シンプルかつ高精度な姿勢推定の手法について学んでみた(Xiao et al., ECCV, 2018)
この記事は、MATLAB/Simulink Advent Calendar 2021(カレンダー2)の12日目の記事として書かれています。
qiita.com 本記事で紹介するネットワークで動画から姿勢推定をした時の結果の例 また、7日目や8日目(カレンダー1)でも記事を投稿していて、もしよろしければこちらもご覧いただけると幸いです。
この記事での取り組みは以下のような姿勢推定と呼ばれるものです。自動的に人間の腕や頭、足の情報を取得できていることがわかります。この手法について、私のほうで論文やコードを見ながら勉強したので、ここで、共有させていただきたいと思います。ここでは、姿勢推定のみを扱います。間違いや誤字などがあれば教えていただけますと幸いです。
 この記事で紹介する手法を用いて、動画から姿勢推定を行ったときの結果の例
この記事で紹介する手法を用いて、動画から姿勢推定を行ったときの結果の例
動画出展:pixabay(フリー動画素材: URL)
このように、いい感じに、骨格の情報を画像から推定できていて、見ているだけでも楽しいだけでなく、実際に姿勢推定は産業系(製造・建設など)やスポーツ、研究・教育用途、エンターテインメント、医療・リハビリなど多くの業界で役立つようです。
なお、ここで紹介する実装は、私自身でなく、こちらのTohruKさんのものです。非常にわかりやすいコードで大変勉強になりました。ありがとうございました。
紹介する手法について
この記事では、Xiaoら(2018)の Simple Baselines for Human Pose Estimation and Trackingという論文で提案されている手法について取り上げます。この手法の特徴としては、
- シンプルな手法である
- 高精度である
- 他の手法と比べる際のベースライン(基準)になりえる
- よりアップデートされたモデルを考える手助けになる
- これらのタスクの評価が簡単になる
といった感じだと思います。この手法だけでなく、多くの手法が提案されていて、この手法の特徴や立ち位置については、実際にもととなる論文のイントロダクションを読むのが良いと思います。以下に、私の勝手な解釈に基づいた論文のイントロダクションの和訳を掲載します。意訳なども含むのでご注意ください。
もととなる論文のイントロダクションの和訳
多く存在するコンピュータービジョンでの課題と同様に、人間の姿勢推定は、深層学習の利用によって大きく進歩した。参考文献[31, 30]で報告されたような、先駆的な研究がされて以来,MPIIベンチマーク[3]での性能は3年で向上し、現在は飽和状態になっている。約80%から始まり、現在は、90%以上[22, 8, 7, 33]となっている。しかし最近公開された、より難易度の高いベンチマークであるCOCO human pose benchmark [20]では、さらなる発展が日々繰り返されている。mAP (mean Average Precision)という指標にておいては、60.5(COCO 2016 Challenge winner [9, 5])から1年で72.1(COCO 2017 Challenge winner [6, 9])まで向上した。このように姿勢推定の急速な発展に伴い、「in the wildな姿勢検出と追跡の同時実行」という、より困難な課題が発生した。(筆者追記:in the wildとは、本稿参考文献[2]では、in real images taken in unconstrained environmentsと言い換えられていて、より自然で制約のない状況で撮られた画像、といった解釈でよいと思います。その逆の撮影方法として、例えば、「この光源でこの条件で撮るぞ」といったような制約があって、取得される画像の幅が限定的であるものを言うのではないかと理解しています)そこでは、“simultaneous pose detection and tracking in the wild”という、より挑戦的な課題が最近発表された[2]。
テストをするデータセットがより複雑になっているだけでなく、それと同時に,深層学習モデルのネットワーク構造や実験のやり方もどんどん複雑化している。そのため,アルゴリズムの分析と比較がより困難になっている。例えば,MPIIベンチマーク[3]における主要な手法[22, 8, 7, 33]は,その方法において、非常に大きな違いがある一方、精度面は差はわずかである。これらを比較・検討するにあたって、どの部分が重要なのかを判断するのは困難である。また、COCOベンチマークの代表的な手法[21, 24, 12, 6, 5]も複雑であるうえ、それらにも大きな違いが存在する。これらの手法の比較は、ほとんどがそのシステム全体での比較にとどまり、あまり参考にはなりにくい。一方、姿勢のトラッキングについては、これまではあまり研究されてこなかったが[2]、その課題設定がより複雑になり、解決方法もより複雑になることで、解決策も多様になり、それを解くモデルの複雑さもさらに増すことが予想される。
本研究では、別の視点から疑問を投げかけ、検討することで、これらの問題を解決することを図る。その問いとは、「シンプルな手法では、どれくらい姿勢推定や姿勢のトラッキングの問題を解くことができるのであろうか?」ということで、ここでは、姿勢推定やトラッキングのためのシンプルな深層学習のモデルを提案する。これらのモデルは非常にシンプルでありつつ、精度の高いものとなっている。そのため、そのシンプルなモデルを起点に新しいより高精度なモデルの開発に向けたアイデアを導いたり、その課題に対する評価を単純化するのに役立つことが期待される。(筆者追記:私の勝手な理解では、シンプルかつ高精度なモデルがあると、そこからプラスアルファとして何ができるか?ということを考えて実行できる。そして、それをいい意味での「踏み台」として使うことで、その姿勢推定などの課題に対する、より高い精度が出しやすくなるのでいいよね、という意味だと思っています)本論文で提案されたモデルのコードと、学習されたモデルは、研究者コミュニティのために公開される予定である。
我々の姿勢推定モデルは、バックボーン・ネットワークであるResNet[13]に、いくつかの逆畳み込み層(転置畳み込み層)を付加することで構成されている。これは、深い層を持ち、かつ低解像度な特徴マップからヒートマップを推定するタイプでは、おそらく最も単純な方法でありながら、COCOテストにおいて、mAP 73.7という最も高い精度を記録した。これは、前回の最良のモデルの持つ精度に比べ、1.6%の精度向上であった(筆者追記:ここでは、アンサンブルモデル(同様のモデルを複数利用することで精度向上をさせる技術)に対する記述もありましたが、和訳には反映させていません)。
我々の姿勢追跡に関しては,ICCV'17 PoseTrack Challenge [2]の優勝者[11]と同様のパイプラインを採用している。一方、姿勢推定には、先述したような独自の手法を用いている。姿勢追跡は、[11]と同様に”グレディ・マッチング手法”を使用している。唯一の改良点は、オプティカルフローに基づいた姿勢のフレーム間の連続性と類似性を利用したことである。本稿での最良の結果では、mAPスコア74.6、MOTAスコア57.8を達成し、これは,ICCV'17 PoseTringの優勝者である59.6と51.8に対し、それぞれ15%と6%の改善であり、最高レベルの精度を有する。
本手法、理論的な根拠に基づくものではなく、シンプルな技術に基づいている。アブレーション実験(1つの入力を省いて出力結果を得ることを繰り返し、どの入力が重要であるかを検討すること)をくまなく行い、有用性を検証してはいるものの、先行手法に対するアルゴリズムそのものの優位性を主張するものではないことに注意していただきたい。結果(精度)自体は良いものの、従来の手法と公平条件で比較を行っているわけではなく、アルゴリズムの優位性は主張するものではない。先述したように、本研究の貢献は、この分野におけるベースラインを提案することである。
このように、高い精度を目指すのではなく、シンプルかつ高精度なモデルを提案して、今後の研究に対する比較対象にしたり、改良を目指すときのたたき台になるのではないか、という方向性で発表されています。
ネットワークの内容
概要について
下の図1の赤枠で囲まれたものが、この本稿で紹介するネットワークの構成です。別の高精度なモデル (a) (b)に比べ、シンプルな構造であることがわかると思います。

図1:モデルの構成について
入力:(ひとりの)人の画像
出力:ヒートマップ になっています。

図2:ヒートマップのイメージ
ヒートマップとは?
出力がヒートマップになっているとはどういうことなのでしょうか。下の図3を見てください。こちらは、今回のネットワークの訓練データのイメージです。各骨格のキーポイントに17までの数字が割り振られています。上の図2の動画は、17までのキーポイントの位置のイメージで、各キーポイントの中心(図3の左の図の大きめの点)をじんわりと周りに広げた(にじませた)ものです。論文では、ガウシアンフィルタを用いてこのじんわりとしたヒートマップを作る(平滑化させる)とありました。このネットワークでのこのヒートマップを出力することを目指します。つまり、(縦)×(横)×(推定する骨格(肘や膝、頭など)の個数)のサイズを持つ値を出力します。ここでは、骨格の個数を17とすると、(縦)×(横)×17になります。それぞれのチャンネル(17個の奥行方向の出力)がそれぞれのポイント(例:鼻、肘、膝)を担当していて、そのポイントがありそうなところをヒートマップで表します。つまり、画像の中心に右ひじがありそうであれば、右ひじ担当のヒートマップは真ん中が高い値でそれ以外が低い値のヒートマップになるべきです。

図3:正解データのヒートマップについて
画像出典:A 2019 guide to Human Pose Estimation with Deep Learning
学習について
学習では、入力画像に畳み込み込み演算などをし、XY方向に解像度の低い特徴マップを得たのちに、さらに逆畳み込み(転置畳み込み)によって、アップサンプリングしていきます。出力は上で述べたヒートマップをターゲットとする骨格の数(例:17)だけ生成します。そして、ネットワークの生成したヒートマップ×17個分と、正解データのヒートマップの差分(ここでは平均二乗誤差)が少なくなるようにどんどんネットワークの重みやバイアスを更新していきます。
アップサンプリングについて
畳み込みをすれば以下の動画のように、画像(入力)のサイズが小さくなることはイメージがつきやすい一方で、アップサンプリングはどうすればいよいのでしょうか。

動画出展:Machine Learning Notebook
アップサンプリングでは、strideとよばれるパラメータに応じて、空白を作ります。以下の動画では、下の水色が入力で、緑が畳み込みをした後の結果のイメージです。ここではstrideを1にして、間に1つグリッドを入れてサイズを大きくしています。そしてそれを畳み込みをすることで出力のサイズが大きくなっていることがわかります。詳しくは以下のサイトなどにわかりやすく解説されていました。

参考にさせていただいた記事:
MathWorks Japan 画像分野におけるディープラーニングの新展開:
https://www.matlabexpo.com/content/dam/mathworks/mathworks-dot-com/images/events/matlabexpo/jp/2017/b1-image-processing-for-deep-learning.pdf
ネットワークを試してみる
訓練の際の詳細などはかけていませんが、ひとまず以上で本手法のおおまかな流れは切り上げて、実際の画像に対してテストしてみたいと思います。ここでは、COCOデータセットを用いて訓練済みのネットワークをインポートしてテストしていきます。
ここで用いたコードは、こちらにあります。動画に対して実行しGIFに保存するようにTohruK様のオリジナルのリポジトリのものから変更しています。また、このテストに必要なファイルのみアップロードしています。 github.com
Step1: 学習済みモデルのロード
clear;clc;close all
addpath('src')
addpath('src/data') % scrフォルダを見えるように
detector = posenet.PoseEstimator; % 学習済みモデルのインポート
% テストにおけるパラメータ
interval=3; % 計算速度アップのため、フレームを間引いて実行
DelayTime=0.03; % 生成するGIFファイルの切り替わりの秒数
step2: テストする動画の読み込み
Office_39890.mp4を読み込みます(動画出展:pixabay(フリー動画素材: URL))。
videoName='Office_39890.mp4'; vidObj = VideoReader(videoName); % ビデオ読み込みの準備 [~,mainName,~]=fileparts(videoName); % GIFへの保存の準備 filename=[mainName,'_output.gif']; % 動画名+ _output.gifで保存 count=1; % フレームの間引き用のカウンター
step3: フレームごとに繰り返し操作
figure('Visible',"on")
while hasFrame(vidObj)
I=readFrame(vidObj); % 次のフレームを読み込み
if mod(count,interval)==0 % 間引き
ACF検出器を用いて画像中の人の検出
[bboxes,scores] = detectPeopleACF(I,'Threshold',-5); % battingCage.mp4の場合は、'Threshold',-5のとき良好な人の検出ができた
if ~isempty(scores) % 人が検出されたときのみ実行
検出されたそれぞれの人の領域を切り出しおよびそのバウンディングボックス情報の抽出
[croppedImages, croppedBBoxes] = detector.normalizeBBoxes(I, bboxes);
ヒートマップに変換
heatmaps = detector.predict(croppedImages);
Iheatmaps = detector.visualizeHeatmaps(heatmaps, croppedImages);
ヒートマップからキーポイントを生成
keypoints = detector.heatmaps2Keypoints(heatmaps);
Iheatmaps = detector.visualizeKeyPoints(Iheatmaps,keypoints);
キーポイントを可視化
Iout_keyPoints = detector.visualizeKeyPointsMultiple(I,keypoints,croppedBBoxes);
imshow(Iout_keyPoints);drawnow
else % 人が検出されなかった場合はフレームをそのまま表示
Iout_keyPoints=I;
imshow(I)
end
% GIFの容量削減のためリサイズ
Iout_keyPoints=imresize(Iout_keyPoints,0.35);
[A,map] = rgb2ind(Iout_keyPoints,256);
if count == interval
imwrite(A,map,filename,'gif','LoopCount',Inf,'DelayTime',DelayTime)
else
imwrite(A,map,filename,'gif','WriteMode','append','DelayTime',DelayTime);
end
end
count=count+1;
end
他の例1
- スキーの動画です。この骨格の角度などで、スキーの上手さなどの評価につながるかもしれません
- リフトから降りて滑りだすところもうまく検出できていて、その角度の変化なども定量化するとおもしろそうです

動画出展:pixabay (チェアリフト スキー スキー場 冬のスポーツ 自然)
他の例2
- バッティングセンターで珍しく、うまく打てた時の動画です
- ただ何となく、身体が上に伸びあがっている気がします。腰の位置が画像でいう上にずれていて、目線がブレてるんでしょうか?ただ私は、部活動をやっていたのにもかかわらず、そのあたりが、あまりよくわかりません。
- 腰の位置や他の骨格の位置を経時的に捉えて、上手な人と比較してみたいですね。

感想
- シンプルな手法でしたが、自前のデータにもうまく当てはめられ非常に良好な結果を得ることができました
- 確かにこのシンプルな手法だと、第三者が改良を加えるのも比較的可能そうです。そのときにすでにこの手法では良い結果が得られているので、「こうしたらいいのでは?」といった第三者のアレンジで、このモデルより精度が高まれば、他の手法と比べても自然と競争力のあるものになっているものと思います。その観点でも、このモデルを出発点して改良したり、また大きく方針のちがうモデルを作った場合でもこのシンプルなモデルと性能を比べることで、姿勢推定の結果の良しあしがクリアになりそうです。
- 以上の内容は一部私の勘違いがあるかもしれませんが、私の理解した限りでは、非常に有効で勉強しがいのある内容でした。実際の訓練の方法などは紹介できませんでしたが、気になる方はこの手法をMATLAB実装したもとのページなどを見てもらえればと思います。
参考文献
[2] In the wildの和訳に際し参考にした:Wang, K. and Belongie, S., 2010, September. Word spotting in the wild. In European conference on computer vision (pp. 591-604). Springer, Berlin, Heidelberg.
[3] 山下隆義「イラストで学ぶ ディープラーニング 改訂第2版 」(姿勢推定のセクションにて勉強しました。非常にわかりやすかったです。)
Explainable AI:LIMEを用いた判断根拠の可視化
こちらの記事は、MATLAB/Simulink Advent Calendar 2021の8日目の記事として書かれたものです。
また、7日目も記事を投稿していて、もしよろしければこちらもご覧いただけると幸いです。
はじめに
この記事では、LIMEとよばれる手法を用いて、畳み込みニューラルネットワーク(CNN)によって画像分類を行ったときの判断根拠の可視化(どのような部分を見て、その分類結果に至ったのか)を行います。画像に対して適用するときの仕組みをここでは説明したいと思います。この画像をもととなる論文はこちらになります: LIME (Local Interpretable Model-agnostic Explanations) 。 また、こちらからも入手することができます。これをMATLAB実装した2020年夏ごろは、公開されている唯一のMATLAB実装だった(と思う)のですが、2020年秋バージョンからimageLimeという関数が、MATLABで公式実装され、1行で実行できるようになりました。ご自身の研究などで使う際は、こちらの公式の実装を使い、そして、その内容を確認したい場合には以下のリポジトリを利用すると良いかもしれません。
(注意)こちらの記事は、チェックはしておりますが、理解違いやミスがあるかもしれません。予めご了承ください。
この記事のコードやデータはこちらのページからダウンロードすることができます
LIMEについて
例えば、下の犬の画像を例とすると、CNNによって犬であると分類した際に、どのような箇所に注目してこの分類結果に至ったかということを示しています。赤っぽい色の方が影響が強いことを示しています。LIMEは、画像データだけでなく、表形式のデータなど、ほかのデータ形式に関しても利用可能です。ここでは、画像データを対象として、実装していきます。

LIMEについて:もととなる論文のイントロダクションの和訳
こちらの手法については、もととなっているRibeiroら (2016)の論文のイントロダクションの部分を読むのが良いと思います。以下に、和訳を掲載します。一部、筆者の解釈による意訳を含みます。
機械学習は、近年の科学技術の進歩の中核をなすものであるが、この分野では人間の役割の重要性が見落とされがちである。人間が機械学習の分類器をツールとして直接使用する場合でも、ある製品にモデルを導入する場合でも、信頼性という重要な問題が残っている。信頼の定義として、2つの異なる(しかし関連する)定義について、区別して考えることが重要である。(1) 予測の信頼、すなわちユーザーが個々の予測を十分に信頼し、それに基づいて何らかの行動を取るかどうか、(2) モデルの信頼、すなわちユーザーがモデルを実装した場合に、「そのモデルが合理的な道筋をもって行動する」、と信頼するかどうか、である。どちらにおいても、そのモデルを信頼するかどうかは、ユーザー(人)がそのモデルをブラックボックスとして見るのではなく、人間がモデルの動作をどれだけ理解しているかに直接影響される。モデルが何らかの意思決定に使用される場合、個々の予測に対する信頼性について判断することは重要である。例えば、機械学習を医療診断[6]やテロの検知に使用する場合、十分な根拠なしに機械学習モデルを信頼すると、重大な過失を招く恐れがある。個々の予測を信頼することとは別に、モデルを実世界に実装し役立てようとする前に、その機械学習モデルそのものを評価する必要がある。この判断を下すためには、そのモデルが実世界のデータ上で、ただしい評価基準に従って良好な結果を示すものであると、ユーザーが確信する必要があります。現在、そのようなモデルの評価は、利用可能な検証データセットを用いて予測し、いくつかの評価指標を用いて行われています。しかし、実世界のデータはそれらの利用可能なデータセットとは大きく異なることが多く、またさらに、その評価指標が製品の目標を適切に反映しない場合もあります。このような評価指標を最適なものにすることに加えて、個々のデータに対する、その予測値とその判断基準を精査することは、それらの問題の解決策となりえる。この場合、特に大規模なデータセットでは、どのデータを検査すべきかを提案し、ユーザーを支援することが重要である。本論文では、予測の信頼性の問題に対する解決策として、個々の予測に対する説明性を提供する方法を提案し、さらに、モデル自体の信頼性の問題に対する解決策として、そのようにデータセットを予測(および説明)したときの、重要なデータを選択可能にする方法を提案する。我々の主な貢献は以下のようにまとめられる。
- LIME、解釈可能なモデルで対象とする機械学習モデルを局所的に近似することで、任意の分類モデルや回帰モデルの予測の根拠を忠実に説明することができるアルゴリズム。
- SP-LIMEは、モデルの信頼性の問題に対処するために、説明性を持つ、いくつかの代表的なインスタンス(データ)を、劣モジュラ最適化によって選択する手法である。
- シミュレーションおよび人間による、総合的な評価で、その説明がモデルの信頼性にどのような影響を及ぼすか検証する。我々の実験では、LIMEを使用した非専門家に、どちらの分類器が実世界でよりよく汎用的に有効利用できるかを選んでもらう。さらに、LIMEを使って特徴量の調整を行うことで、20のニュースグループで訓練された信頼性の低いモデルを大幅に改良することができた。また、画像を対象としたニューラルネットワークの予測を理解することで、その分類モデルを信用すべきでない場合やその理由を実務者が知ることができる、ということを示した。
確かに、手元のデータセットでは高い精度が出ても、それの判断根拠がわからないと、その信頼性を検証するのは難しいですし、そのモデルをよりよいものに改良する際にもどのようなデータを加えたらよいかなどは判断が難しいですね。
大まかな流れ
今回は、大まかな流れを説明することに重きを置いているので、ほかの言語を使ってる方や、プログラミングは行わない方も見ていただけますと幸いです。
step1: 画像のロード
step2: 学習済み深層学習ネットワークのインポート
step3: スーパーピクセルの作成
step4: ランダムにスーパーピクセルの情報をゼロし、もとの画像との距離を計算する
step5: CNNにてテスト画像を推論し、猫の確率を取り出す
step6: 線形モデルでフィッティングを行う
step7:結果の可視化
具体例をもとにLIMEを説明
step1: 画像のロード
今回は、この猫の画像を用いて、分類とその判断根拠の可視化を行います。
I=imread('img.png'); %画像の読み込み
figure;imshow(I);title('target image') % 表示

step2: 学習済み深層学習ネットワークのインポート
ここでは、ImageNetという大規模な画像のデータセットであらかじめ訓練し、高い分類性を持つネットワークをインポートします。もちろん、自分で訓練したモデルでも適用可能です。Heら (2016)のResNetをここでは使います。
net=resnet18; % Importing pre-trained network, ResNet-18
分類を行って、catという分類結果になっていることを確認します。
Ypred=classify(net,imresize(I,[224 224])) % Classify the image and confirm if the result is correct.
Ypred =
Egyptian cat
ImageNetは1000クラスのカテゴリで訓練されていて、いまのEgyptian catのインデックス(カテゴリ番号のようなもの)を取り出します。
classIdx=find(net.Layers(71, 1).Classes==Ypred); % Extract the index corresponding to the classification result.
step3: スーパーピクセルの作成
画像のピクセルをスーパーピクセルと呼ばれる、類似した色情報を持つピクセルのまとまりに変換します。スーパーピクセルへの変換方法やそのパラメータは多く存在しますが、いまはデフォルトの設定で行っていきます。デフォルトではSimple Linear Iterative Clustering (SLIC) アルゴリズムを用います。パラメータとしては、例えば、いくつのスーパーピクセルに分解するか、などが含まれます。
numSuperPixel=75; % スーパーピクセルの数を75として設定 [L,N] = superpixels(I,numSuperPixel); % スーパーピクセルの計算
スーパーピクセルの境界を色付けし、スーパーピクセルを可視化します。
BW = boundarymask(L); figure;imshow(imoverlay(I,BW,'cyan'),'InitialMagnification',100)

このように、画像がそれぞれのまとまりに分解されました。
step4: ランダムにスーパーピクセルの情報をゼロし、もとの画像との距離を計算する
以下に示されるように、pertubated imageと呼ばれる、画像の一部の情報を欠損させたものを作成します。スーパーピクセルが75個あるとすると、ランダムに黒に変換します。この例ではランダムに約20%の確率で黒に変換しています。また、同時に、distance_ImPair(距離)を計算していて、それはもとの画像と黒に変換した下の犬の画像がどれだけ変化しているかを計算します。この例では、黒以外のピクセルの数ともとの画像の画像数の比で距離を計算しています。コサイン類似度などで計算するのがより良いと思います。

作成するPertubated imageの数を設定します。多くの枚数を生成した方が信頼度は高まりますが、それと同時に計算時間が長くなります。
sampleNum=1000;
% calculate similarity with the original image
distance_ImPair=zeros(sampleNum,1);
indices=zeros(sampleNum,N);
img=zeros(224,224,3,sampleNum);
for i=1:sampleNum
% randomly black-out the superpixels
ind=rand(N,1)>0.2;
map=zeros(size(I,1:2));
for j=[find(ind==1)]'
ROI=L==j;
map=ROI+map;
end
img(:,:,:,i)=imresize(I.*uint8(map),[224 224]);
% calculate the similarity
% other metrics for calculating similarity are also fine
% this calculation also affetcts to the result
distance_ImPair(i)=1-nnz(ind)./N; % 距離の計算。ゼロが黒でマスクをされているところ。
% つまり、2つ目の項はゼロでない(元の状態で残っている)件数の割合。1-nnz(ind)/Nは、同じ画像の場合、0になる
indices(i,:)=ind;
end
step5: CNNにてテスト画像を推論し、猫の確率を取り出す
MATLABでは、 activations関数を用いて、特定の層までの推論を行うことができます。
さきほどの部分的に黒で塗りつぶされた箇所に対してCNNで推論を行います。ここでのアイデアとしては、
•それぞれの加工された画像に対して猫のクラスのスコアを確認するが、場合によってはそのスコア(猫である確率)が大きく下がる場合とそうでないときがあるはず
•正解のスコアが下がる→CNNにとって重要な場所が隠された、と考えます
prob=activations(net,uint8(img),'prob','OutputAs','rows'); score=prob(:,classIdx);
step6: 線形モデルでフィッティングを行う
下の4つに区切られた画像は、入力画像を非常に粗く4分割した場合であると考えます。それぞれの箇所を1~4と命名しています。先述したように、この分割の数もユーザーの決めるパラメータになります。

そして、以下のように、1だけが保持されて、2~4はすべて黒で隠されてしまったとします。

ここでは、1枚だけではなく、複数のpertubated imageが生成されますが、以下の3つのサンプルが生成されたとします。下の表の見方としては、スーパーピクセルのIDというのが上の1~4の各領域を表し、1か0かというのは、その領域が残っているかということを示します。例えば、一番上の段は、1だけ残った画像を意味していて、ちょうど上の画像に対応しています。同様に、2段目のサンプルに関しては、2と3のみが保持されて、1と4の領域は黒で隠されてしまったとします。「Catのスコア」に関してですが、ここはその一部の画像部分が隠された状態で、CNNで推論をしたときのCatの確率を示します。通常のCNNでは、学習したカテゴリの中で(例:1000クラス)、最も高いスコアを持つクラスを推論の結果としますが、ここでは、一部の領域が隠れているのでもしかしたら、推論結果は猫ではなくなってしまうかもしれません。しかし、ここでは、猫のスコアが、マスクで隠されたあと/前でどう変わるかということに注目するため、猫のスコアを見る必要があります。
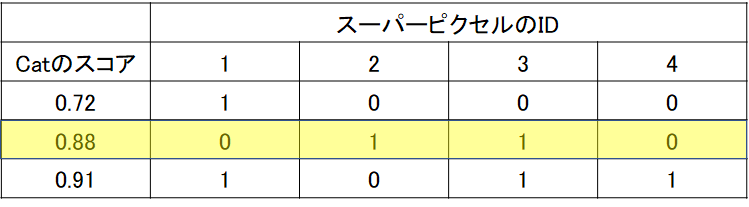
ここで、(猫のスコア)=a1×(スーパーピクセルの1の箇所が残っているか)+ a2×(スーパーピクセルの2の箇所が残っているか)...+ a4×(スーパーピクセルの4の箇所が残っているか)というような要領でフィッティングを行います。例えば、スーパーピクセルのIDが1の位置が重要であったとすると、その箇所が保持されている(=黒になっていないとき)、スコアは高くなるはずです。つまり、高い方に寄与する入力なので、その係数は大きくなるはずです。今回は線形フィッティングを行っていますが、決定木などのアルゴリズムでも可能です。
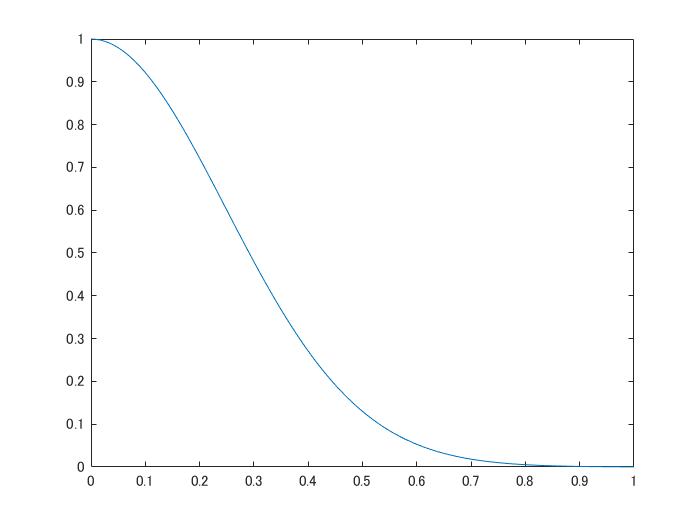
さらに、ここでは、もとの画像とpertubated image(一部が黒く塗りつぶされた画像)の違い(距離)をもとに、フィッティングの重みづけをします。具体的には、以下のような、カーネル関数によって距離から類似度に変換します。例えば、もとの画像とは大きく異なる真っ黒な画像を推論しても、この類似度によって、重視されないような形でフィッティングされますが、ここでは約20%が黒くなるよう設定しているのであまり結果の図に大きな影響はないかもしれません。
sigma=.35;
weights=exp(-distance_ImPair.^2/(sigma.^2));
mdl=fitrlinear(indices,score,'Learner','leastsquares','Weights',weights);
x=[0:0.01:1];
y=(exp(-x.^2/(sigma.^2)));% Confirm the exponential kernel used for the weighting.
figure;plot(x,y);xlabel('distance');ylabel('weight')
step7:結果の可視化
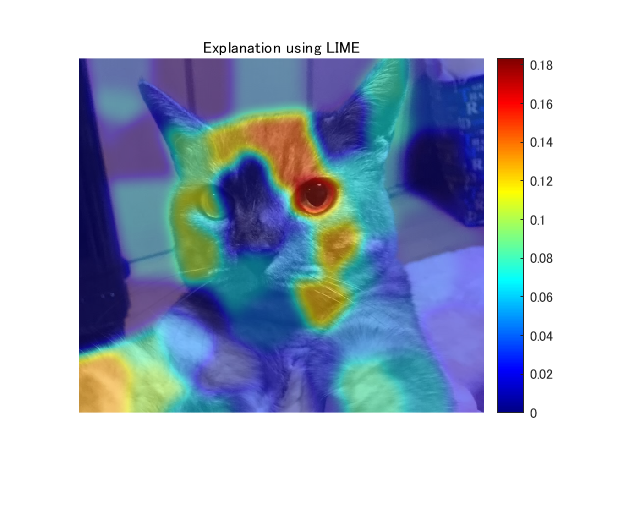
上で求めた線形モデルの係数をもとに重要度を可視化します。ここでは、正の係数のみを用います。以下の論文中の記述からそのように判断しました。
just highlight the super-pixels with positive weight towards a specific class
また、ガウシアンフィルタで平滑化したうえで出力します。このあたりは、オリジナルの実装と異なっております。
result=zeros(size(L));
for i=1:N
ROI=L==i;
result=result+ROI.*max(mdl.Beta(i),0);% calculate the contribution if the weight is non-zero
end
% smoothing the LIME result. this is not included in the official
% implementation
result2=imgaussfilt(result,8);
% display the final result
figure;imshow(I);hold on
imagesc(result2,'AlphaData',0.5);
colormap jet;colorbar;hold off;
title("Explanation using LIME");
論文中の例
LIMEを画像に適用したときに、論文ではどのような記述がされているか確認したいと思います。
以下に、3.6の和訳を掲載します。一部、筆者の解釈による意訳を含みます。
ここでは、Googleにより提案された事前学習済みのInceptionネットワーク[25]の任意の画像(図4a)に対する予測について、LIMEを用いて解釈します。図4b、図4c、図4dは、K=10とした場合に、予測された上位3クラスについて、重要視されたスーパーピクセルを示しています(画像の残りの部分はグレーアウトされています)。図4bは、アコースティックギターがエレクトリックギターであると予測された理由を示しています。このようなLIMEによる説明は、たとえ予測されたクラスが間違っていたとしても、分類器が意図せぬ挙動を示していないということを表し、分類器の信頼性を高める。

画像出典:Ribeiroら (2016)のFigure4より引用
ここでは、ギターを弾いている人間の頭を犬にして、予測の難しい(できない)画像を入力しています。それのCNNによる予測結果は、電子ギター、アコースティックギター、ラブラドール(スコアの高い上位3つ)となりました。それぞれの予測に対して、どのような箇所が重視されているかをみると、確かに、はじめのギターの方は、ギターの部分が可視化されていますし、ラブラドールと予測した場合は、正しくラブラドールの部分が可視化されています。
モデルの依存性について
LIMEとは、Local Interpretable Model-agnostic Explanationsのことでした。判断根拠の可視化における、Model-agnosticについて簡単に触れていきたいと思います。
モデル依存型 (model-specific)
モデル依存型とは、その説明手法が特定のモデルにしか使えないことです。例えば、CNNの分類のときの判断根拠の可視化の有名な手法として、CAMと呼ばれるものがあります (Zhou et al., 2016)。しかし、これはglobal average pooling層を用いて判断根拠の可視化を行っていて、その層を持たないCNNではその判断根拠の可視化の手法を直接使うことはできません。このように、このようにモデル依存型のXAIでは適用できるAIモデルやアルゴリズムが限定されるものの、対象とするAIモデルの構造を十分に活用した説明を出力できる強みがあります(大坪直樹; 中江俊博. XAI(説明可能なAI))。
モデル非依存型(model-agnostic)
こちらは、モデルの種類に依存しないもので、今回のLIMEはこちらにあたります。モデル依存型のような、そのモデルの構造の解析などは行わず、対象のモデルをブラックボックスと捉え、データの入力とその出力に関係を見出します。今回のLIMEのようにいかなるモデルにも適用可能なので守備範囲が広いというメリットがあります。
まとめ
今回は、LIMEによる判断根拠の可視化をMATLABによる実装をもとに説明を試みました。冒頭でも述べましたが、少し実装や理解が間違っているところがあるかもしれないので、もし何かございましたら教えていただけますと幸いです。
今後やってみたいこと
- 今回は画像をもとに説明しましたが、表のデータなどあらゆる形式のデータに対して適用可能なので、ほかのデータ形式に対しても試したいなと思います。
- 他の可視化手法も試してみたいと思います。
疑問に思ったこと
- 今回は猫の耳など、はっきりとした形状が根拠になりやすいのでわかりやすかったですが、画像の局所的なところ(スーパーピクセルで分けたパート)ではなく、画像全体をみて、ぼんやりと判断するような場合にはうまく適用できるのかな?と疑問に思いました。
- (これは私の実装がまずいのかもしれませんが)パラメータによって最終的なヒートマップが変わることが少し気になります。線形モデルでのフィッティングも決定木 / y=ax+by+...のようなシンプルな回帰式など他にも選択肢がありそうですし、pertubated imageの数やその他もろもろのパラメータの値をどのような値がよいのかはわかりませんでした。
感想
- 特に最後に引用したFigure4では直感的に非常に納得のいく説明がされていて、とても面白いと思いました。
- 判断根拠の可視化(画像を対象)の場合は、このほかにも多くの手法が存在するので、それらを比較しながらそのタスクに沿った最適な判断根拠の可視化手法を選択していければ、より信頼性のあるAIの利活用につながり、よいのではないかと思いました
参考文献・サイト
[1] Ribeiro, M.T., Singh, S. and Guestrin, C., 2016, August. " Why should I trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
[2] He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[3] Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Susstrunk, SLIC Superpixels Compared to State-of-the-art Superpixel Methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, Volume 34, Issue 11, pp. 2274-2282, May 2012
[4] A Review of Different Interpretation Methods (Part 1: Saliency Map, CAM, Grad-CAM)
[5] Interpretable Machine Learning with LIME for Image Classification
[6] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. and Torralba, A., 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2921-2929).
Spatial CNNを用いた車線検出
この記事は、MATLAB/Simulink Advent Calendar 2021の7日目の記事として書かれています。
また、8日目も記事を投稿していて、もしよろしければこちらもご覧いただけると幸いです。 kentapt.hatenablog.com
また、ここで用いるコードなどはこちらからダウンロード可能です。 もし、本記事に誤りや誤字が含まれていれば、教えていただけますと幸いです。
はじめに
Spatial CNNとよばれる手法を用いて、運転動画から車線検出を行います。ここで得られる結果の例を以下に示します。自分のいるレーンの車線とその横の車線の合計4つの線が検出されています。こちらは車載カメラからの動画を入力とし、深層学習ネットワークを用いて車線の検出を行っています。赤や青で自動的に車線を認識できていることがわかると思います。本記事では、Spatial CNNと呼ばれる方法で、動画から自動的に車線を検出する方法について説明します。

動画出展:Spatial CNNをテストするために、映像素材さまの「車載動画 4K 夕方の東京スカイツリー【無料フリー動画素材】/japan free video」より、使わせていただきました。ありがとうございました。
コード
こちらにある、spatial CNNのMATLAB実装のコードを用いて行います。作成者のricheek-MWさまに感謝いたします。githubからダウンロードとし、ZIPファイルを解凍するか、gitbashでgit cloneコマンドを用いるなどして、ダウンロードしてください。
Spatial CNNについて:もととなる論文 のイントロダクションの和訳
こちらの手法については、もととなっているPanら (2018)の論文のイントロダクションの部分を読むのが良いと思います。以下に、和訳を掲載します。一部、筆者の解釈による意訳を含みます。
近年、自動車の自律走行は学術界や産業界で大きな注目を集めている。その自律走行における最も困難な課題の一つは、その場の交通状況の理解であり、例えば、自動的に周辺環境を理解するために、画像を用いて車線を検出したり、セマンティックセグメンテーションなどが行われてきた。車線の検出は、車線変更など車両を自動的に移動させる際に役立ち、運転支援システムに利用される可能性がある (Urmson et al. 2008)。一方、セマンティックセグメンテーションは、車両や歩行者などの周囲の物体について、より詳細な位置情報を理解するのに役立つ。しかし、実際のアプリケーションでは、悪天候、薄暗がり、まぶしい光など、多くの厳しい状況があることを考慮すると、これらのタスクは非常に困難である。交通シーンの理解におけるもう一つの課題は、特に車線検出では、検出する物体の構造はあらかじめわかっている場合が多いが(車線は直線である・ポールは鉛直方向にまっすぐ伸びているなど)、実際に取得した画像中では、長い連続した直線や曲線の部分が一部途切れていたり、隠れて一部が見えなくなってしまっているようなケースが多い。例えば、図1(a)の最も上の例では、右側の車が右端の車線標識を完全に隠してしまっている。畳み込みニューラルネットワーク(CNN)ベースの手法(Krizhevsky, Sutskever, and Hinton 2012; Long, Shelhamer, and Darrell 2015)は、強力な画像の認識能力により、その画像中のシーンの理解を一気にレベルアップさせたが、図1の赤いバウンディングボックスに表示されている車線標識や電柱(その物体の領域が長く、一部が隠れてしまっているような物体)のような物体に対する性能はまだ十分でない。
このように画像認識の方法で行う上では困難である一方で、人間は簡単にその位置を推測し、見えない部分をその前後関係から埋めることができる。そこで、本論文では、深層畳み込みニューラルネットワークをより高度に空間の認識ができるよう、一般化したSpatial CNN(SCNN)を提案する。「レイヤー・バイ・レイヤー」と呼ばれるようなCNNでは、畳み込み層が前の層からの入力を受け取り、畳み込み演算と非線形活性化を適用し、その結果を次のレイヤーに伝達する。そしてこのようなプロセスを繰り返し行う。同様に、本研究で提案する、SCNNでは、特徴マップの行(または列)を1つのレイヤーと見なし、畳み込み演算、非線形活性化演算、和演算を順次適用することで、ディープニューラルネットワークを形成する(おそらく、それぞれの特徴マップごとに独立して畳み込み演算をし、次の層でも、同様の操作を繰り返す、という意味だと思います。N番目の特徴マップが畳み込み演算などを経て、またその結果に対して、同様の畳み込み演算などを行っていくイメージです)。このようにして、同じ層のニューロン間で情報が伝播していくことができる。これは、車線、電柱、隠れた部分のあるトラックなどの構造化された物体に対して、それぞれの層の間で、その演算結果を伝えることができるため、そのネットワークで抽出した空間情報を強化することができ、特に有効である。図1に示すように、従来のCNNによる車線検出の結果が不連続であったり、乱雑であったりする場合でも、SCNNは車線標識や電柱を滑らかさや連続性をよく保ったうえで認識することができている。我々の実験では、SCNNは他のRNNやMRF/CRFベースの手法を大幅に上回り、さらに、より深いResNet-101(He et al. 2016)よりも良い結果を得た。
コードの実行
spatialCNNLaneDetectionVideoExample.mを実行すればskyTree.mp4に対して、車線検出が行われ、結果が保存されます。実行にあたっては、もとのgithubページも参照していただければと思います。実行にあたっては、F5ボタンや、実行の緑の三角形のボタンを押せば実行します。
内容について:論文の和訳で確認
ここでは、もととなる論文のExperimentの欄のLane Detectionを一部和訳し、本手法の内容を確認します。こちらも、筆者による、勝手な解釈を多く含んだうえで訳しているため、あらかじめご注意ください。
一般的な物体検出ではバウンディングボックスが出力として必要である一方、車線検出では 曲線を正確に予測する必要がある。考えつくアイデアとして、深層学習ネットワークに車線の確率マップを出力させる、というものがあげられる。これはちょうど、セマンティックセグメンテーションタスクと似ていて、各ピクセルの出力を目的としてネットワークを学習させるものである。(筆者追加:セマンティックセグメンテーションでは、各ピクセルに対して、その分類の確率を与え(例:背景 0.4、水 0.1、植物 0.5)、その最も高いものをそのピクセルの分類とする。)しかし、異なる車線を1つのクラスとみなし、後処理として、それらを各車線に分離するのではなく、本手法では、 異なる車線をそれぞれ別のクラスとして認識させるような深層学習ネットワークを構築することを目指す。
深層学習ネットワークに、異なる車線を識別させることで、よりロバストな結果が得られる。そこでは、これらの4つの車線を異なるクラスとみなし、さらに、これとは別の層の浅いネットワークを用いて、その車線自体が存在するかを判定する。(筆者追加:1~4本目の車線の位置を予想するネットワーク+その車線の予測自体が正しいかどうかを判断するネットワーク)また、テストの際には、確率マップから、車線という曲線に変換する必要がある。図5(b)に示すように、信頼度が0.5より大きい各車線に対して、20点の車線に対応する点を抽出する。そして、その20個の点に対して、3次スプライン曲線をフィッティングさせ、そのフィッティング結果をもとに曲線を生成し、最終的な予測値とする。
内容について:コードをもとに確認
具体的に、このネットワークの中身について簡単に触れていこうと思います。まず、MATLAB内のアプリである、deepNetworkDesignerでSpatial CNNの構造を可視化してみます。そうすると、以下のように、2つのアウトプットがあることがわかります。
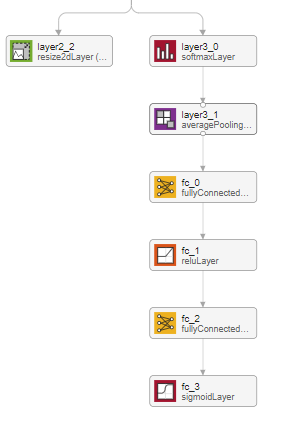
左側の、layer2_2と書かれている層について
こちらは、このネットワークで検出可能な4つの車線+背景の合計5つのカテゴリーに対し、それぞれのカテゴリーの確率を示すヒートマップのようなものを出力しています。わかりやすくするために、以下にコードを用いて説明します。

clear;clc;close all
addpath('src'); % Add path to the source directory
model = helper.downloadSCNNLaneDetection; % Download Pre-trained Network
net = model.net; % import pre-trained Spatial CNN
params = helper.createSCNNDetectionParameters; % Specify Detection Parameters
executionEnvironment = "auto"; % Specify the executionEnvironmen
path = fullfile("images","testImage.jpg"); % Read the test image.
image = imread(path); % read the test image
[detections, laneMask, confidence] = detectLaneMarkings_modified(net, image, params, executionEnvironment);% Call detectLaneMarkings to detect the lane markings.
ここで、detectLaneMarkings_modifiedという、関数を私の方で作成(もとのコードを一部変更)し、srcフォルダ内に格納しています。addpath関数で、srcフォルダーも見えるようになっているので、現在のディレクトリにその関数は存在しませんが実行することができます。
ネットワークの出力の1つである、layer2_2の中身を見ていきます。上のコードでは、imagesフォルダー内のtestImage.jpgに対して、Spatial CNNを適用しています(推論)。

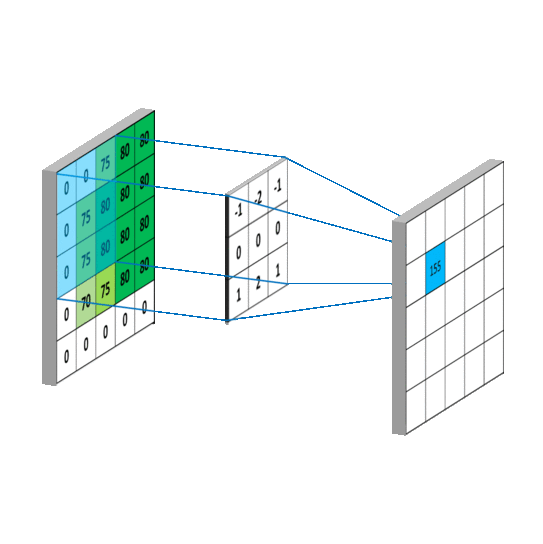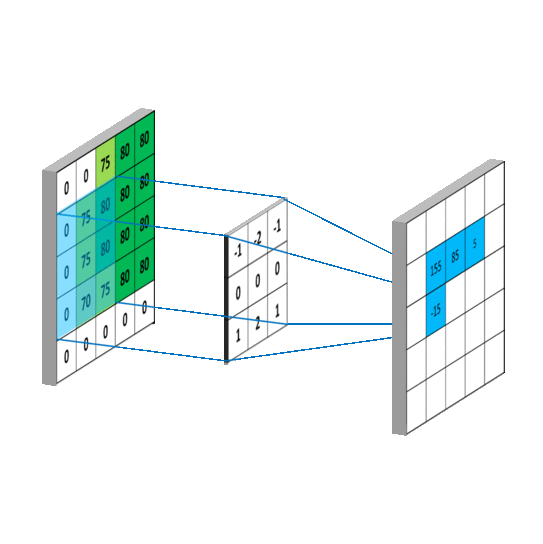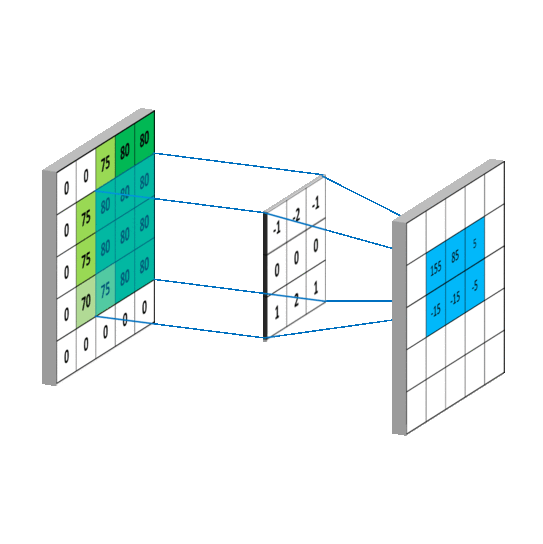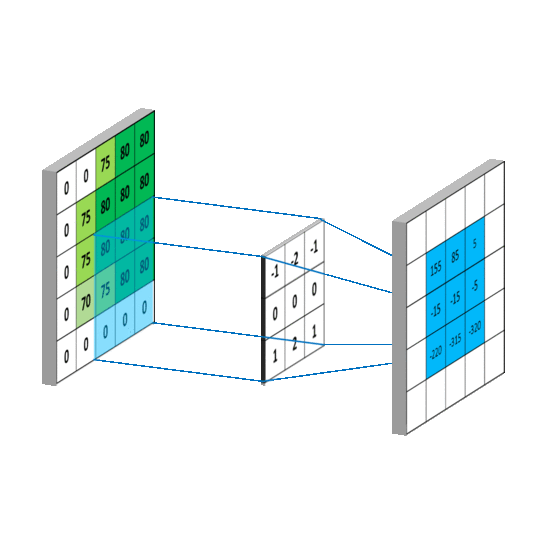{kind=link}
実際にワークスペースを見てみるとlaneMaskとよばれる変数があって、これがlayer2_2の出力に相当します。これがどのような絵になっているか見てみます。montage関数を用いて可視化をしようと思います。
% 簡単にするために、FORを使ってCell配列を作ります
labeMask_C=cell(1,5);
for i=1:5
mask_i=laneMask(:,:,i);
labeMask_C{i}=label2rgb(round(mask_i)+1);
end
figure;montage(labeMask_C);colorbar

このように、5つの画像として、layer2_2の出力結果を可視化することができました。こちらは、背景+検出可能な自車の左右2つの線の合計4本の線の確率マップになっています。水色に近い方が高い確率を示しています。つまり、左側の最も上にある画像では、背景(つまり車線でない)ピクセルが水色で示されていて、そのほかの画像の水色の部分も確かに車線のような形状になっていることがわかります。
それでは、このテスト画像に対して、どのような車線を出力するか確認してみます。
fig = figure; helper.plotLanes(fig, image, detections);

fc_3の出力について
確かに、右上に伸びる2つの車線(赤と緑)および、左上に伸びる車線(青)を確認することができます。しかし、このネットワークでは4本の車線を検出するはずですが、3つしかないのはなぜでしょうか。それでは、confidenceという変数をみてみます。
confidence
confidence = 4x1 の single 列ベクトル
1
1
1
0
すると、1, 1, 1, 0という確信度を得ることができます。これは何かというと、各車線を推定したときのその確信度です。4本目の車線に関しては、確信度が低く、出力されなかったため、今回のテスト画像に関しては3本しか車線が検出されませんでした。なお、今回のコードでは、閾値を0.5とし、それ以下のものは0に、そしてそれ以上のconfidence scoreは1に丸められているため、このように1/0で結果が示されています。
ネットワークの概略
ここまでの流れを簡単にまとめると、画像の入力があって、それらに畳み込み演算などを適用します。そして、2つの出力を得ます。1つ目は、背景や車線の確率マップ、そして、2つ目はそれぞれの確信度を示しています。ちょうど以下の図のようになります。下の段の8×Resizeというのは、出力のbicubic補間によって、縦及び横幅を8倍に拡大しています。また、最終的な車線に関しては、fitPolynomialRANSAC関数を用いて、フィッティングをして出力しています。次数は2次になっていますが、1次の式でフィッティングすることも可能です。ここは、オリジナルの実装と少し異なっていそうです。

{kind=link}
Message Passing Layerについて
このSpatial CNNの特徴として、Message Passing Layerと呼ばれるものが存在します。これをまずはdeepNetworkDesignerをもちいて確認してみましょう。まずは、modelをlaerGraph変数にdeepNetworkDesignerとタイプして、モデルの可視化を行います。
lGraph=layerGraph(model.net);
すると、modelの中に、message passing layerなるものが含まれていることがわかります。
さらに、解析ボタンを押す、または、analyzeNetwork(lGlaph)として、ネットワークの解析を行います。

ここの、層では、従来のCNNのような、直前の層で得られた演算結果(特徴マップ)全体に対して、畳み込み演算を行うのではなく、各層ごとに独立して畳み込み演算を行います。これによって、長い直線状の画像特徴をうまく捉えることができるようです。実際、出力(アクティベーション)は36×100×128と、出力サイズ自体は変わっていないことがわかります。
up_downなど、方向に関する違いがあります。ここでは、上から下か(または下から上か)、および、左から右か(または右から左か)という合計4パターンが試されていて、4つの層が用意されています。これは畳み込み演算を行うときの方向です。
このような独自のレイヤーに関しては、カスタム定義層として、.mファイルで定義することができます。scr => +layer => MessagePassingLayer.mにファイルが保存されていて、例えば、rightLeftの場合は以下のようにフィルターが移動することがわかります。i = size(block,sliceDim)-1:-1:1というように、値が下がるようになっていて、その値が2つ目の入力(左右方向)に影響しています。このように確かに右から左に動くように設計されていることがわかります。
function block = rightLeft(net,block)
% Slice along the width.
sliceDim = 2;
for i = size(block,sliceDim)-1:-1:1
z = predict(net,block(:,i+1,:,:));
block(:,i,:,:) = block(:,i,:,:) + z;
end
end
その他のテスト動画について
他の動画ファイル(example2.mp4)に関して、推論を行ったときの結果を示します。ここでは、自転車の下側の車線もうまく描けていることがわかります。また、車線を誤って変更したようなイレギュラーな状況でもうまく推論できています。また、黄色い車線に関しては、最後のほうでは推論できていないことがわかります。このモデルの訓練データのCULaneデータセットでは、黄色い車線のようなデータが少なかったことが理由かもしれません。冒頭の夕暮れのデータやこのような晴れのデータでも安定して車線の検出ができていて、素晴らしいモデルだと思いました。例えば、二値化やハフ変換のような従来の方法ではこのような環境の変化に関してはパラメータ調整が必要で、難しい場合が多い一方、このような光環境が変化したり、道路の線がかすれているような状況でも利用可能であるので、さまざまなシーンで広く利用できそうです。

まとめ
この記事では、richeek-MWさんがMATLAB実装したファイルをもとに、Pan et al. (2018)のSpatial CNNを試してみました。自前のデータでもパラメータを変更することもなく、良好な結果を得ることができました。今回の例では自動車の自律走行の支援のための例になっていますが、他の分野でも直線、または曲線を精度よく検出することは多くの場面で重要だと思います。今回は4本の線の抽出ですが、本数を変えたり、最終的な線のフィッティングの方法を変えるなどして、より多用な出力が生み出せるかもしれません。
参考文献
Pan, X., Shi, J., Luo, P., Wang, X. and Tang, X., 2018, April. Spatial as deep: Spatial cnn for traffic scene understanding. In Thirty-Second AAAI Conference on Artificial Intelligence.
MATLAB Mobile(無料枠)とPythonライブラリ folium によるGPSデータのプロット
このぺージではMATLAB Mobileの無料枠の機能を利用して、MATLAB Mobileをiphoneにインストールして、それを持って移動したときのGPSによる位置情報を地図上にプロットするということを行います。地図へのプロットはpythonやpythonライブラリのfolium等を用いて行います。移動中のスマートフォンのGPSデータを一定時間ごとに保存し、その軌跡を地図上にマッピングすることを行います。今回は都内を自動車で移動したときのGPS情報を描き、さらに23区の人口を色のグラデーションで示してみます。 このページのコードや私の作成したデータに関しては、こちらから入手することができます。また、pythonコードの部分は、こちらのnbviewerでも閲覧可能です。
最終出力のイメージ

この記事について
特に人口の情報をグラデーションで示す意味はないのですが、キレイな図になったのでその機能を使った履歴も残そうと思います。 今後の自分用のまとめとして作成したものをここで公開させていただきます。Foliumをもちいたプロットに関しては、末尾の参考文献がわかりやすく、それらを見ながら進めるとよいのですが、ところどころエラーが出るところもあり、その対処の自分用の備忘録としたいと思います。GPSデータの取得やコーディングに関してもまだまだ改善の余地があり、何かございましたら教えていただけますと幸いです。この記事のデータに関しては、iphone8を用いて位置情報を取得しており、Pythonの実行のために、Windows10を利用しています。
MATLAB Mobileについて
プログラミング言語のひとつであるMATLABは有料ですが、MATLAB Mobileというスマートフォンでも実行できるアプリも用意されており、アカウントを作成することで、無料でも一部の機能を使うことができます。詳しい内容についてはMatrixVectorScalarさまの「MATLAB 無償利用できる機能のまとめ」が非常に参考になりました。その中でも以下に示すようなスマートフォンのセンサーデータ(加速度、磁場、位置など)の取得機能が個人的におもしろく、何か遊んでみようと思いました。
例えばスマートフォンにダウンロードしたMATLAB Mobileを開いて以下のように操作するとセンサーを簡単に取得することができます。ここでは、加速度などの情報を取得しています。
 .
.
MATLAB Mobileによるセンサーデータの取得
簡単にMATLAB Mobileをつかってデータ取得する方法について記述します。取得したデータはMATLAB DriveというGoogle DriveやDropboxのようなストレージに保存されます。無料版では2021年9月の時点で250MB分を無料で保存できます。
- . ストリーム先をログにする(リアルタイムでクラウドには送信しない)
- . 取得の頻度を最小にするため、サンプルレートを0.5 Hzにする:今回は自動車で移動するため詳細な移動のログは必要ないため 3 位置情報をオンにする
- . 開始ボタンを押す
- . 計測が終われば停止する(今回は非常に短時間の計測を示す)
- . センサーログに赤字の1が見える:しばらく待つとクラウド(MATLAB Drive)に送信されたことがわかる
- . MATLAB Driveのフォルダ(Google DriveやDropboxのようなもの)にさきほど取得したデータが保存されていることがわかる

下図はMATLAB Driveに格納されているデータで、さきほど記録したデータがあることがわかります。

センサーデータをCSV形式で保存する
次に、さきほどのGPSのデータをcsv形式で保存をします。現在はMATLABで扱うことのできる mat形式 になっているため、その後のpythonの処理では直接的に扱うことはできません。そこで、以下のコードをコピーし、そのままMATLAB Mobileのコマンドウィンドウで実行してください。MobileSensorDataというフォルダの中にある、sensorlog_何々というデータをすべてCSV形式で保存します。
cd('/MATLAB Drive/MobileSensorData/')
info=dir('sensorlog_*');
numData=size(info,1);
names={info.name};
load(names{numData})
lat=Position.latitude;
lon=Position.longitude;
latlon=[lat,lon];
T = array2table(latlon);
T.Properties.VariableNames(1:2) = {'Latitude','Longitude'};
writetable(T,'latlon.csv')

次に、pythonでCSV形式に保存したGPSのデータを地図上にマッピングすることを行います。foliumやgeopandasというライブラリをインストールしてください。 また、niiyzさまが、こちらに東京のGEOJSONのファイルを用意してくださっているので、ダウンロードし、現在のディレクトリに保存しておいてください。
pythonコード
必要なライブラリのインポート
import folium import json import pandas as pd import numpy as np import geopandas as gpd import sys print(sys.version) print('folium version: 0.12.0') print(json.__version__) print(pd.__version__) print(np.__version__) print(gpd.__version__)
ベースマップの作成
GPSデータをプロットする前のベースとなるマップを用意します。folium.Mapを利用して作成することができます
m = folium.Map(location=[35.7056232, 139.751919], # 中心の設定:今回は東京ドーム tiles='cartodbpositron', # 地図のスタイルを設定 zoom_start = 12, # 初期ズーム率を設定 control_scale = True ) m # 作成したベースマップを表示
 jupyter notebookでは上のマップを表示するためにFile -> trust notebookをクリックしました
jupyter notebookでは上のマップを表示するためにFile -> trust notebookをクリックしました

23区の境界などを格納した情報を読み込み
読み込みに関しては、open(r'tokyo23.json) -> json.load(f)の流れで読み込めるらしいのですが、私の環境ではエラーが出てしまったため以下のように読み込みました。そして、私の環境では、データフレームに変換して後のグラデーションの表示(Choropleth図)がうまくいったので
データフレームに変換 -> column名の変更 という作業を行っています
tokyo23_df=gpd.read_file('tokyo23.json') tokyo23_df = tokyo23_df.rename(columns={'code': 'N03_007'}) tokyo23_df.head(23) #はじめの5行を表示
コードがN03_007というcolumnに入っていることを確認
strタイプになっていることがわかります。後半ではこのコードによって、その区と人口を紐づけます。
code=tokyo23_df['N03_007'].values print(code) code_0=code[0] print(type(code_0))
東京23区の市区町村コードとその区の名前のペアの読み込み
今回は練習のため、この後に東京23区の人口の情報を読み込み、それらもあわせて地図上にプロットします。その準備として、23区のコードを読み込みます。
code_name=pd.read_csv('code_name.csv', encoding="shift-jis") code_name.head(10)
東京23区の名前と人口のペアの読み込み
東京都HP(都内区市町村マップ)より作成した23区のそれぞれの人口のデータを読み込みます。
name_population=pd.read_csv('name_population.csv', encoding="shift-jis") name_population.head(10)
pd.mergeを用いて23区の名前を利用してデータフレームを横方向に結合
codenameとnamepopulationではnameのcolumnが共通しているので、その重複を利用して2つのデータフレームを結合することができます。23区の人口の場合は欠損値はありませんが、データ取得ができておらずNANになっている場合でも how=outer を利用して結合可能です。
merged_df=pd.merge(name_population, code_name, how='outer') merged_df.head(10) # 結合したデータフレームの値を確認
codeとpopulationのみを取り出したデータフレームを作成します
tokyo23_population_df=merged_df.loc[:,['code','population']]
結合したデータフレームの値を確認します
tokyo23_population_df.columns = ['N03_007','population'] tokyo23_population_df.head(10)
各区の人口の情報を読み込み
注意:ここではCSVファイルから読み込んだ区のコードは数値として読み込まれているので、
上のセルにあるような文字(str)配列に変更する必要があります
また、自前のデータで行う場合はpopulationに相当する値が文字列として数字が入っている場合は図の作成時にエラーが出てしまうため変換が必要です
tokyo23_population_df['N03_007'] = tokyo23_population_df['N03_007'].astype('str') tokyo23_population_df.head(10)
choropleth図の作成
folium.Choroplethという機能を使って作図していきます。以下のように設定を定義します。
folium.Choropleth(geo_data=tokyo23_df, # 地理情報のファイル name = 'choropleth_tokyo23', # 出力する地図プロットの名前 data = tokyo23_population_df, # 各区の人口データ columns=['N03_007', 'population'], # 各区の人口データのkey列とその値の列を指定 key_on='feature.properties.N03_007', # keyの情報:feature.properties.xxの形。N03_007の値を基に人口データと紐づける fill_opacity=0.41, # グラデーションであらわすときの色の濃さを指定 line_opacity=0.1, # 区の境界線の濃さを指定 line_color='blue', # 境界線の色を指定 fill_color='YlGn' # グラデーションのカラーマップを指定 ).add_to(m) folium.LayerControl().add_to(m) # ベースマップmにchoroplethの設定を追加 m

このように23区の人口の多さをグラデーションで示すことができました。次は前半のMATLAB Mobileによりスマートフォンから取得したGPSデータをプロットしていきます。
Matlab Onlineで作成したlatlon.csvの取り込み
locations = pd.read_csv("latlon.csv") # 読み込み numPlot=np.size(locations.Longitude) # データの個数を取得 locations.head(10) # 一部を表示
GPSのデータをラインで表示する
folium.vector_layers.PolyLineを用いてラインを書くことができます
line = folium.vector_layers.PolyLine(
locations=locations,
color='blue',
weight=3)
# マーカーと線の地図レイヤへの追加
m.add_child(line)

始点と終点をアイコンで表示
GPSデータの最初と最後の座標を取得し、folium.Marker関数でアイコンを表示します
folium.Marker(location=[locations.Latitude[0], locations.Longitude[0]], icon=folium.Icon(color="red", icon="home")).add_to(m) folium.Marker(location=[locations.Latitude[numPlot-1], locations.Longitude[numPlot-1]], icon=folium.Icon(color="red", icon="step-forward")).add_to(m) m

結果の保存
m.saveを用いてhtlm形式で保存することができます。私の環境ではそのまま開くとうまく見ることができました
m.save('out.html') # 結果の保存
まとめ
MATLAB Mobileを用いてGPSデータを取得し、MATLAB Mobile(の無料の機能)を用いてGPSのデータをCSV形式で保存をしました。そしてpythonのfoliumを用いてその軌跡をプロットすることができました。同様の機能やライブラリを用いて他にもあらゆるタイプのプロットができそうです。
機会があればまた別のプロットの種類も試してみたいと思います。
参考にさせていただいたサイト
全体の流れについて1:Folium公式ドキュメント
全体の流れについて2:foliumを使って東京23区ラーメンスコアを可視化する
グラデーションの色の変更について参照:python foliumのコロプレス図で選択可能なfill_color について
線を書く際のコマンドについて参照:PythonとFoliumで簡単に!位置情報を可視化する方法
今後の改良のために参考にしたいページ:python folium を使い、都道府県の夫婦年齢差をプロットする
東京都の市区町村コード一覧のリストを作成するため:東京都の市区町村コード一覧
東京23区の人口について:東京都HP(都内区市町村マップ)