to rcv
今回のように頻度をベースに分類を行う場合、Iやtoなどの一般的に広く使われる単語の頻度はあまり分類に寄与しないと考えられます。そこで、以下のsequence2freq関数で処理する際に、よく見られる単語はカウントしないように制御します(stop word)。
stopWordsという名前であらかじめ削除すべき単語が用意されていて、removeWords関数と併用することでそれぞれのテキストからstop wordsを削除することができます。
https://jp.mathworks.com/help/textanalytics/ref/stopwords.html
documentsTrain = removeWords(documentsTrain,stopWords); documentsValidation = removeWords(documentsValidation,stopWords); documentsTest = removeWords(documentsTest,stopWords); documentsTrain(1:5)
ans =
5x1 tokenizedDocument:
6 個のトークン: ok lar joking wif u oni
26 個のトークン: free entry 2 wkly comp win fa cup final tkts 21st 2005 text fa 87121 receive entry question std txt rate t cs apply 08452810075over18 s
9 個のトークン: u dun say early hor u c already say
7 個のトークン: nah think goes usf lives around though
21 個のトークン: freemsg hey darling 3 weeks word back id like fun up still tb ok xxx std chgs send 螢 150 rcv
テキストの出現頻度の計算
今回の例では、訓練データで観測された全単語を調査し、それぞれの単語に一意の背番号を与えます。
wordEncoding関数に対して、訓練データを入力として与えます。
また、'Order',"frequency"とすれば登録する単語の順番を、訓練データで観測された頻度の順番になります。
enc = wordEncoding(documentsTrain,'Order',"frequency",'MaxNumWords',6000);
次に、doc2sequence関数を用いて、それぞれの文章を、単語の背番号で表します。
例えば、文章が、I like baseball で、I: 19, like: 78, baseball: 99 のように登録されていた場合は、
XTrain = [19 78 99]のようなベクトルに変換されます。
XTrain = doc2sequence(enc,documentsTrain,'PaddingDirection','none');
変換後のXTrainの一部を表示します。数字の羅列で表現されていることがわかります。
XTrain{3001:3003}
ans = 1x7
191 559 276 15 144 1686 798
ans = 1x18
291 15 267 421 186 258 591 363 734 103 199 1499 71 255 36 734 186 71
ans = 1x11
4 1573 126 1147 1802 86 336 47 448 4 2403
さきほど、wordEncoding関数を使った際に、頻度の順番で単語を登録するように設定しました。
ind2word関数を用いて、変数encに登録されている単語の順番(インデックス)から、どの単語が登録されているかを参照することができます。たとえば、以下の操作で最も多く観測された単語上位20個を見ることができます。なお、stop wordsは削除されているので、それらは表示されません。
idx = [1:20]; words = ind2word(enc,idx)
words = 1x20 string "u" "call" "2" "just" "get" "ur" "螢" "gt" "lt" "up" "4" "ok" "free" "go" "got" "like" ":)" "good" "come" "know"
次に、このドキュメントの最後にある補助関数sequence2freqを用いて、それぞれの文章に、どの単語が何回出現したかを集計します。
例えば、文章が単語の背番号を用いて、[3 1 2 2 5 3]という文章で表されていたら、それぞれの単語の頻度は以下のようになります。
[1 2 2 0 1 0 0 0 ...]
ここで、訓練データで観測された単語に対して調べられるので、5以降の単語に対しても頻度の計算が行われます(頻度0が返されます)。訓練データで観測された総単語数に対して、それぞれの文章は小さいので、こちらの頻度のデータは、0が非常に多くなります。
XTrainFreq=sequence2freq(XTrain,enc);
同様に検証データ・テストデータも処理を行います。
XValidation = doc2sequence(enc,documentsValidation,'PaddingDirection','none'); XValidationFreq=sequence2freq(XValidation,enc); XTest = doc2sequence(enc,documentsTest,'PaddingDirection','none'); XTestFreq=sequence2freq(XTest,enc);
以上の操作で、訓練・検証・テストデータのそれぞれの文章について、どの単語がどれくらいの頻度で出現するかを集計することができました。頻度という特徴と迷惑メールかどうかというラベルをもとに、訓練や検証を行っていきます。
訓練データに対する、ナイーブベイズの実行
fitcnb関数でナイーブベイズを用いた訓練を行うことができます。今回の訓練データは上述したように0の多いものとなっています。そのため、分布を多項分布を仮定します。'DistributionNames','mn'として宣言することができます。また、事前分布は訓練データのspam/hamの割合を採用します。'Prior','empirical'と宣言すればよいです。
Mdl = fitcnb(XTrainFreq,YTrain,'DistributionNames','mn','Prior','empirical');
predict関数に、上で作成したモデルと、検証データを入力することで、検証データの予測を行うことができます。
Ypred_Validation=predict(Mdl,XValidationFreq);
混合行列を作成し、予測内容の分布を確認します。
confusionchart(YValidation,Ypred_Validation)

テストデータの予測
上の検証結果が十分であれば最後に上と同様にしてテストデータの予測やその評価を行っていきます。
[YPred_Test,Posterior,Cost]=predict(Mdl,XTestFreq); confusionchart(YTest,YPred_Test)

Mdl.Prior
ans = 1x2
0.8659 0.1341
accuracy = mean(YTest==YPred_Test)
accuracy = 0.9832
間違えた例の確認
逆にどのような場合に間違えたのか確認してみます。確かにきわどいところで間違っているような...?
wrong_ind=find(YTest~=YPred_Test);
incorrectExample=table(YTest(wrong_ind(1:5)),YPred_Test(wrong_ind(1:5)),textDataTest(wrong_ind(1:5)));
incorrectExample.Properties.VariableNames = {'ground truth','predicted','text'}
| ground truth | predicted | text | |
|---|---|---|---|
| 1 | spam | ham | "Did you hear about ... |
| 2 | spam | ham | "Do you realize that... |
| 3 | spam | ham | "Ever thought about ... |
| 4 | spam | ham | "88066 FROM 88066 LO... |
| 5 | ham | spam | "How much did ur hdd... |
98% 以上の高い精度で、迷惑メールかどうかを判別することができました。今回の例では、それぞれの単語の頻度をもとに分類を行っていて、単語同士の関連や順番などは考慮していません。もう1つの例である、LSTMを用いた分類では、単語をベクトルに変換し、時系列的に扱っています。よろしければそちらもご参照ください。
おまけ:自分で作成したテキストの分類
自分で作成した文章を今回の分類器にてspamかどうか判断させることができます。例えば以下のように3つの文章を用意します。
reportsNew = [ ...
"please visit this webpage to get the special discount."
"you can subscribe this online journal for free for one year"
"please let me know when your paper is ready to submit."];
先ほどと同様に前処理等を進めていきます。
documentsNew = preprocessText(reportsNew); XNew = doc2sequence(enc,documentsNew,'PaddingDirection','none'); XNewFreq=sequence2freq(XNew,enc);
predict関数に入力します。
[YPred_New,PosteriorNew,CostNew]=predict(Mdl,XNewFreq)
YPred_New = 3x1 categorical
spam
ham
ham
PosteriorNew = 3x2
0.3639 0.6361
0.6939 0.3061
0.9998 0.0002
CostNew = 3x2
0.6361 0.3639
0.3061 0.6939
0.0002 0.9998
上から順に、spam, ham, hamと判断されていることがわかります。
まとめ
- . この記事では、MATLABを用いて迷惑メールの分類という課題を通して、言語処理の入門を行いました
- . テキストを処理する方法は全く想像がつきませんでしたが、ここでは、単語の頻度などを特徴として用いていて、ある程度直感的にわかりやすいものでした
- . 今回はナイーブベイズを用いて分類を行いましたが、なぜそのアルゴリズムを用いたかということは記述できていません。例えば、以下のネットの記事や、そこで紹介されている以下の書籍をみて勉強しました。非常にわかりやすかったです。私の理解では、迷惑メールでは、日々、迷惑メールボックスにメールが溜まっていくので、その都度そのデータを加えて学習しなおす、ということは現実的ではありません。しかし、ナイーブベイズを用いた方法では、新たに加わった迷惑メールをもとに、その学習器を更新できるので、その学習器の維持管理などもやりやすく、迷惑メールの分類によく使われているのではないかと理解しました。
https://diamond.jp/articles/-/82289(diamond.jp]
完全独習 ベイズ統計学入門 | 小島 寛之 |本 | 通販 | Amazon
こちら、冒頭でも述べましたが、筆者が、入門した記事であるため、誤りなどがあるかもしれません。その場合は教えていただけますと幸いです。
補助関数
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Convert to lowercase. documents = lower(documents); % Erase punctuation. documents = erasePunctuation(documents); end
function freq=sequence2freq(sequence,enc)
numWords=enc.NumWords;
freq=zeros(numel(sequence),numWords-1);
edges = (1:numWords);
for i=1:numel(sequence)
freq(i,:)=histcounts(sequence{i},edges);
end
end