exiftoolを用いて写真の位置情報を変更してみよう
この記事では、exiftoolを用いて、動画や画像のメタ情報の閲覧や、編集を行う方法について述べます。
画像のメタ情報の例
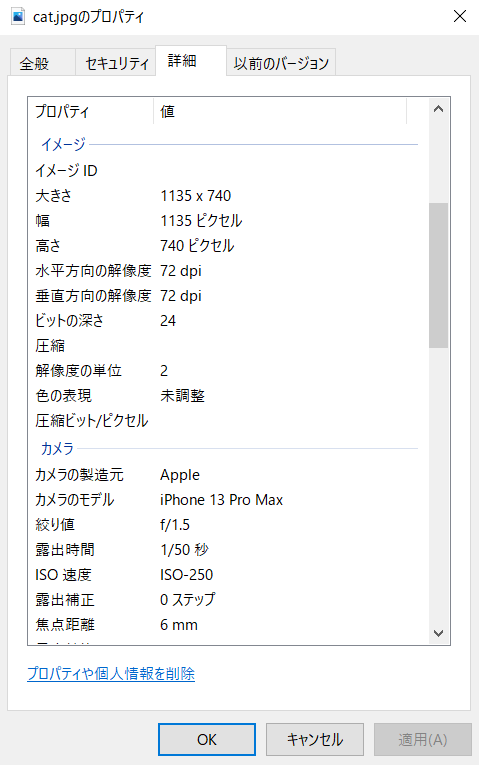
Windowsで画像上を右クリックし、プロパティを表示させると、以下のように画像の情報(例:画像のピクセル数やカメラ名、カメラの焦点距離)が確認できます。より詳しい情報を知りたい場合や、それらの情報を更新したい場合にはexiftoolが便利です。このページでは、exiftoolsを用いて、画像のメタ情報を読み込み、さらに、その位置情報を更新する方法について述べます。 この記事で用いた画像やスクリプトは以下のgithubのページにアップロードしています。
exiftoolのダウンロードについて
以下のページからexiftoolをダウンロードすることができます。
私はWindowsを用いているので、赤枠で示される、Windows用の実行ファイルをダウンロードしました。
exiftoolの使い方に関しては、以下のページが参考になりました。
ExifTool.exe の簡単な使い方 - 表示編
ExifTool.exe の簡単な使い方 - 編集編
exiftoolを使ってみる
以下の画像でexiftoolを試してみようと思います。はじめに、実行ファイルの名前をexiftool.exeに変更しました。

コマンドは、以下の通りです。コマンドプロンプトから実行します。
exiftool.exe ./testImages/cat.jpg

撮影したカメラ(iPhone 13 Pro Max)の名前や、ファイルサイズなどの基本的な情報が確認できます。
画面を下にスクロールするとさらに詳しく情報をみることができます。
より詳しい使い方については、以下のページが参考になりました。
http://pen.envr.tsukuba.ac.jp/\textasciitilde{}torarimon/?EXIF%BE%F0%CA%F3%A4%CE%CA%D4%BD%B8
画像を撮影した時の向きを確認する
横向き、縦向きなどの、orientationの情報を確認します。orientationについての説明は以下のページがわかりやすかったです。
別の画像で同様のコマンドを用います。用いた画像は以下の通りです。
exiftool.exe ./testImages/keyCase.jpg

以下が結果になります。
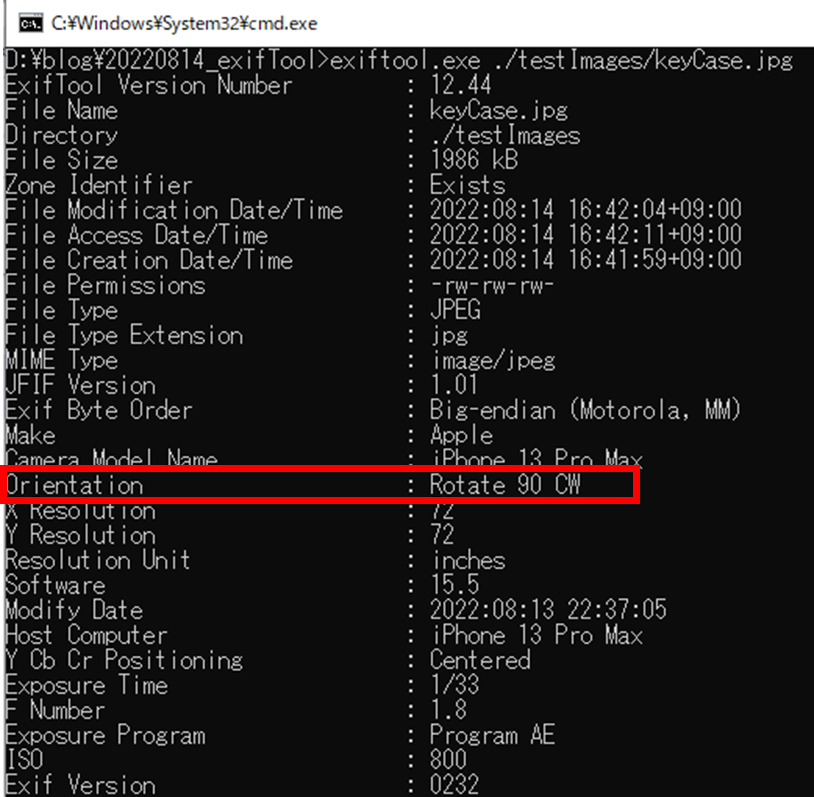
orientationの値が、Rotate 90 CWになっていることがわかります。これは、時計周りに90度回転という意味だそうです。
以下のページが参考になりました。
位置情報を更新してみる
最後に、exiftoolを用いて、exif情報の更新を行います。
例えば、以下のような、東京都墨田区の名誉区民顕彰コーナー 王貞治のふるさと墨田
の画像を用います。

墨田区の錦糸公園付近で撮影されましたが、うまくexif情報に反映されていることを確認します。
以下はMATLABコードです。imfinfoを用いて、画像の位置情報を取り出すことができます。
metainfo = imfinfo('./testImages/ohMusium.jpg');
lat_dms = metainfo.GPSInfo.GPSLatitude;
lat = dms2degrees(lat_dms);
lon_dms = metainfo.GPSInfo.GPSLongitude;
lon = dms2degrees(lon_dms);
figure;geoscatter(lat,lon,30,'red','filled')
geobasemap 'satellite'
geolimits('auto')
度分秒(DMS)単位を度単位に変換しています。dms2degrees関数を用いて変換しています。
以下のページがわかりやすかったです。
https://meria21.hamazo.tv/e7882429.html
画像中央の赤点で示されているように、確かに錦糸公園内で撮影されていることが確認できます。

次に、以下のサイトから、東京ドームの経度緯度を検索し、以下のコマンドで経度緯度の情報を更新します。
exiftool.exe -gpslatitude=35.7056232 -gpslongitude=139.751919 ./testImages/ohMusium.jpg
同様のコードで、地図上に可視化した時の結果です。東京ドームの中央に赤点が示されており、画像中の位置情報を更新することができました。

まとめ
この記事では、exiftoolの簡単な使い方を紹介しました。位置情報を更新する前後で、地図上の位置が確かに変化しており、正しくコマンドが動作していることが確認できました。exiftoolによって、多くの情報が取得できるため、今後も継続して勉強していきたいと思います。
サブフォルダも含めてファイル一覧を取得する
1. はじめに
この記事では、特定のフォルダの中に存在するファイルを、サブフォルダも含めて取得する方法についてメモを残します。
ここで用いたコードやファイルは以下のページにアップロードしています。
2. コードについて
2.1. MATLAB
dir関数を用いる際に、\**\と指定すればよい。
% サブフォルダも含め、txtデータを集める txtList = dir(fullfile(pwd, 'folder1\**\*.txt')); %get list of files and folders in any subfolder % 拡張子を含めず、あらゆるファイルを取得する filelist = dir(fullfile(pwd, 'folder1\**\*')); filelist = filelist(~[filelist.isdir]); % フォルダの情報を削除する
2.2. Python
globモジュールを用いる場合を考える。MATLABの場合と同様に、Pythonの場合は /*/をつけるとよい。
import os from glob import glob txtFiles = glob(os.getcwd() + "/folder1/*/*.txt", recursive = True) print('==== file list ====') print(txtFiles) for i in txtFiles: print('==== file name ====') print(i) # 任意の処理を行う
参考ページ
How to recursively go through all directories and sub directories and process files?
MATLABで、あるフォルダ以下のサブフォルダのリストを作る => 任意の拡張子のファイルパスを取得 (ここでは*.jpg)
サポートベクターマシン(SVM)の分離平面の可視化 (Python, MATLAB)
この記事では、サポートベクトルマシン(SVM)を用いて、分類を行ったときの、分離のための超平面を可視化することを行います。PythonとMATLABにて書いてみたいと思います。ここでは、3つの変数を説明変数として用いて、3次元プロットによる可視化を行います。
可視化におけるポイントは、
1. XYZの範囲内でその値を小刻みに変更しながらグリッドを作成する
2. そのデータに対してSVMによる分類を行う
3. そのときの結果の中で、分類平面に近いデータを取り出す
4. そのデータを訓練データと重ね合わせて表示する
ということです。
コードは以下のページにアップロードしています。
モジュールのインポート
この例では、jupyter notebookを用いています。点を3D上でプロットして、くるくると回すために、%matplotlib notebookと指定します。
from sklearn.svm import SVC import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets from mpl_toolkits.mplot3d import Axes3D from scipy.interpolate import griddata %matplotlib notebook
irisデータセットの読み込み
ここでは、irisデータセットを用います
iris = datasets.load_iris() X = iris.data[:, :3] # 3つの変数のみを用いる Y = iris.target # 用いるデータの作成 X = X[np.logical_or(Y==0,Y==1)] Y = Y[np.logical_or(Y==0,Y==1)]
SVMの学習
ここでは、ガウシアンカーネルを用いて学習を行います。線形カーネルで行う場合は、"linear"と指定します。
# 分類器の準備 model = svm.SVC(kernel='rbf',probability=True) # 学習 clf = model.fit(X, Y)
分離平面を可視化するためのテストデータを作成する
各変数の最大値と最小値を求め、その範囲でテストデータを作成します。mesh_sizeという変数で、その間隔を制御します。小さい値に設定すると、より厳密な分離平面を得ることができますが、一方で、計算時間が長くなります。
# データを作成する間隔 mesh_size = 0.2 # 変数をそれぞれ、x1, x2, x3とする x1 = X[:,0] x2 = X[:,1] x3 = X[:,2] # 作成する範囲を大きくしたい場合marginを0より大きい値にする margin = 0 # xyzの最小、最大値を求める x_min, x_max = x1.min() - margin, x1.max() + margin y_min, y_max = x2.min() - margin, x2.max() + margin z_min, z_max = x3.min() - margin, x3.max() + margin # mesh_sizeに応じて点を作成する xrange = np.arange(x_min, x_max, mesh_size) yrange = np.arange(y_min, y_max, mesh_size) zrange = np.arange(z_min, z_max, mesh_size) x,y,z = np.meshgrid(xrange,yrange,zrange) # flatten x = x.reshape(-1) y = y.reshape(-1) z = z.reshape(-1)
分離平面を可視化するためのテストデータと訓練データを重ね合わせる
前のセクションで作成したテストデータが、訓練データと重なっているかを確認する
# 可視化 fig = plt.figure() ax = fig.add_subplot(projection='3d') # テストデータのプロット ax.scatter(x, y, z) # 訓練データのプロット ax.plot3D(X[Y==0,0], X[Y==0,1], X[Y==0,2],'ob') ax.plot3D(X[Y==1,0], X[Y==1,1], X[Y==1,2],'sr') plt.show()

テストデータの予測
xyz = np.vstack([x,y,z]) xyz = xyz.T y_pred = clf.predict_proba(xyz)
クラスAとBの確率が等しいテストデータを抽出
diff = y_pred[:,0]-y_pred[:,1] idx = np.where(np.abs(diff)<0.1) xyz = xyz[idx,:] out = np.squeeze(xyz)
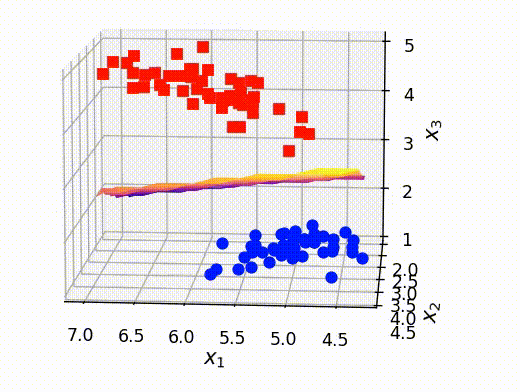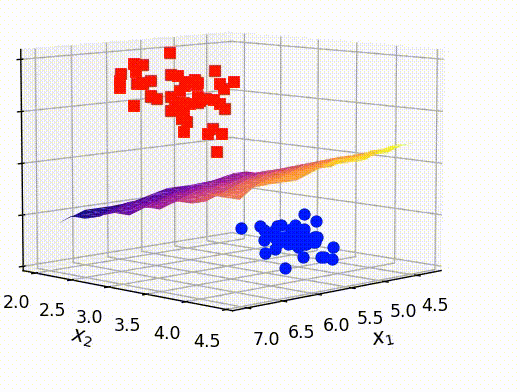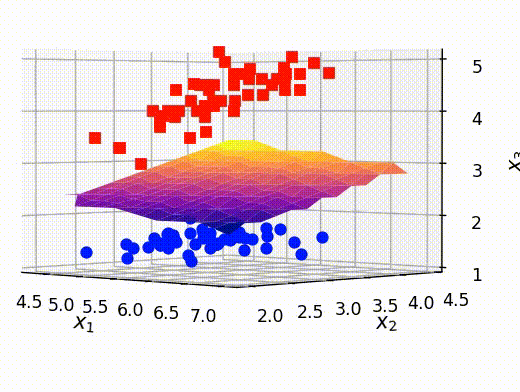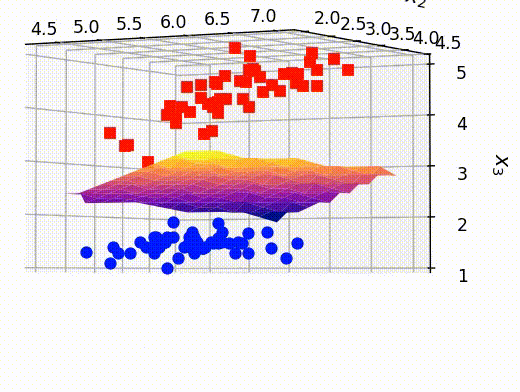
分離平面の可視化
最後に、前のセクションで取り出した点ともとの訓練データを重ねて表示させます。これにより、うまく分離平面が可視化できていることがわかります。
# クラスAとBの確率がほぼ等しい点のx,y,z情報を抽出する x_selected = out[:,0] y_selected = out[:,1] z_selected = out[:,2] # surfaceプロットをするための準備 x_new, y_new = np.meshgrid(np.unique(x_selected), np.unique(y_selected)) z_new = griddata((x_selected, y_selected), z_selected, (x_new, y_new)) # 可視化 fig = plt.figure() ax = fig.add_subplot(projection='3d') ax.plot3D(X[Y==0,0], X[Y==0,1], X[Y==0,2],'ob') ax.plot3D(X[Y==1,0], X[Y==1,1], X[Y==1,2],'sr') # surfaceの可視化 ax.plot_surface(x_new, y_new, z_new,cmap='plasma') ax.set_xlabel(r"$x_1$", fontsize=12) ax.set_ylabel(r"$x_2$", fontsize=12) ax.set_zlabel(r"$x_3$", fontsize=12) ax.set_title("Visualizing hyper-plane", fontsize=12) plt.show()
参考文献
以下の記事などが参考になりました。著書の皆様、ありがとうございました。
PythonからPDFを画像に変換&画像からPDFに変換する方法のメモ
この記事では、Pythonを用いて、PDFファイルを読み込んで、画像に変換すること、さらに、画像からPDFに変換する方法について調べたのでメモとして残したいと思います。
ここでのスクリプトで特定のことをしたいわけではなく、Pythonを用いたPDFの読み込み、書き込みの経験がなかったので練習をしたいと思いました。大量のPDFの処理の用事などができたら、今後利活用できたらよいなと考えています。ここでの内容は、
- PDFを画像に変換して、各種端末で見やすくする
- 大量の画像を一気にPDF化して保存する
といったことにつながるのではないかと考えられます。このほかにも、皆様の役に立てば幸いです。
1. PDFを扱うことのできるPythonライブラリーについて
- PyPDF2
- PDFMiner
- pdf2image
- img2pdf
などがあるようです。また、PyPDF2よりも、PDFMinerをおすすめする記事もありました。
ここでは、pdf2image, img2pdfを用いて、PDFの読み込みや画像への変換、そして、その画像を拡大してからPDFへの変換などを行っていきたいと思います。
さっそく、以下に、今回用いたPythonコードを記載していきます。
2. Pythonコード
2.1. 準備
同じディレクトリに、dataというフォルダを用意してください。参考のために、練習用ファイルを以下のURLにアップロードしています。
2.2. モジュールの読み込み
あらかじめ、PILやimg2pdf, pdf2imageなどのモジュールをインストールしておいてください。
from pdf2image import convert_from_path from PIL import Image, ImageDraw, ImageFilter import os import glob import img2pdf
2.3. PDFファイルの確認
# PDFから画像に変換したものを拡大するときのパラメータ。参考程度にお使いください。 fx = 1.2 fy = 1.2 # PDFファイルのパスを参照する pdf_data = glob.glob('./data/*.pdf') # 一度書き出す画像はimageというフォルダ、最終的な出力はfinalOutputというフォルダに格納します。まだ作成していない場合、自動的にそのフォルダを作成します img_path = './image' out_path = './finalOutput' print('==========') print('Does the output path for img exist?') print(os.path.exists(img_path)) # 画像を格納するフォルダがあるかどうか確認する if os.path.exists(img_path)==False: os.mkdir(img_path) print('ouput folder for img created') print('==========') print('Does the output path for pdf exist?') print(os.path.exists(out_path)) # PDFを格納するフォルダがあるかどうか確認する if os.path.exists(out_path)==False: os.mkdir(out_path) print('ouput folder created')
==========
Does the output path for img exist?
True
==========
Does the output path for pdf exist?
True
2.4. convert_from_pathを用いて、PDFから画像に変換する
convert_from_pathの引数については以下のページをご覧ください。2.5で画像を拡大しますが、ここで、dpiの値を大きくすることも可能です。
https://pdf2image.readthedocs.io/en/latest/reference.html#functions
for i in range(len(pdf_data)): print(str(i)+'-th data is being processed. Target file is '+pdf_data[i]) # 拡張子なしのファイル名を取得する basename = os.path.basename(pdf_data[i]) file_name = os.path.splitext(basename)[0] # PDFが2ページ以上ある場合は、single_file=Falseとする convert_from_path(pdf_data[i], output_folder=img_path,fmt='png',output_file=file_name,single_file=True) print('Done!') print('All pdf files have been converted into images')
0-th data is being processed. Target file is ./data\test1.pdf
Done!
1-th data is being processed. Target file is ./data\test2.pdf
Done!
2-th data is being processed. Target file is ./data\test3.pdf
Done!
All pdf files have been converted into images
2.5. 画像を拡大し、PDFに変換する
dir_path = './image/' png_data = glob.glob(os.path.join(dir_path,'*.png')) for i in range(len(png_data)): print('==========') print(str(i)+'-th data is being processed. Target file is '+png_data[i]) # 画像の読み込み img = Image.open(png_data[0]) # リサイズ size = (round(img.width * fx), round(img.height * fy)) outsize = (img2pdf.mm_to_pt(round(img.width * fx)),img2pdf.mm_to_pt(round(img.height * fy))) layout_fun = img2pdf.get_layout_fun(outsize) # 拡張子なしのファイル名を取得する basename = os.path.basename(png_data[i]) file_name = os.path.splitext(basename)[0] print(file_name) file_name_pdf_out = out_path+os.path.sep+file_name+'_enlarged.pdf' # 出力するときのファイル名を取得する print('Output file name is ') print(file_name_pdf_out) # 書き込み with open(file_name_pdf_out, "wb") as f: f.write(img2pdf.convert(png_data[i],layout_fun=layout_fun)) print('==========') print('Good job! All steps are finished!!') print('==========')
==========
0-th data is being processed. Target file is ./image\test1.png
test1
Output file name is
./finalOutput\test1_enlarged.pdf
==========
1-th data is being processed. Target file is ./image\test2.png
test2
Output file name is
./finalOutput\test2_enlarged.pdf
==========
2-th data is being processed. Target file is ./image\test3.png
test3
Output file name is
./finalOutput\test3_enlarged.pdf
==========
Good job! All steps are finished!!
==========
参考ページ
冒頭で述べたページに加えて以下のページなどを参考にさせていただきました。ありがとうございました。
Pythonのsubprocessモジュールの実行について
1. はじめに
Pythonのsubprocessの使い方について、自分用のメモとして残したいと思います。subprocessの使い方に関しては、以下のYOUTUBEがわかりやすかったです。subprocessでは、
といったことが可能になります。
マルチプロセスの内容については、以下の動画がわかりやすかったため、割愛させていただきます。
2. subprocessの使い方
2.1. 基本的な書き方について
2章のコードは、さきほどのYOUTUBEの内容を参考にさせていただきました。また、ここでは、Ubuntuを利用しています。
例えば、こちらのコードで、現在のパスにあるファイルの一覧を参照することができます。
subprocess.run(["ls"])
また、入力が複数ある場合は、リストにして、以下のようにします。
subprocess.run(["sleep","10s"])
2.2. 戻り値が欲しい場合
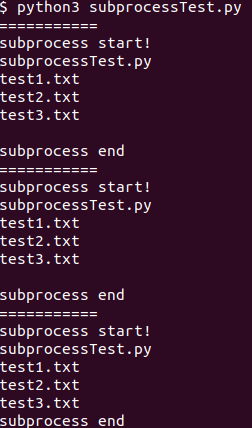
例えば、以下のようにすることで、戻り値を得ることができます。上の動画では3パターン紹介されていました。以下のどのパターンでも同じ結果を得ることができます。このスクリプトをsubprocessTest.pyとしています。
import subprocess # Pattern1 print("===========") print("subprocess start!") a = subprocess.check_output(["ls"]) print(a.decode()) print("subprocess end") # Pattern2 print("===========") print("subprocess start!") a = subprocess.run(["ls"], stdout = subprocess.PIPE) print(a.stdout.decode()) print("subprocess end") # Pattern3 print("===========") print("subprocess start!") a = subprocess.getoutput(["ls"]) print(a) print("subprocess end")
実行したときの結果は以下のようになりました。同じ結果が3回得られていることがわかります。
2.3. 非同期処理について
subprocessの計算結果を待たずに、非同期で処理を行うこともできます。例えば、subprocessの処理をしながら、その下のコマンドを実行していくというった感じです。
非同期処理では、subprocess.Popenを使います。例えば以下の記事がわかりやすかったです。ここではコードについては割愛させていただきます。
3. Windowsにて、exeファイルを実行する
2章ではUbuntuにてsubprocessを用いていました。ここでは、Windowsで、Pythonのスクリプトから、exeファイルを実行してみたいと思います。
実行ファイルの例として、動画の処理などでよく用いられる、FFmpegを用いたいと思います。内容やインストールの方法については、以下の記事がわかりやすかったです。
冒頭で述べた通り、subprocessでは、Pythonからコマンドプロンプトを使うことができます。そのため、FFmpegといったexeファイルをPythonから動かすことができます。以下のように行うことができます。
import subprocess cmd1 = 'D:/hatena/ffmpeg-master-latest-win64-gpl-shared/bin/ffmpeg.exe -i sample.mp4 -r 60 image%04d.png' subprocess.run(cmd1)
このコマンドでは、動画から静止画に切り出すことができます。
こちらのページにサンプルの動画などをアップロードしています。何かの役に立てば幸いです。
簡単に、Pythonのsubprocessについての備忘録を残しました。間違いなどがございましたら教えていただけると嬉しいです。
参考文献
文字列・数値に対してゼロ埋めをし、000123.jpgのような文字列を作成する(ゼロパディング)
数字の表記を、1234ではなく、001234のように特定の数字などで埋めたい場合があると思います。この記事では、MATLABとpythonにおけるコードについて自分用のメモとして残したいと思います。例えば、
- 123, 18, 1931...のように桁数の違う数字を含むファイル名において、00123.jpg, 00018.jpg, 01931.jpgのようにすると統一性が出る
- file1.txt, file2.txt, file10.txtを並び替えると、file1.txt, file10.txt, file2.txtという順番になる場合がある。ファイル名からゼロで埋めると数字の大きさ(小ささ)の順に並び変えられる。
といった場合に有効であると考えられます。
MATLABの場合
sprintf('%07d', 1234)
とすれば、0001234という値(char)が返されます。
並び替えをうまく行いたい場合は、sort_natを使うこともできます。
pythonの場合
v = '1234' v.zfill(7)
のように、zfillを用いるとよいです。vは文字列であることに注意する必要があります。他にも複数方法が存在するようです。以下のページが参考になりました。
今回のメモの原稿や他の記事のコードやデータはこちらにアップロードしています。
シェルスクリプト内で、Conda環境をアクティベートし、実行する方法に関するメモ
1. はじめに
Windowsのバッチファイルのように、Ubuntu上で、複数のpythonのスクリプトをまとめて実行したいなと考えました。condaを用いて環境構築をしていたため、その環境も呼び出したうえで、複数のスクリプトを実行します。本稿はその方法についての備忘録です。
2. うまく行った方法
myScript.bashという名前のファイルを作成し、例えば、以下のように記述します。
source /home/OsakaTaro/anaconda3/etc/profile.d/conda.sh # OsakaTaroはユーザー名。適宜変更する conda activate myEnvironment python3 myScript.py conda deactivate
そして、
source myScript.bash
と、ターミナル上で実行すれば、conda環境で、myScript.pyを実行することができました。