MATLABのNormalize関数で使った平均と標準偏差を保持して、未知データに対しても同じ演算をする+もとのスケールに戻す
データ分析において、対象のデータをスケーリングしたい場合、例えば、平均0・分散1になるよう変換する場合が多いと思います(標準化)。MATLABでは、normalize関数を用いれば1行で済むため、非常に便利です。しかし、同様の式を用いて、別のデータも標準化したいときがあります。または、標準化したものをもう一度もとのスケールに直したい、といったこともあります。その場合は、normalize関数の戻り値に、その標準化に用いた平均値・標準偏差を指定することで、そのような追加の変換や、もとのスケールへの再変換が簡単に行えます。
公式ドキュメントは以下の通りです。
はじめに、normalize関数は、
N = (A - C) ./ Sを満たすCとSを配列として返します。
とあります。Cが平均、Sが標準偏差であると思われます。methodtypeで指定できる、標準化の方法が複数ありますが、今回は、既定であるz-scoreとします。
整数を30個生成してみます。
data=randi(100,[30,1]);%100までの整数を30個生成する
これをnormalize関数を用いて標準化します。ここでは、後ろ2つの戻り値を指定することがポイントです。先頭の1つしか指定しない場合が多い気がしますが、このように3つ指定すると便利です。。
[N,average,stdev]=normalize(data); % 戻り値にaverage, standard deviationを指定できる
標準化したあとの値を見てみます
N
N = 30x1
-1.0634
1.7534
-1.3910
1.1311
1.2621
1.4259
-1.1289
-0.1135
-0.5721
1.2294
検算のため、平均を引いて、標準偏差で割れば同じ値になることを確認します。
N_check=(data-average)/stdev
N_check = 30x1
-1.0634
1.7534
-1.3910
1.1311
1.2621
1.4259
-1.1289
-0.1135
-0.5721
1.2294
逆に、標準化したあとに、もとのスケールに戻すことを行います。
data_check=N*stdev+average
data_check = 30x1
11
97
1
78
82
87
9
40
26
81
もとのデータと一致していることを確かめます。
data
data = 30x1
11
97
1
78
82
87
9
40
26
81
以上、normalize関数を用いるときに、別のデータも標準化する方法、そして、標準化したものをもう一度もとのスケールに戻す方法を簡単にまとめました。

画像の2値化の方法を数式から理解したい
1 はじめに
この記事では、画像を対象として、2値化処理(2値化とする)の方法を説明します。メインパートでは、丁寧に式展開をしながら2値化の方法(判別分析法)の説明を行いました。もし何か間違いがございましたら教えていただけますと幸いです。
この記事の本文のファイル(md形式およびPDF形式)や、この記事のデモのコード(MATLAB, Python)は以下のページにアップロードしています。自学自習や勉強会など何かの役に立てばうれしいです。
なお、この記事は、デジタル画像処理の2値化のページを参考にしていて、そのページを詳しく書いたような構成になっています。2値化をベースにしたさらなる応用例などはデジタル画像処理に記載があります。
早速ですが、以下の画像を見てください。
左の画像は入力画像で、右側が明るいピクセルを白、暗いピクセルを黒で示しています。2値化により、自動的に明るい/暗いピクセルに分けています。この2値化の処理を行うことで、画像に映る対象を自動的に取得したり、画像を大きく分割するといったことができます。
I = imread('demo_img\img2.jpg');
I_gray = rgb2gray(I); %グレースケールに変換
BW = imbinarize(I_gray,'global'); % global:大津の2値化
figure;imshowpair(I,BW,'montage');title('左:入力画像、右:2値化後の画像(明るい部分が抽出できている)',"FontSize",14)

図1:2値化を行ったときの例。左が入力画像で、右が2値化を行った後の結果を示す。2値化を行ったことで、明るいピクセルと暗いピクセルを分けることができていることがわかる。
ほかの利用例として、以下の図2を見てください。こちらは、ミブログさまの記事より引用しています。ここでは、顕微鏡画像のようなものから対象のピクセルを取り出しています。例えば、観察したい細胞のエリアのみを自動的に取り出すということもできるかもしれません。

図2:顕微鏡画像のようなものを対象にした2値化の例
画像出典:ミブログさま(2値化 - 画像解析の基本処理、対象を検出する)
また、もう一つの例として、以下の図3を見てください。こちらはAniLaSoftさまのページより引用しています。これは、2値化のほかにも処理を行っていますが、処理の一部として2値化を利用することで、右下のようなスケッチを得ることができています。
画像出典:AniLaSoftさま(2値化 操作手順)
このように、2値化は画像処理の基本的な技術として多くの分野で活用されています。次の章から具体的にどのような処理を行っているか説明したいと思います。
2 2値化の方法について
2-1 2値化の方法のイメージ
以下の図4に示すヒストグラムは、2値化の方法のイメージを示しています。対象は対象の画像(または、対象とするエリア)の画素(ピクセル)です。横軸は画素の値、縦軸はその値が何度現れたか(頻度)を示しています。画像の中の画素を見たときに、暗い部分と明るい部分があれば、以下のような2つのピークを観測することができます。今回紹介する2値化の方法では、この2つのピークを「いい感じに」分割する閾値tを探し、そこで明るい/暗いエリアに分割します。それぞれのクラスをそれぞれ、白画素クラス、および、黒画素クラスと呼ぶことにします。次の節で、具体的にどのように計算するかを説明します。

図4:2値化の方法のイメージ
始めに、以下の表1に、本記事で扱う変数についてまとめています。画像全体の画素の平均をとし、分散を
、そして、画像全体のピクセルの数を
とします。また、2値化を行ったあとの、黒画素のクラス/白画素のクラスについても同様に変数を設けます。それに関しては、表の中段及び下段をご覧ください。
表1:本記事で主に用いる変数について

2値化の結果がどのような場合に、「いい感じ」であるかを考えます。まず、黒画素クラスと白画素クラスでは、その両者のクラス間で、画素値ができるだけ離れているとよいです。画像中の暗い部分と明るい部分を分けることができていれば、それらの差は大きくなると考えられます。
また、それぞれのクラス内ではどうでしょうか。同じクラス内では、その輝度値が似ているので、その輝度の違いは小さいはずです。そのクラス間およびクラス内で輝度値がどれほど変動しているかを示す指標として、分散が考えられます。そこで、クラス内とクラス間のそれぞれで、分散の値を考えていきたいと思います。
2-2 クラス内の分散について
クラス内の分散についてですが、黒画素クラスおよび白画素クラスの分散は、表1に示した通りです。これらの値は黒画素クラスと白画素クラスを分ける閾値tが決まれば、一意に定まる値です。クラス内分散を以下のように定義します。
と
は、それぞれ黒画素クラスと白画素クラスの分散なので、以下の式(1)は、それぞれの分散をピクセル数による重みつき平均を求めていることになります。例えば、黒画素クラスに属する画素数が画像中の画素数の90%、そして、白画素クラスに属する画素数が画像中の画素数の10%である場合は、黒画素クラスと白画素クラスの分散を9:1の割合で重みづけをして平均を取っていることになります。
...(1)
この式(1)の第一項と第二項を足し算して、式(2)としてます。
...(2)
2-3 クラス間の分散について
次に、クラス間の分散を考えます。クラス間の分散を式(3)のように定義します。各クラスの画素の平均値から画像全体の輝度値の平均を引いて、2乗をしています。ここでもクラス内分散と同様に、黒画素クラスと白画素クラスの画素数によって重みづけをしています。黒画素クラスと白画素クラスの平均が全体から離れるほど、以下の式(3)の値は大きくなります。逆に黒画素クラスと白画素クラスの画素の平均値がそれぞれ画像全体の画素値の平均と同じ(つまり黒と白を分けられてない)場合は、このクラス間の分散の値は0になります。先述したように、この値は大きくなることが望ましいです。
...(3)
ここで、画像全体の輝度値の平均は式(4)によっても表すことができます。輝度値の平均は各画素の値を足して平均をすることで計算ができますが、黒画素クラスと白画素クラスの平均にそれぞれのピクセル数を掛け算して、すべての画素の数で割り算しても求めることができます。
...(4)
この式(4)のの値を、式(3)に代入し、整理していきます。式(3)は以下のようになります。
...(5)
1つ目の括弧の中のの分母と分子に
をかけて、
...(6)
分子の値を計算し、さらに分母のを括弧の外に出して、
...(7)
第一項、第二項からそれぞれ、と
を括弧の外に出して、
...(8)
が共通するため、
...(9)
であり、でも括ることができて、
...(10)
となる。分母と分子のを打ち消して、以下の式(11)を得る。
...(11)
2-4 全分散について
また、画像の全分散とクラス内分散・クラス間分散は以下の式(12)の関係があります。
...(12)
ここで、2値化の方法の結論の前に、なぜ式(12)が成り立つのかを考えたいと思います。ただ、ひとまず式(12)が成り立つとして、実際にどのように2値化が行わているか先に知りたい場合は、2-5章をご覧ください。
2-4-1 全分散=クラス内分散+クラス間分散?
全分散は、画像の各画素をサンプルとしたときの分散の値と等しいです。そのため、画素中の画素値をなどとすると、全分散は以下の式(13)で計算することができます。
...(13)
ここで、などの、画素値に関してですが、2値化を行ったあとに、それぞれ、黒画素クラス/白画素クラスに分かれます。式(13)の各画素の値を2値化後の結果で置き換えます。つまり、
などの、画素値を、
や
(それぞれ黒と白画素クラスに相当)とすると、
...(14)
と表すことができます。
この値が、式(2)のクラス内分散と式(4)のクラス間分散の和と等しければ、全分散=クラス内分散+クラス間分散であることがわかります。
ここで、式(2), (4), (14)ともに、分母の値がであるので、分母の値は無視して考えます。
まず、黒画素クラスに分類されたピクセルに対して考えます。
分散の定義から
...(15)
となります。両辺にを掛けて、
...(16)
を得ます。
(クラス内分散)+(クラス間分散)とすると(ただし分母の値は無視する)、
![]()
...(18)
また、二項目に関しては、以下のように、書き換えます。
...(19)
一方、
(全分散)とすると、
...(20)
となります。
ここで、を計算して、
であれば、全分散=クラス内分散+クラス間分散であることがわかります。
...(21)
を省略して展開すると、
...(22)
(22)を整理して、を省略せずにまとめると、
...(23)
...(24)
に関して、黒画素クラスの平均
×(黒画素クラスのピクセル数)の値と、黒画素クラスの輝度値の総和は等しいので、ゼロになる。つまり、式(24)の値は
となる。
よって、
...(25)
となり、、つまり、全分散=クラス内分散+クラス間分散であることがわかる。
2-5 閾値の決定について
ここで、クラス内分散とクラス間分散について考えます。
- クラス内分散:小さいほうが良い(黒画素・白画素クラスでは、同じクラス内では似た画素値があればよい)
- クラス間分散:大きいほうが良い(黒画素・白画素クラス間で、その画素値が、より異なっているほうがよい)
よって、クラス間分散÷クラス内分散である、 ...(26)
を考え、この値が大きいほど、2値化においては望ましいことになります。またこの値のことを分離度と呼びます。
前節で確認したように、の関係を利用すると、分離度
は、
...(27)
となります。全分散であるは、2値化に用いる閾値に関わらず一定であり、クラス内分散
が最小になるように閾値tを求めればよいことがわかります。
3 まとめ
- この記事では、画像を2値化するための方法(判別分析法)を紹介しました。
- クラス内分散やクラス間分散を求め、最終的に分離度が最大になるように閾値tを決めればよいことがわかりました。
- この方法では、閾値を自分で決める必要がない点で非常に有用です。
参考文献
ディジタル画像処理編集委員会:デジタル画像処理(リンク)
主成分分析 (Principal Component Analysis: PCA)を簡単に、かつわかりやすく説明したい
0章:はじめに
- この記事では、主成分分析や統計に関して初心者の方でも直感的に、かつある程度数式も合わせて理解できるようになることを目指しています。
- 筆者の勝手な理解をベースに執筆しているため、一部、曖昧な/厳密でない 表現があるかもしれません。
- 筆者の理解に従い、自身で主成分分析を1からコーディングし、数値計算のソフトウェアによって主成分分析をした結果とおおむね結果が一致していることを確かめています。これにより筆者の理解が正しいか確認いたしました。
- もし間違いなどあれば教えていただけると幸いです。
本記事の原稿のマークダウンファイルや、PDFファイルは以下のページにアップロードしています。文字化けがある場合や、何かのまとめに使いたい場合は以下からダウンロードしていただけますと幸いです。
また、pythonによる主成分分析のお試しのコード(栄養データを対象)も用意していて、それらは以下のページからダウンロードできます。
github.com
1章: 2次元や3次元で可視化して対象を捉えてみる
1-1 お土産にフルーツを買おう
例えば、お土産として、フルーツを友人宅に持っていくときのことを想像してください。どのフルーツを持っていくかを決定する方法としては、パッと浮かんだおいしいフルーツを買っていく、近くのスーパーに売っている旬のものを買う、友人と食べる夕食のメニューに合いそうなものを思い浮かべる、などがあると思います。メニューに合うように、味を考慮して選ぶとすれば、例えば、以下のように、グループ分けをすることも可能でしょう。思い浮かんだフルーツを、甘い/酸っぱいの基準にグループ分けし、甘いものがいいか、酸っぱいものがいいか、甘くて酸っぱいものがいいか、など考えることができます。甘くて、酸っぱくないものがいい、となれば柿などが候補になるでしょう。

実際に、上のようにグループ分けをしてフルーツを選ぶかどうかは人によるでしょう。しかし、複数の候補から最適なものを選んだり、複数の対象を関連付けて考えることにおいて、上のような関係性を可視化することは重要です。
例えば、上のグループ分けの図から
- ゆずとみかんは似た味の系統である
- 甘いものとしては、柿がある
- 甘さという観点において、柿とレモンは対極にある
- アボカド(実はフルーツと区分される)は、他のフルーツとは、異なる味を持つ
などのことを直感的に類推することができます。
1-2 3つの要素をもとにお土産を買う場合
次は、フルーツだけでなく、何か友人宅に持っていって喜ばれるものを考えます。先ほどと同様に、ここでは味のパターン分けをしてみます。先ほどの例に、「辛い」という基準が増え、辛さ、甘さ、酸っぱさという基準で考えることにします。
ハラペーニョソース:辛いと同時に少し酸っぱさがある
キムチ:辛いと同時に酸っぱさや少し甘さがある
タコ焼き:酸っぱくも辛くもないが、少しソースが甘口である
ということにして、さきほどのフルーツに上の候補を足しました。3つの軸で考えても、以下のような空間的な散らばりを考えると、どうにか3次元上でグループ分けすることも可能そうです。

1-3 4つ以上の特性を同時に考える場合
これまでは、候補を独自の基準(甘さ、酸っぱさなど)でグループ分けし、可視化することで整理をしていました。お土産の品目を考える場合だけでなく、意思決定には基本的には複数の要素が混じるため、それぞれの候補を複数の「軸」をもとに比較することは重要です。例えば、パソコンを購入する場合、価格・OSの種類・計算速度・充電時間・見た目のかっこよさなど複数の条件をもとに意思決定をすると思います。
しかし、そのように整理して考えたい場合に、そのときの候補が非常に多くの特性を有していると考えるのが難しくなります。そして、それらの値自体がどのような意味を持つのか直感的にわかりにくく、どの特性を重視して考えてよいかさえ明確でない場合も多くあると思います。(その例として、フルーツの栄養素(ビタミンB、ビタミンCなど)をもとに、それぞれのフルーツをグループ分けする例をこの先で扱います。)
4つ以上の多くの要素をもつ対象を2次元の図のようにわかりやすく可視化して、対象をグループ分けしたり、それぞれの対象の近さ(例:ゆずとみかんは似ていそう)を概観する方法があると便利そうです。そのための手法として、この記事では主成分分析(Principal Component Anlysis: PCA)について述べます。主成分分析とPCAは同義ですが、本稿では、主成分分析という用語を用いることとします。
1-4 主成分分析がよく使われる場面について
主成分分析は多くの分野で活躍しています。以下に参考になる記事を紹介します。
1-4-1 アンケートデータの解析に使われる事例
Big Data Magazine様:主成分分析「使ってみたくなる統計」シリーズ第4回
1-4-2 2次元のマップに可視化してデータどうしを比べる場合
ポケモンで多変量分析・主成分分析を始めよう!
ポケモンの例が示されていて、非常に面白かったです。
1-4-3 高次元のデータに対して学習する際に用いる場合
入力するデータの次元数が大きくなり過ぎると、「次元の呪い」と呼ばれるように、データに対してうまくフィッティングすることが難しくなります。そのために、次元を圧縮したり、特徴を選択するために、主成分分析が使われることがあります。
TechCroud: 機械学習と次元の呪い
主成分分析(PCA)を使用して次元の呪いを追い出す
他にも、主成分分析が活躍する場面は多いです。継続して、この節の内容を充実させていきたいと思います。
2章:主成分分析についてざっくりと
2-1 ここで考えるデータについて
以下の表を見てください。フルーツとその栄養成分が示されています。この表の情報から、冒頭の「甘さ」・「酸っぱさ」の2つの軸で示したような図を作成することを目指します。少なくとも10以上の要素があるため、単に甘さや酸っぱさのみを基準にして2次元にプロットした図を作ることはできません。また、10個の軸をもって、可視化しようとしても、基本的に私たちは3次元の空間までしか認識できないため、そのまま可視化することはできません。

2-2 主成分分析を用いてフルーツのリストを2次元空間にプロットしてみる
ひとまず、上のフルーツのリストの栄養成分の値に対して、主成分分析を行い、冒頭の「甘さ」と「酸っぱさ」の2軸の図のような図を作成します。「ような」とは、10個以上の変数(ここでは、栄養素)がある中でも、どうにかそれを2次元にプロットしたことを意味しています。以下の図を見てください。10個以上の栄養成分が表にあるため、直接的に可視化することは難しいと述べました。しかし、ここでは、各フルーツが2次元平面にプロットされています。例えば、オレンジで囲われたところでは、柑橘系のものが集中していることがわかります。赤で囲まれた、りんごとなしも直感的に近しいフルーツな気がします。ひとまずここでは、「なぜ?どうして?」は置いておいて、主成分分析なる手法を用いて、10次元以上のデータを「いい感じに」2次元にプロットできたと思っておいてください。
また、x軸とy軸についても着目します。さきほどは、「甘さ」、「酸っぱさ」といった直感的な表現であった一方で、下図では、「PC1」、「PC2」という、ここでは初登場の用語が使われています。主成分分析を行って、栄養素のデータを変換したときの、1つ目の軸、2つ目の軸を示しています。ここでは、PC1, PC2などを主成分軸と呼びます。

2-3 バイプロットを用いた可視化
前節の2-2では、PC1やPC2という用語や、各フルーツのプロットについて、詳しく記述していませんでした。以下に、主成分分析により、2次元平面にプロットしたときの結果と、PC1(x軸)、PC2(y軸)の値に寄与する成分を重ねた図(バイプロット)を示します。赤色で、カルシウムやビタミンといった栄養成分が書かれています。ここで気づくこととしては、
1) 原点(スタートとする)から、ビタミンCに到達するまでの直線(赤色)の向きはPC1(x軸)とPC2(y軸)ともに、プラスの向きを持っている
:ビタミンCの多い、レモンはPC1、PC2ともに、高い値を有している
2) 鉄はPC1(x軸)のプラスの向きを持っている
:なしは、栄養成分表によると、鉄分の含有量は0である。PC1に対して正の値をもつ鉄分に関して、鉄分の含有量のないフルーツは左側(PC1においては負の方向)に位置している。
3) 原点からカリウムやエネルギーまでの直線は、PC1についてはプラス、PC2については負の向きを有する
:バナナも同様に、高いPC1/低いPC2の値を有する。バナナはカリウムが高いことや、また、エネルギーが高いことで知られ、マラソンの前に食べられることも多い。
などがあります。ここでも尚、10次元以上の栄養データを持つ各フルーツが2次元にプロットされただけで、どうしてそうなったのかはまだわかりません。ただ、そのプロットにもどうやらルールがあって、各フルーツは、栄養価の持つベクトルやそのフルーツのもつ栄養価にそってプロットされていそうです。
(なお、ここでは、赤色のベクトルは、固有ベクトルをプロットしています。因子負荷量をプロットする場合も多くありましたが、今回は因子負荷量への変換は行っていません。)

2-4 第一(第二)主成分と、固有ベクトルについて
前節の2-3で述べたことを言い換えると
- 赤色で示される直線にカリウムやビタミンCなどの栄養成分が紐づいている
- ビタミンCの含有量の多いフルーツ(レモン)とその直線は似た方向(位置)に存在する
といったことでした。この節では、主成分分析に関わる用語も混ぜていきたいと思います。
上の図では、PC1やPC2という、x軸・y軸に相当するものが示されていました。これをそれぞれ第一(第二)主成分(またはその軸のことを主成分軸)といいます。多次元の情報(ここでいう、10種類以上の栄養成分)をもつサンプル(フルーツ)を2次元にプロット(写像)したときの値です。
では、その第一主成分や第二主成分の値は何を持って決めるのでしょうか。そこで用いるのが、赤で示されたような、大きさと方向をもつ量(ベクトル)です。例えば、鉄分に対応するベクトルはPC1においては、正の値を有し、PC2(縦方向)においては、値は0に近い値を有しています。このベクトルのことを固有ベクトルといいます。鉄分の場合、PC1に対しては大きな値をPC2に対しては小さい値を持ちます。以下の図は、各栄養成分に対する固有ベクトルを示しています。先述したように、鉄では、PC1に関しては、比較的大きい値を有している一方で、PC2に関する値は非常に小さいことがわかります。

このように、固有ベクトルは各栄養成分に対する値を持っています。そして第一主成分や第二主成分を計算するために、その固有ベクトルを用います。例えば、品種改良したバナナを現在扱うとします。そのバナナのエネルギーの値とPC1に対応するエネルギーの固有ベクトル(0.295724)を掛け算し、次はその品種改良されたバナナの炭水化物の値と0.265667を掛け算する、、、といったことをビタミンCまで繰り返し、その和がPC1の値になります。つまり、
(品種改良したバナナのPC1の値)=(そのバナナのエネルギーの値)×(PC1のエネルギーに関する係数(=0.2957))+(そのバナナの炭水化物の値)×(PC1の炭水化物に関する係数(=0.2656))+ ... となります。このように、一次の式で合成し変数(合成変数)を作っていて、その係数はその合成変数にどの程度影響を与えているかを示しています。この合成変数のことを主成分と言います。
同様にPC2に関しても、PC2の2段目の値を用いることでPC2の値も計算することができます。それにより、品種改良したバナナを上の図に新たにプロットすることができます。式にすると以下のようになります。
はバナナのエネルギーの値、
はその係数(=0.2957)です。他の文字も同様です。
(品種改良したバナナを新たに加えたい場合、そのサンプルを加えたうえで主成分分析をやり直すほうがよいのかもしれませんが、今回はあくまで計算の手順の例として示しています。)
2-5 第三成分以降について
今回は、2次元上で可視化したいため、第二主成分までしか掲載していませんが、例えば、3次元上で可視化したい場合は、同様の手順で第三主成分も計算できます。以下のように、各主成分を計算するための固有ベクトルの値を示します。主成分分析では、2次元や3次元にプロットするだけでなく、n次元の入力を、主成分分析をしてn次元(または10次元など)の別の値をもつデータに変換し、重回帰分析などに用いる場合もあります。

2章まとめ
2章では少しボリュームが多かったため、簡単にまとめます。
- 2章では、主成分分析(PCA)によって、サンプル同士の関係を可視化する例について簡単に述べました。
- 主成分分析を用いて、4つ以上の変数がある場合でも2次元にプロットすることができました。
ただ、ここでも尚、なぜ・どのように、10次元以上ある栄養データを2次元に、「いい感じに」プロットしたのかわかりません。ざっくりとした概要の話でしたが、次章以降は、より詳しい内容について数式を交えてまとめたいと思います。
なお、分布の状況を直感的に把握しやすいように、ベクトルの次元を2次元または3次元に減らして布置を行うことを、オーディネーション (ordination)と言いますが(鷲尾泰俊・大橋 靖雄著:多次元データの解析)、この記事では、単に情報の縮約、という言葉で表現しようと思います。 例えば、こちらの資料 などで、ordinationと表現されていることが確認できます。
3章:主成分分析を行う手順について
1章では、固有ベクトルなどを利用して、各フルーツの第一主成分や第二主成分(っぽいもの)を基準にグループ分けし、データが見やすくなることを紹介しました。確かに、その固有ベクトルをうまい具合に求めることができれば、情報を2次元に圧縮でき、サンプル同士の関係などを見ることができそうです。また、2章では、その第一主成分、第二主成分を作るための固有ベクトルなどを紹介しながら、主成分分析について深めてきました。ただ、その固有ベクトル自体はどのように求めればよいのでしょうか。また、主成分分析を行うにあたって、他に注意すべき事や見るべき指標はあるのでしょうか。
3-1 情報の縮約について
次は、2次元の情報を1次元(直線)上に縮約することを考えます。以下の図を見てください。図中の5つのフルーツを甘さと丸っぽさに応じてプロットしてみました。甘さについては、各フルーツで違いがありますが、丸っぽさについては、どれも同じような形状をしていて、違いはないと思います。
ここで、これらの5つのフルーツを2つ(丸っぽさ・甘さ)の指標ではなく、1つの指標のみでかつ、違いがわかるように表したい場合はどうしたらよいでしょうか。例えば、フルーツかそうでないか、という指標を使うと、どれもフルーツなので、それらを見分けることができません。うまくそれぞれのフルーツの違いを残しつつ、少ない指標で各フルーツを表現したいです。

考えられる方法としては、以下のような表し方があるでしょう。甘さのみに絞って、以下のような直線上に並べます。

次に、丸っぽさを基準に表すとどうなるでしょうか。確かに柿よりゆずの方が丸っぽいのはわかりますが、グレープフルーツもみかんも同じくらい丸っぽく、この方式では、うまく情報を取り扱えていない印象があります。

甘さをもとに情報を縮約するほうがうまくできることは直感的にわかりましたが、どのように数式で表していけばよいのでしょうか。以下の図を見てください。甘さ方向では、情報に散らばりがあるため、甘さという軸をもちいてフルーツを並べれば1つの指標(=甘さ)のみで、かつ各フルーツを見やすくプロットすることができていました。一方、丸っぽさの軸にそった値は散らばりが少ないため、その軸にそって縮約しようとしても、各フルーツが重なってしまい、よいプロットができませんでした。

3-2 情報の散らばり(分散)について
3-1では、各フルーツが散らばっている軸を用いて情報を縮約することで、1つの軸のみで各フルーツを表していました。ここでは、なじみのあるフルーツで説明していたため、直感的に丸っぽさよりも甘さを用いた方が各フルーツを見分けられることがわかったかもしれません。しかし、実際には、「丸っぽさより甘さを用いた方が、良さそうだ!」といった事前の情報もなく、単に数値から判断する必要があります。それでは、数値のみから最適な縮約の基準を求めるにはどうしたらいいでしょうか。
それでは、具体的に、その散らばり具合を数値として計算し、最適な軸を選択していく準備をしていきます。以下の図を見てください。2.1でも扱いましたが、丸っぽさに関しては散らばりが小さく、甘さについては散らばりが大きいです。

上で議論した、散らばりに関しては、分散という指標で表すことができます。分散の式は以下の通りです。
分散に関しては、以下の記事などがわかりやすかったです。
分散について、分解して考えてみます。
1) について
はi番目のサンプル(ここでは、レモン、グレープフルーツ、みかん、ゆず、柿)に対して計算を行っていることを示します。例えば、甘さの分散を調べるとき、i番目のサンプルがレモンだったとすると、レモンの甘さの値(厳密には糖度ですがここでは甘さの値とします)のことです。
とはサンプル全体(ここでは、5つのフルーツの甘さ)の平均です。それで引き算を行うことで、i番目のサンプルの甘さがサンプル全体の平均と比べて、甘いのか(プラス)、甘くないのか(マイナス)を計算できます。
2) 2乗について
次は1)で計算した値を2乗します。ここでは散らばり具合を計算したいので、平均からみて、大きい値や小さい値が観測されるかどうかが重要です。散らばり具合においては、その平均からの差がどれくらいあるか知りたいです。単純にその差を足し算していくと、プラスとマイナスの要素が打ち消されて、0(=散らばっていない)に近い、誤った計算結果になります。ここで2乗の計算をすることで、その符号の違いによる打ち消しを避けることができます。
3) Σについて
1)や2)の計算は、i番目のサンプルに対する計算でした、全てのサンプル(ここでは5つのフルーツ)に対して計算を行い、その平均からの差の2乗の値を足し合わせたいので、Σによって、n個のサンプルにわたって足し算をしていくことを示しています。
4) について
n個のサンプルに対して平均との差の2乗を計算し、足し合わせることを行いました。しかし、これだけでは、サンプル数が多いほど、その値は大きくなってしまいます。そのため、サンプル数にて割り算をします。
これにより、散らばり具合を分散として計算することができるようになりました。しかし、これだけでは、どのように固有ベクトルを計算するかなどはまだわかりません。次の3-3節では、2次元のプロットを例に、PC1やPC2の軸を作ることを考えます。
3-3 主成分の軸について
3-2では単に、甘さの分散が大きいため、甘さという軸をそのまま用いていました。しかし、以下のような場合はどうでしょうか。横軸に甘さ、縦軸にオレンジっぽさ(黄色っぽさ)を示しています。次は、甘みだけでなく、色味においても分散が大きいです。同様に1つの軸のみで表現したい場合は、甘みだけでなく、色味もいい感じに利用して直線上で表したいですよね。色味でもばらついているので、その情報も用いたほうがより効果的そうです。

そこで、以下の図のように、斜め方向に第一主成分を取ることを考えます。先ほどは、甘みの軸をそのまま第一主成分としていましたが、今回は、甘さと色味を合成して作成した第一主成分になります。

以下の図に、第一主成分(太い青の矢印)を取り出したものを以下の図に示します。このように、第一主成分として、任意の方向をもつ軸を取ることができます。また、甘さの軸(x軸)での分散よりも、こちらの第一主成分における分散のほうが大きいと想像できます。

3-4 第一および第二主成分への写像
先ほどの図では、斜め方向に第一主成分をとりました。ここでは、それっぽく位置関係を保ったまま、第一主成分の図を作成しましたが、実際は、計算によって、(甘さ、色味)=(x, y)の値を、(第一主成分、第二主成分)=(z1, z2)の値に変換する必要があります。
例えば、第一主成分の値z1を計算するために、甘みx1, 色味x2から以下のような式を考えます。
,
は甘みx1, 色味x2にかける重みのようなものだと考えることができます。これは2-4で出てきた式と同様で、今回は2次元なので重みが2つしかないパターンです。
「新たな軸を作る」という凄そうなことをしている一方で、式は簡単な一次の線形結合で表されています。もう少し深めるために、以下の図を見てください。

左では、甘さと色味をもとにプロットしたもので、青色の矢印が、これから取る第一主成分軸を示しています。右側が、第一主成分、第二主成分が軸になるよう変換したものです。青色の軸から見ると、その軸まで各フルーツを垂直に下ろしてきた垂線の足の座標の値を第一主成分の値とし、第一主成分から各フルーツまでの距離を第二主成分の値としています。この第一主成分の原点とその垂線の足までの符号付きの距離のことを第1 主成分得点(スコア)といいます。
上の言葉の説明はややこしいですが、端的に言うと、原点を中心に各フルーツを回転させて、その回転後のx軸、y軸をそれぞれ第一主成分、第二主成分の軸としていると言えると思います。回転による座標変換は行列で表すことができて、原点を中心に反時計回りにθ°回転する時の変換式は
で表せます。これを展開すると、
となります。y2についても同様です。上の例では、x1, y1がそれぞれ甘みと色味になるので、重み1×甘み+重み2×色味という式の形で座標を回転させていますね。主成分分析の際も、重み1×変数1+重み2×変数2 ... という形で、もとの入力の値を変換していきますが、このような1次の線形結合の式の形になることはなんとなく想像できるかと思います。
(なお、「主成分分析は直交変換だ」と言われますが、直交変換の中に、回転も含まれます。そのため、主成分分析自体が回転だと言っているわけではなく、わかりやすい例として回転を挙げ、それが一次の式で表されていることを述べました。)
また、さらに、この重み(など)には制約があって、
を満たす必要があります。この制約をクリアした上で、x・yなどの値を変換し、その変換した後の変数の分散が最大になるような重みを求めていきます。なお、分散を最大化する軸をPC1(第一主成分)とし、その次に最大化する軸をPC2(第二主成分)などとしていきます。
以上から、主成分分析のための計算を行うときの大まかな手順として、
- . 対象の変数の値を得る(さきほどは、甘さ、色味という2つの変数を扱ったが、実際は、3以上の変数がある)
- . 変数の変換に用いる重みである固有ベクトルを超能力で知ったとする
- . 2で知り得た固有ベクトルと1の入力を掛け合わせ、第一主成分、第二主成分、、、の値を取り出し、分散を計算する
- . その分散がいろいろな固有ベクトルを取ったパターンの中で最大になっている
といった流れだと嬉しいです。問題は2の固有ベクトルをどのように知るかということですね。これに関しては、ひとまず固有ベクトルを未知数としておいて、目的変数(4.の分散)が最大になるように、式の計算をしていけば、その固有ベクトルを求めることができそうです。方針としては、固有ベクトルをx(以下では違う文字を使う)として、分散の最大化を目指して式を微分していく感じになります。
4章:主成分分析の具体的な計算について
4-1 分散の計算について
分散は2章で述べた通り、以下の式で求められます。
しかし、主成分分析の際は、行列で表した方がわかりやすく、行列で計算していく準備をしていきます。
例えば、以下のデータの分散を計算してみます。
分散を計算する際は、各サンプルから全体の平均を引き算していました。そのため、データの平均である5をデータの要素の数だけ用意します。これをデータ
とします。
すると、データXの各要素から平均5を引いた時の結果は以下のような式で表せます。その結果をとします。
つまり、先ほどの例では、以下のようになります。
そして、そのデータの分散は以下の式で計算できます。
Nはサンプルの数(3章では5つのフルーツを対象にしていたのでN=5)です。
これについて上の例を用いて補足します。
とはXを転置させたもので、
のことです。
を計算すると、
になって、行列の計算を行うと、
となります。分散の式
の2乗をして、総和Σを取るところまで、計算していることと等しいですね。
以下に、行列(Matrix)の計算がやりやすい、Matrix Laboratory (MATLAB)のコードを示します。
X=[-5:5]'; %-5から5まで(1刻み)の行列を作成 X'*X % Xの転置とXを掛け算する
ans = 110
結果が110となっていて、確かに正しい値が出ています。
最後にサンプル数であるNで割り算すると、分散を行列により求めることができます。
4-2 写像後の座標を計算する
次は、多次元のデータを2次元などに写像するときの計算について述べます。写像に用いる固有ベクトルをaとします。これは2-5で示した表中の重みに等しいです。d次元まで存在すると以下のような式になります。主成分分析の表の見せ方によりますが、固有ベクトルの表の縦や横をなどとして考えると良いです。
データに対して計算を行うと、
になります。は写像後の各主成分の値です。ここではデータXではなく、その平均を引いた値である
を用いています。これは主成分分析の際に重要視する分散と関連付けるためです。これについては3.3で述べます。
4-3 写像後の座標の分散の計算
写像した後の値sの分散 Var(s) を求めていきます。先ほどのデータXの例に沿って考えると、Xをそのままsに置き換えればよく、分散を求める式は以下のようになります。
また、sというのは、データにベクトルaをかけて求めたものなので、以下のようにも表せます。
また、という性質を用いて、
と書き換えることもできます。1/Nは単に数値なので順番を入れ替えることができます。これは1つ目の の箇所に対して転置行列の性質を用いています。
転置行列の性質に関しては、以下の記事が参考になりました。
https://manabitimes.jp/math/1046
すると、という部分が見えるようになると思います。これはつまり、先ほど計算した
に等しいですね。
そのため、で置き換えて、
となります。
3章で説明した通り、この分散が最大になっていれば嬉しい、ということでした。
そのため、 を最大化する固有ベクトルaの値を求めたいと思います。
さらに、aには
といった形(これはあくまで回転行列の例)のベクトルの大きさに対する制約を設けます。つまり、ここでは、aの大きさが1であるとします。
逆に大きさの制約がなければ、そのaを1.1倍、1.2倍...という要領で無限にそれっぽい値が出てきてしまいます。
4-4 ラグランジュの未定乗数による固有ベクトルの計算
4-3で述べたように、の値を最大化するベクトルaを求める方法について考えます。
最大化する対象:
拘束条件:
です。
このような拘束条件のもと、目的変数を最大化する際は、ラグランジュの未定乗数法が有効です。
未定乗数法の簡単な例を以下に示します。ラグランジュ方程式を用意し、さらに、その式を各変数に対して偏微分を行います。
例えば、以下のような制約と目的となる値があれば、ラグランジュの未定乗数法にて解くことができます。

詳しい内容については、以下の記事などがわかりやすかったです。
上の例に沿って、ラグランジュ方程式を立てていきます。最大化したい値から、拘束条件にラグランジュ乗数をかけて引き算したものを以下に示します。
はラグランジュ乗数 (Lagrange multiplier) です。
これを各変数で偏微分していきます。aについて偏微分を行うと以下のようになります。
ここでは、
を微分した値は
であることを利用しています(
は対称行列)。
は2次形式 (quadratic form) で表されていて、その性質を用いています。
2次形式について
のように、次数が2の多項式で表される式の形
という形で表すことができて、各種演算も簡単に実行できる。
例)を微分した値は 2Aw
この詳細については、以下のページが参考になりました。
また、この右辺のの値が0になればよいので、右辺の値を0とすると、
を得ることができます。
ここで、とすると、
となります。
はじめにaは固有ベクトルであると述べました。この式の形は、
固有ベクトルを求める問題で見たことがある方も多いと思います。
固有ベクトルの求め方は、ページ数の都合上割愛させていただきます。固有ベクトルの求め方については以下のサイトがわかりやすかったです。
ここまでの流れをまとめると
となります。これまで分散の最大化や制約条件など、難しそうな話が出てきましたが、最終的には
を解けばよいというシンプルな問題に帰着しました。AはXから平均値を引いた行列の分散なので、データがあればすぐに求めることができます。あとは、シンプルな問題であれば手計算でも解けますし、プログラミング言語のパッケージを用いればすぐに固有値や固有ベクトルを求めることができます。この上の手順に従い、計算すれば、各主成分で分散が最大になるような固有ベクトルが得られて、それをもって任意の次元に写像できるはずです。また、この固有ベクトルがそれぞれの主成分軸の向きと一致します。次の章では、実際にコーディングもしながら確認していきたいと思います。また、固有ベクトルが求まったのちには、その固有ベクトルが大きい順番に、第一主成分、第二主成分、と名付けていきます。先ほども同じ説明をしましたが、その時は、「分散」の大きい順に、と述べました。分散と固有値は、主成分分析においては一致するのですが、そのことについても後述いたします。
5章:3次元のデータに対して主成分分析を行う例
4.1では、1次元のデータの分散を求める例を示していました。基本的に、主成分分析は3次元以上のデータに対して行うため、この章では、3次元のデータに対してコーディングをしながら主成分分析を行いたいと思います。言語はMATLABを利用しますが、特にコードは見る必要がなく、結果とその説明だけ見ていただければ結構です。また、エクセルで行いたい場合は、吉村先生らのMicrosoft Excelを用いたケモメトリクス計算(4) -主成分回帰-が非常に参考になると思います。
5.1. 3次元データの生成
以下の媒介変数を用いた式を用いて、3次元上に平面っぽい点の分布を作ろうと思います。用いた平面の式は以下の通りです。
clear;clc;close all x = 1:50; % xの値を1から50まで生成 y = 1:50; % yについても同様 [X,Y] = meshgrid(x,y); % 上の範囲で、グリッド状に点を生成 Z=1-X-Y; % 平面の式からそのx、yの地点でのzの値を計算 X=X(:); % 変数の型を縦長に変更 Y=Y(:); % 変数の型を縦長に変更 Z=Z(:); % 変数の型を縦長に変更 figure;scatter3(X,Y,Z) % プロット

すると、等しい間隔で点の並んだ、3次元のプロットを得ることができました。非常にこの平面に自分が立っていると想像してください。すると、その真上(真下)方向は変動せず、前と横方向しか変動していないですね。そのため、以下の図のように、2つの軸を取ればうまく2次元にデータを縮約できるのではないかと考えられます。

ノイズを加えて、ぼんやり平面が見えるくらいのデータに加工します。
X=X+rand(2500,1)*10; Y=Y+rand(2500,1)*10; Z=Z+rand(2500,1)*10; figure;scatter3(X,Y,Z)

これにより、さきほどのくっきりとした平面ではなく、何となくそのデータに平面が隠れているようなプロットを得ることができました。次の項では、実際に主成分分析を行っていきます。直感的には、上の矢印で示したような主成分軸を取って、ほぼ(ノイズを乗せているため)2次元の平面に縮約できそうですね。
5.2. 主成分分析の実行
5.2.1. 自分で簡単に主成分分析を実装してみる
まずは、データの平均を引いて、を計算する必要がありました。ここでは、Xは3次元のデータです。文字がさきほどと被ってしまいますが、Xという変数にまとめてしまいます。
X=[X,Y,Z]; %X,Y,Z座標をXという1つのデータにまとめる X=X-mean(X); X(1:10,:) % 先頭から10個だけデータを表示する
ans = 10x3 -21.7379 -21.4437 45.5980 -23.9124 -22.2096 48.6382 -29.2875 -23.2099 51.4588 -21.3041 -24.9932 50.8562 -21.2549 -19.2303 44.0883 -22.8871 -16.1058 48.5032 -28.8589 -22.3273 43.9654 -24.9624 -14.9185 40.4330 -26.4127 -19.2797 45.7350 -25.0727 -13.5144 39.5227
このようにN×3の形(ここでは、N=2500)が入力のデータの形です。
次は、分散の計算をします。以下の式で求められると述べていました。
MATLABでは、転置は単にX'と「'」を付ければよいです。Xはすでに平均を引いたものです。
X_var=1/2500*(X')*X
X_var = 3x3 215.0796 -0.1363 -209.4993 -0.1363 217.4601 -209.1432 -209.4993 -209.1432 429.2478
以上のように分散が計算できました。厳密には、共分散行列を計算することができました。
例えば、A組の身長測定の結果が、各生徒で、170 cm, 181 cm, 168 cm, ...180 cmだった場合、それらの分散は
で計算することができ、数値が1つ得られるというものでした。
しかし、今回は3次元のデータを扱っているので、その結果として、以下のような共分散行列を得ることができます。

対角成分は、x, y, zの分散で、それ以外は、各変数の共分散になっています。
共分散はざっくりいうとその変数同士が似ているかどうかで、その共分散から相関係数を出すことができます。

ここで、Xからその平均を引いたの分散(共分散行列)が求まれば、あとは以下の固有値問題を解けばいいのでした。
MATLABではeig関数で一発で求めることができます。このように固有値の問題を解いて、固有値を求めてくれました。なお、固有値は大きい順に出てこないこともあるのでその場合は、固有値、固有ベクトルを大きい順に並べなおす必要があります。今回はその操作は行っていません。
X_eig=eig(X_var)
X_eig = 3x1
637.3103
216.4115
8.0656
戻り値を2つ設定すると、固有ベクトルと固有値の両方を得ることができます。
[V,D] = eig(X_var)
V = 3x3
-0.4058 0.7045 -0.5823
-0.4074 -0.7097 -0.5747
0.8181 -0.0040 -0.5750
D = 3x3
637.3103 0 0
0 216.4115 0
0 0 8.0656
これにより、固有ベクトルを得ることができました(変数名はVとしています)。最後に、入力のXにVを掛け合わせれば、各主成分に変換することができます。
score=X*V; figure;scatter3(score(:,1),score(:,2),score(:,3)) xlim([-60,60]);ylim([-60,60]);zlim([-60,60]);

5.2.2. MATLABの関数を使って、検算してみる
MATLABのpcaという関数を用いれば、一行で主成分分析を行うことができます。主成分スコアは、score2という変数に格納されているので、可視化してみます。自分で実装した、5.2.1の結果と同じになるはずです。
[coeff2,score2,latent2,tsquared2,explained,mu] = pca(X);
figure;scatter3(score2(:,1),score2(:,2),score2(:,3))
xlim([-60,60]);ylim([-60,60]);zlim([-60,60]);
xlabel('x axis');ylabel('y axis');zlabel('z axis')

このように、どちらの場合も同じ結果を得ることができました。また、第三主成分軸は値が約0.58のものが3つ続いています。もとの平面がx+y+z=1で、法線ベクトルが(1,1,1)だったので、その法線ベクトルの向きに第二主成分軸を取っていることが確認できますね。
coeff2
coeff2 = 3x3
-0.4058 -0.7045 0.5823
-0.4074 0.7097 0.5747
0.8181 0.0040 0.5750
さきほどの筆者の理解をもとに、自身で主成分分析を実装し、求めたときの固有ベクトル
V
V = 3x3
-0.4058 0.7045 -0.5823
-0.4074 -0.7097 -0.5747
0.8181 -0.0040 -0.5750
また、固有ベクトルを用いて、新たなPC1, PC2, PC3軸にプロットした時の値(主成分スコア)も一致していることがわかります(ベクトルの向きは正負が逆になることがあります)。初めから10個だけ取り出し、それを示します。
matlabのpca関数で求めた主成分スコア
score2(1:10,:)
ans = 10x3 54.8629 0.2770 1.2378 58.5446 1.2775 1.2796 63.4410 4.3654 -0.8033 60.4349 -2.5266 2.4741 52.5300 1.5017 1.9231 55.5314 4.8868 5.3069 56.7769 4.6598 -4.3552 49.2873 7.1590 0.1403 55.9904 5.1066 -0.1618 48.0153 8.2296 0.3596
さきほどの筆者の理解をもとに、自身で主成分スコアを求めたときの結果
score(1:10,:)
ans = 10x3 54.8629 -0.2770 -1.2378 58.5446 -1.2775 -1.2796 63.4410 -4.3654 0.8033 60.4349 2.5266 -2.4741 52.5300 -1.5017 -1.9231 55.5314 -4.8868 -5.3069 56.7769 -4.6598 4.3552 49.2873 -7.1590 -0.1403 55.9904 -5.1066 0.1618 48.0153 -8.2296 -0.3596
また、ノイズを乗せているため、完全ではないですが、XY平面からみると以下のように、主成分分析により、座標を変換したものは平面的になっていることがわかります。

6.6. 無相関化
主成分分析では、変換後の分散を最大化するべく、固有ベクトルを決定していました。変換後の変数(例:PC1)内の分散は最大化したとして、変数間(例:PC1とPC2) の分散はどうなっているでしょうか。さきほど、3.5.2の冒頭で、入力からその平均を引いた、共の分散行列を示しましたが、変換後の共分散行列はどうなっているでしょうか。scoreという名前の変数が、主成分分析後の座標の値でした。その共分散行列を求めてみます。
(score-mean(score))'*(score-mean(score))
ans = 3x3
1.0e+06 *
1.5933 -0.0000 -0.0000
-0.0000 0.5410 -0.0000
-0.0000 -0.0000 0.0202
このように、対角成分は正の値を持っている一方で、それ以外の共分散の値は0になっています。
再び、共分散行列について示します。

このように、変数間の相関(のようなもの)は0になることがわかります。例えば、xとyの値をプロットしてみます。
figure;scatter(score(:,1),score(:,2))

mdl = fitlm(score(:,1),score(:,2)); disp(['決定係数は',string(mdl.Rsquared.Ordinary),'である'])
"決定係数は" "-2.2204e-16" "である"
このように主成分分析後のxとyは相関がなく、決定係数も0になっていることがわかります。
このように主成分分析によって、変換された値(PC1、PC2...)どうしの相関は0になり、無相関化されます。
1章の可視化の例に加え、変数同士が相関しないように変換することも可能です。これは、例えば、重回帰分析に用いるデータにおいて、各変数に相関があるとうまくフィッティングできない場合があります(多重共線性)。これを避けるために
主成分分析が行われる場合があります。
7章 主成分分析について補足
4章では、具体的に3次元のデータで主成分分析を実行し、その挙動を確かめてきました。5章では、4章では紹介できなかった重要な事項について述べていきます。
7.1. 各主成分の説明性について
7.1.1. 累積寄与率と寄与率について
1章の例では、多次元の栄養データを2次元にプロットして可視化していました。4章の例を参考にすると、いろいろなデータで主成分分析を行うことができそうです。しかし、2次元にプロットすることは便利ですが、幾分か情報が失われているはずです。2次元では説明しきれない情報も多く存在しているはずで、その2次元のプロットによる可視化を中心に議論することの可否が気になるかと思います。その各主成分のもつ情報の割合を累積寄与率によって判断することができます。以下のように、各主成分の寄与率は、各主成分の分散を総分散で割ったものです。また、総分散とは各固有値の総和です(詳しくは後述する)。

また、累積寄与率は、その成分までの和です。例えば、5次元のデータに対して、2つ目の成分までの寄与率は、1および2つ目の寄与率の和を全寄与率で割ったときの値です。しかし、固有値と分散が等しいとされており、わかりにくいです。これについて次の項で説明します。

累積寄与率は、以下のコマンドで求められて、さきほどの3次元プロットの例では、3次元までしかないため、3次元まで寄与率を足すと100になっていて、第一主成分のみでは73.5、第二主成分まででは、99となっています。この値が80を超えると、そのデータをうまく説明できている、という目安です。
cumsum(explained)
ans = 3x1 73.9522 99.0641 100.0000
7.1.2. 分散と固有値について
主成分分散では写像後の変数の分散を最大化するように定式化してきました。以下に、分散と、ラグランジュ方程式で出てきた固有値λは等価であることを示します。
まず、写像後の変数の分散は以下のように表せるのでした。
また、という性質を用いて、
この式の中央に、の分散の式が見えると思います。そのため、以下のように表せます。
...☆
一方、ラグランジュの未定乗数法の際、
この式が成り立っていました。この式に対して、左からをかけると、
になります。また、上の☆の式からわかるように、この式の左辺は、写像後の分散と一致しています。
つまり、写像後の分散は、であると言えます。
さらに、のλの値はスカラー(5とか10とか)なので、前に出すことができて、
になります。aは単位ベクトルで大きさが1なので、写像後の分散はλ、つまり固有値に等しいことがわかります。
7.2. 各主成分は直交するのか?
主成分分析では、各入力の値を、主成分ベクトルとの掛け算で変換していました。分散が最大になるような軸をとって、変換していたので、ある軸を主成分に取ると、次に分散が最大になるのは、これまで取った軸では表せない軸、つまり、直交している軸を主成分として取ることがよさそうです。実際に各主成分は直交しているのですが、そのことをこの節で示したいと思います。
これまで述べたように、主成分分析では以下の図のように、分散が最も大きくなる向きに第一主成分軸を取り、その次に大きい分散の取れる軸を第二主成分軸とします。直感的には、第一主成分軸では表現できない方向を第二主成分軸で表現しようとすると、より大きな分散を取ることができそうです。

画像出典:株式会社インテージさま:主成分分析とは
ここでは、第一主成分軸と第二主成分軸が直交していることを示します。ただ、他の軸に対しても同様に説明できると思います。
ここでは、2つの固有ベクトルが直交することを示します。2つの固有ベクトルをx, yとします。
目標は、を示すことです。固有ベクトルx, yに対して以下の式が成り立ちます。
...★
2つ目の式に対して、両辺の転置行列を考えます。
ここで、に関しては、スカラーであるので、転置になっていません。
また、という性質を用いて、
になります。両辺をで割ると
になり、右からをかけます。
ここで、Aは共分散行列なのでです。そのため、
となり、★式より、
となります。スカラーであるを前に出して、
となります。
これらにより、
であり、式を整理して、
を得ることができました。であるとき、
となります。
これにより各固有ベクトルは直交することが示されました。
7.3. 因子負荷量について
1章のように、多次元の情報を第一主成分、第二主成分により、2次元でプロットすることでかなり情報が見やすくなりました。しかし、その場合、第一主成分や第二主成分は、どのような要素(例:第一主成分は炭水化物や脂質で主に構成されている)で成り立っているのかを知ることが、2次元でのプロットの解釈において非常に重要です。1章のバイプロットでは、単に固有ベクトルを表示していました。バイプロットではその固有ベクトルを表示させたり、または、この因子負荷量をプロットします。MATLABの公式ドキュメントでも、筆者の確認する限り、因子負荷量自体は、直接的にpca関数では計算されず、固有ベクトルをもって、各成分の寄与度を出していたように思いました。
以下のスライドは、統計科学研究所さまのスライドより引用しています。

引用:https://statistics.co.jp/reference/software_R/statR_9_principal.pdf
また、タコでもわかる主成分分析さまのページに以下の記述がございました。
因子負荷量の値がゼロに近づいたら、その因子が全く重要でなくなるかというとそうではありません。なぜなら、あるグループの観測データ群が数種の主成分と関係しているときには、因子負荷量値は低くなりがちなのです。
このような注意点にも気を付けながら、主成分分析の解釈を行っていきたいです。
7.4. データの標準化について
主成分分析のために、
1) 入力からその平均を引く
2) 入力からその平均を引く、そして、標準偏差で割る
といった前処理をします。主成分分析の記事では、2)の場合が多い印象がありますが、絶対に標準偏差で割る必要はないようです。
非常にわかりやすい記事がありましたので、以下にURLを掲載いたします。
また、入力からその平均を引かない場合でも、固有値や固有ベクトルの値は変わりません。共分散行列を求める際に、どっちみちその平均で引き算をするためです。
7.5. 主成分分析の解釈について
これまで、主成分分析による多次元データの解釈についてフルーツの例をもとに述べてきました。ただ、主成分分析の解釈については、あまり深く述べませんでした。例えば、PC1を「甘さと酸っぱさの軸」というふうに解釈をし、データどうしの関係などを議論する場合があります。ただ、その主成分分析の結果をどこまで解釈すべきかは、分野やその研究者によって別れるようです。以下は、鷲尾 泰俊 (著), 大橋 靖雄 (著)「多次元データの解析 (シリーズ入門統計的方法 3)」からの引用です。
=======以下引用======
主成分分析をどこまで解釈すべきかは研究者の意見の分かれるところである。主成分分析を因子分析の代用として用いている、主に心理系の研究者は主成分(因子)に名前を付け、それに実質科学上の解釈を与えようとすることに熱心である。一方、数理系の研究者は主成分分析を単なる座標変換と考え、その解釈には頓着しない傾向が強い。
実際の応用はこの両極の間で行われている。著者の立場はどちらかといえば、数理寄りのものであり、主成分分析の結果が重みにより、また後に例を挙げるように、用いるデータの質(異質性)や外れ値に依存することから、たまたま求まった因子負荷量のみに頼って仮説的な因子の存在を検証しようとする態度は行き過ぎのように考えている。主成分分析はオーディネーションを通じたデータの視察とデータの変動に対するイメージを解析者に与えるための手法というのが著者の見解である。 主成分をいくつまで解釈すべきかに対しても明確な回答は出し得ない。相関係数から出発する場合によく用いられている基準は、
累積寄与率が80から90%以上
固有値が1以上
といったものであるが厳密に適用する必要は全くない。一応の目安に考えれば良い 。
=======引用終わり======
とあります。データを2次元や3次元に縮約(オーディネーション)した結果を考察する際は、飛躍した結果を導きかねず、主成分分析の仕組みをよく理解した上で議論を行う必要があると感じました。
8章:まとめ
- この記事では、主成分分析を簡単な例を交えて説明しました。
- 分散を最大化するように新たな主成分軸をとり、固有ベクトルにより変換することで、点を写像することができました。
- 主成分分析は、データの可視化だけでなく、データの次元圧縮や、多重共線性を避けるための前処理など、様々な用途があるため、有効に使っていきたいと思います。
参考文献
宮田先生 Rを用いた主成分分析
http://www1.tcue.ac.jp/home1/ymiyatagbt/principal.pdf
統計科学研究所
https://statistics.co.jp/reference/software_R/statR_9_principal.pdf
VIVINKO:主成分分析の基礎
關戸先生 データ分析入門 第10回 主成分分析
http://www-is.amp.i.kyoto-u.ac.jp/data/sekido/20161213.pdf
吉村先生ら:Microsoft Excelを用いたケモメトリクス計算(4) -主成分回帰-
タコでもわかる主成分分析
PR曲線による平均適合率の計算について勉強&自分で書いて確認してみた
この記事では、物体検出を行ったときの精度の指標である、平均適合率について扱います。
この記事を執筆するにあたって、原田達也先生の「画像認識」の7.7.2 平均適合率を参考にいたしました。詳しくはこの本をご参照ください。
はじめに
ここでいう物体検出とは、以下の図のように、画像中から関心のある物体を検出することです。検出された物体は黄色の箱(以下、バウンディングボックスという)で囲まれていることがわかります。また、下の図では、あえて少し車の領域からずらしてバウンディングボックスを作成しています。
これを検出結果だとすると、この検出の結果を評価するためには、どうのようにすればよいでしょうか。代表的な物体検出の評価として、平均適合率によるものが挙げられます。この記事では、この平均適合率について勉強したことをまとめます。
また、この記事のために実装したコードは以下のgithubページにアップロードしています。
この記事は以下のような構成になっています。
1) 前半部分:平均適合率についての説明
2) 後半部分:前半部分の理解が正しいかを確かめるために実際に自分で実装してみる
2の部分でも、公式の関数と比べて、おおよそ正しい値が出ているので、大きな間違いはないとは思うのですが、私の理解違いやわかりにくい部分もあるかもしれません。その場合は教えていただけますと幸いです。

画像出典:What Is Object Detection? 3 things you need to know (以下も同様)
物体検出の評価をするときの準備
物体検出の性能を評価するためには、まず、正解となるバウンディングボックスの情報が必要です。下の図では赤色のバウンディングボックスで示されています。

はじめに示した、検出の結果(黄色のバウンディングボックス)と比べると、より車の領域を正しく捉えられていることがわかります。

このように、平均適合率では、正解データとしてのバウンディングボックスと、検出の結果としてのバウンディングボックスを比べ、計算していきます。
IoUについて
上の図では、2つの自動車を検出していて、どちらの検出も正しく行えていそうです。ただ、以下の例のように、検出結果(黄色)が、正解のバウンディングボックス(赤)に比べて、非常に小さかったり、横方向にずれていると、この検出結果は正しくないように見えます。

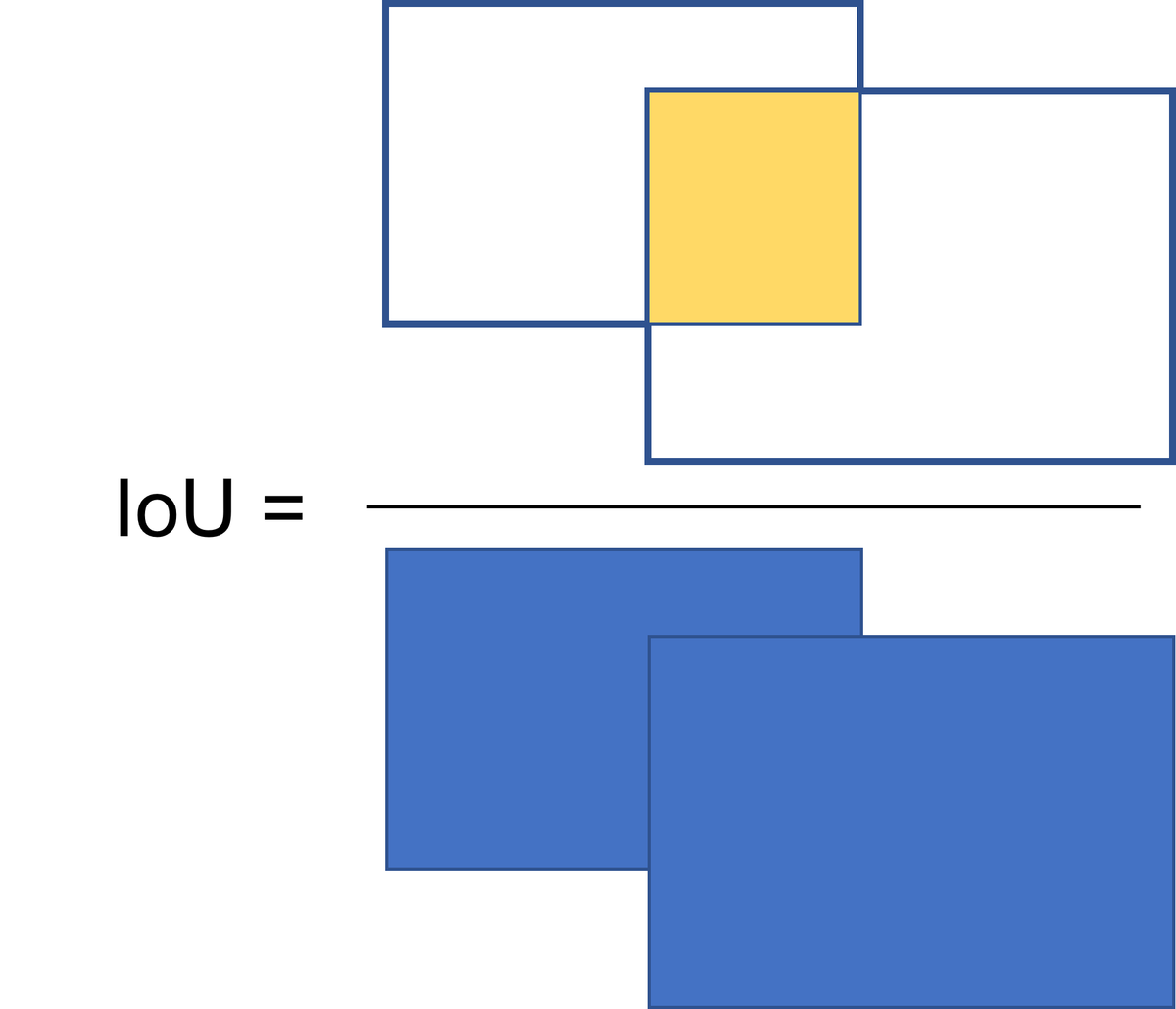
ここで、IoU (Intersection over Union)と呼ばれる指標を導入します。図示すると下のようになります。IoUは、正解と予測のバウンディングボックスの共通の重なり部分を、2つのバウンディングボックスを重ねたときの総面積で割り算したときの結果を指します。一般的には、このIoUの値が0.5以上だと正しく検出ができたとみなす場合が多いです。ただ、その時々の要求精度や、扱う物体によっては、0.5以外が良い場合もあるかもしれません。この値を他の値にすれば、もちろん後に計算する平均適合率の値も変化します。
物体検出において使われる指標の例は、以下のページに示されていて、
AP75 などがあることがわかります。これは、上のIoUの閾値として、0.5ではなく、0.75を用いています。
cocodataset.org
recall/precisionについて
上で説明したIoUに加え、recallやprecisionといった指標も必要になってきます。recallとprecisionについては、以下の記事などがわかりやすかったです。詳細については以下に示した、他の方の記事をご覧になってください。
平均適合率の計算で考えるべきこととして、
- . 検出器が自動で検出した物体が、実際にその物体であると嬉しい(ここに犬がいる、といって、実際にその領域に犬が存在していると嬉しい)
- . その画像に犬が5匹いたとすると、漏れなく5匹全て検出されると嬉しい
ということです。1のような、検出の結果が正しく犬を言い当てている、ということの大事さは想像することが容易です。ただ、正しかったらそれでいいだけでなく、2のように、その画像に存在する犬を、漏れなく発見することも大事です。
そのため、この平均適合率において重要な指標が2つあって、
ということなのではないかと個人的には思います。
分類のための指標(PrecisionとRecall)の解説
Precision, Recall, F値の気持ちを解釈してみる
スコアについて
物体検出のアルゴリズムにはスコアと呼ばれるような、その検出の信頼度を表す値を伴うことが多いです。感覚的に述べると、「○○%の確率でここにAという物体がある」といった感じです。平均適合率の計算では、スコアについてはこれくらいの認識で問題ないと思います。
バウンディングボックスの位置と大きさの表し方
バウンディングボックスの位置と大きさは、4つの値によって表すことができます。
例えば、[左上の角のx座標、y座標、ボックスの縦の長さ、横の長さ]というルールでバウンディングボックスを定義できます。
以下のコードで画像にバウンディングボックスを描き入れることができます。positionという変数でバウンディングボックスの位置と大きさを定義しています。60が横幅、40が高さを示しています。
im=imread('onion.png');
% =================
% この4つの値でバウンディングボックスの位置と大きさを設定できる
position=[121 5 60 40];
% =================
im_with_bbox=insertObjectAnnotation(im,'rectangle',position,'onion','TextBoxOpacity',0.9,'FontSize',10);
figure;imshow(im_with_bbox)

予測したバウンディングボックスと正解データからの平均適合率の計算
これまでのポイントとしては、
- IoU(ボックスの重なり具合)で検出の確からしさを評価できる
- 検出の際には、多くの場合、スコア(検出自体の確からしさ)が付与される
- 検出においては、その検出が正しいか (precision)ということと、対象となる物体が漏れなく検出されているか (recall)という指標が大事である
- バウンディングボックスの位置と大きさは左上の隅のx, y座標および縦横の長さの4つの値で表せる
ということでした。何となくこれらの指標やポイントを組み合わせて、検出の評価ができそうな気がしてきました。
次はその具体的な計算の手順について考えていきます。
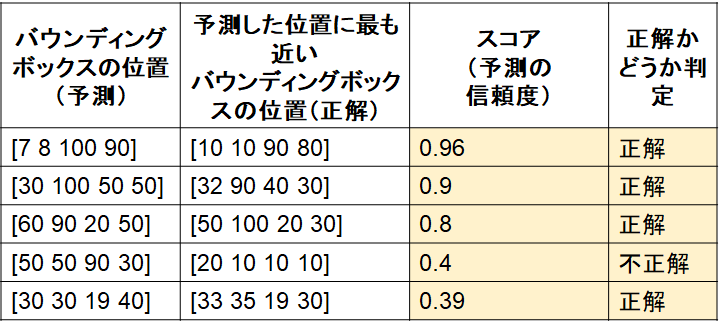
1) 検出したバウンディングボックスの位置と大きさ、正解のバウンディングボックスの位置と大きさ、検出したバウンディングボックスのスコアを表にまとめる
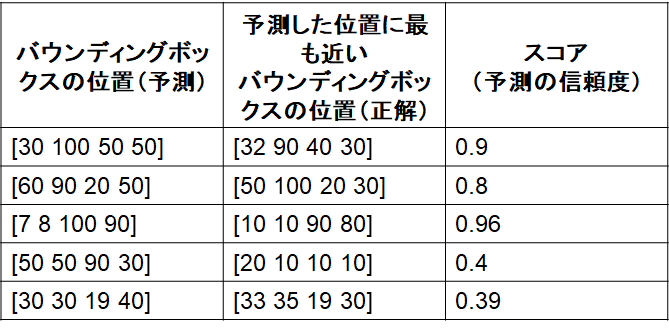
2) 1)で用意した表を、スコアに対して並び替え(高いもの順)
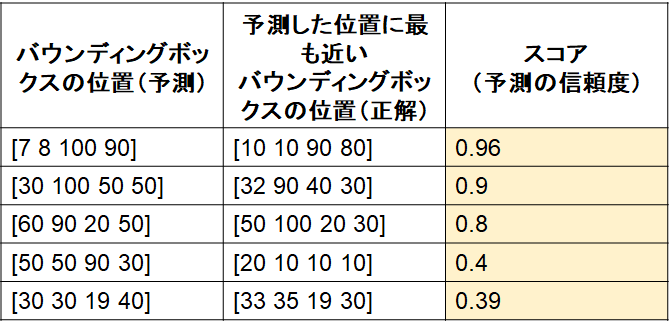
3) 2)の表に対して、IoUの基準(例:0.5)を設定し、正解かどうか判定
ここで、IoUは厳密に計算しておらず、仮に4つ目の検出のみ不正解であったとします。
4) recallとprecisionの計算
注意)ここでは、2値分類の時のrecall/precisionをそのまま当てはめて考えると少し混乱するかもしれません。以下の説明のように考えていただけると幸いです。
4-1 recallについて
この画像中に正解のバウンディングボックスが5個あったとします(つまり対象の物体が5個)。そのうち、今回は4つが正しく検出されています。その場合、表の上から、recallを1/5, 2/5, 3/5, 3/5, 4/5とします。この分母は、その画像中に含まれる物体の正解数です。検出器が検出した件数ではありません。3/5が2回続いていいますが、これは4番目が不正解の検出であったため、recallとしてカウントされていません。
4-2 precisionについて
この表の上から順番に、物体検出の問題の回答としてオープンしていくことを考えます。すると、1行目に関しては、はじめて回答した答えが正解したので 1/1, 2行目に関しても2つ回答して、2つとも正解なので2/2, 3つ目も同様に3/3, 4つ目は不正解なので3/4です。そして5つ目は正解しているので4/5ということになります。
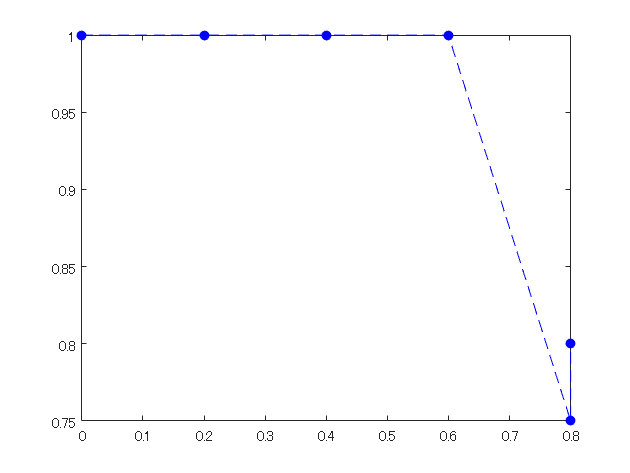
5) 4で計算した、recallとprecisionをそれぞれ、x・y軸の値としてプロットする
recall=[0,1/5, 2/5, 3/5, 4/5, 4/5]; precision=[1,1/1, 2/2,3/3,3/4,4/5]; figure;plot(recall,precision,'b--o','MarkerFaceColor','b')
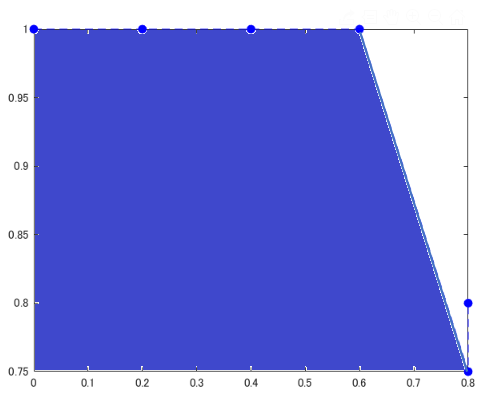
6) 5)の下側の領域の面積を計算する
この面積を平均適合率とします
補足
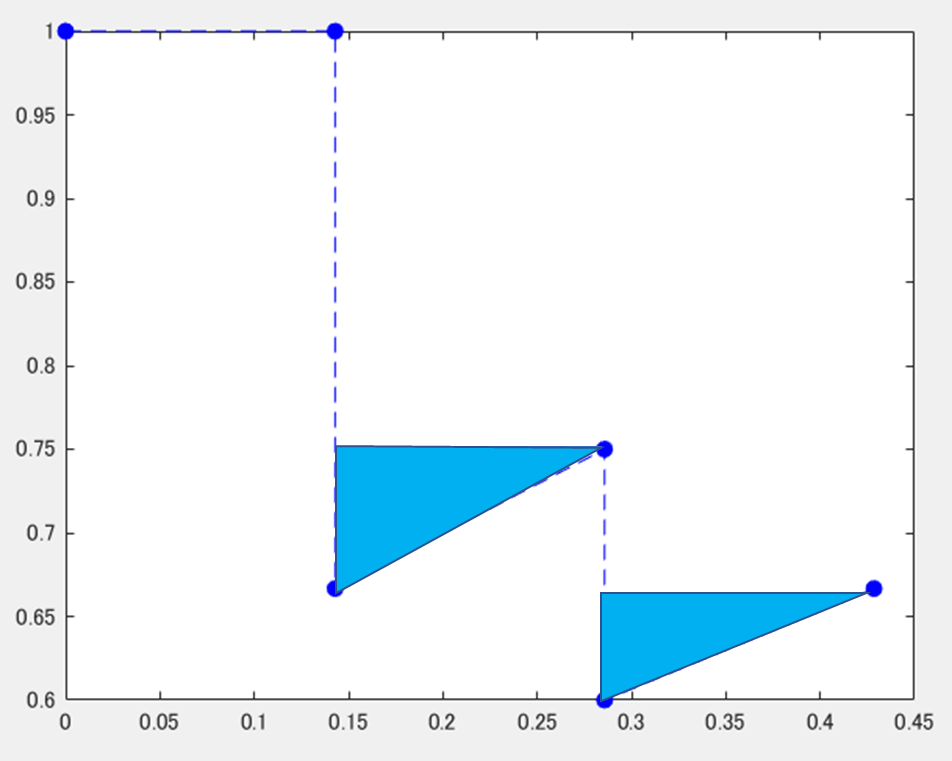
1) 右側での最大値での置き換え
以下の図のように、不正解=>正解という順番があって、途中でprecisionの値が向上したときは、水色の三角のように、値を大きくして補間することを行います。別の言い方をすると、各点に対して、右側の領域のもっとも大きい値で置き換えをしています。
2) サンプリングによる近似
以下の式のように、平均適合率を近似した形で求める場合もあるようです。ここでは、11の領域に分割し、0, 0.1, 0.2といった間隔でprecisionの値を見ます。そのときのprecisionの値をその区間の代表値として11個分足し合わせていきます。
3) mAPについて
各クラスに関して、上の平均適合率を計算し、その平均をとったものをmean Average Precision (mAP)という
平均適合率についておさらい
以上のような方法で、PR曲線を描き、その面積を求めることで平均適合率を求めることができました。
おさらいのために、どのような場合に平均適合率が大きくなるかをrecall, precisionに分けて考えていきます。
- recall について:PR曲線の下の面積が高いほど平均適合率が高い(検出の精度がよい)。ということは、recallも右側まで伸びている(つまり1に到達できる)場合に平均適合率が高くなる。しかし、むやみにたくさん検出すると次の箇条書きのprecisionが下がってしまう
- precisionについて:同様に、PR曲線の下側の面積を大きくするためには、縦の高さが大きい方がよい。正しく検出する場合に、precisionが大きくなる。自信のあるものだけを検出するようにすればprecisionも高くなるが、その場合は前の箇条書きのrecallが下がってしまう。
recall, precisionともに検出において重要な指標ですが、どちらかのみを高くしようとするともう片方が下がってしまうので、両方高くなるような検出、つまり正解データとほぼ同じ検出ができるとよい、ということがわかります。
このように簡単にですが、平均適合率についてまとめてみました。次に実際に自分で簡単なものを実装してみて、上の理解が正しいか確認したいと思います。
後半部分:自分で簡単に実装してみる
1 MATLABの公式の関数で平均適合率を計算する
まずは、正しい値を得るために、MATLABで公式にサポートされている関数にて平均適合率を計算します。
用いた例題は以下のページにあります。
https://jp.mathworks.com/help/deeplearning/ug/object-detection-using-yolo-v2.html
データは、この例題を実行したときの評価に用いるデータを使います。ここでは、そのときのデータをそのまま保存しているのではなくて、table変数で保存し、dataフォルダーに格納しています。table変数にすることでワークスペースから値の確認が簡単になります。
clear;clc;close all % 閾値の設定:IoUが0.5を越えると、「正しい」検出であると判断する thresh=0.5; % threshold over which the detection is judged as "correct" all_score=[]; % 公式ドキュメントの例題で用いているデータをロードする load groundTruth.mat load detectionResults.mat
evaluateDetectionPrecision関数を用いて、平均適合率や、recall, precisionを計算します。
[ap,recall_matlabFunc,precision_matlabFunc] = evaluateDetectionPrecision(detectionResults, groundTruth, 0.5); ap
ap = 0.7712
PR曲線のプロット
figure;plot(recall_matlabFunc,precision_matlabFunc);title('PR curve')
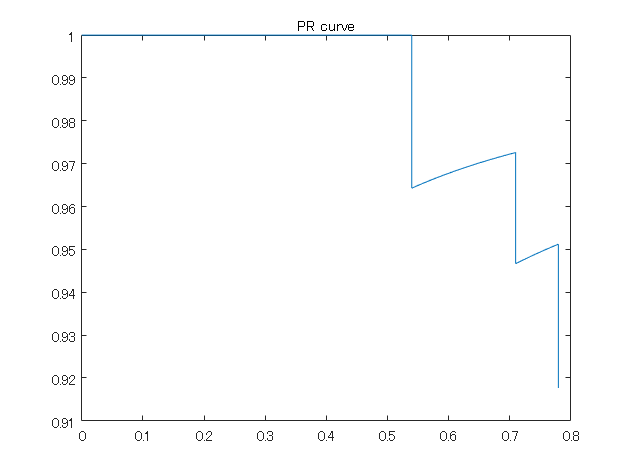
このようにここで用いているデータの平均適合率は約0.77でした。以下のように実際で実装してみて、おおよそこの値になることを目指します。
numel(recall_matlabFunc)
ans = 86
ここで、recallのサイズは86であることがわかります。この値は次のセクションで確認のため用います。
予測した検出、および正解の検出のデータの件数をカウントする
さきほどロードした、detectionResultsとgroundTruthという変数がそれぞれ予測した検出の結果、および正解のデータになっています。それぞれ、いくつの検出数があるか確認してみます。
num=0;
for i=1:size(detectionResults,1)
scoreAll=detectionResults(i,2);
scoreAll=numel(scoreAll.Scores{1});
num=num+scoreAll;
end
num
num = 85
検出した結果をみると、85個の検出結果があることがわかります。recallのサイズは86でした。確かに、recallのサイズは検出したバウンディングボックスの数+1であることがわかります。 +1というのは、recallが0から始めるためです。
次に、正解データ(変数名はgroundTruth)のバウンディングボックスの数を数えます。
numgt=0;
gt_vehicle=groundTruth.vehicle;
for i=1:size(groundTruth,1)
gt_i=gt_vehicle{i};
numgt=numgt+size(gt_i,1);
end
numgt
numgt = 100
この結果が示すように、正解データのバウンディングボックスの数は100個であることがわかります。
MATLABの公式の関数で計算した、recallの値であるrecall_matlabFuncを参照すると、recallの幅は、0.01(つまり1/100)の間隔で増えていっていることがわかります。つまり、正解が100個あるので、その100という数を全体として、1つ検出するごとに0.01増えていくことになります。
recall_matlabFunc(1:5)
ans = 5x1
0
0.0100
0.0200
0.0300
0.0400
一方、81番目から84番目のrecallを表示させてみます。
recall_matlabFunc(81:84)
ans = 4x1
0.7600
0.7700
0.7800
0.7800
このように、0.78が2回続きます。これは、84番目の検出が不正解(IoUが0.5以下)なので、recallとして認定されず、recallが増加していないことを示しています。
FOR文にて、各検出されたバウンディングボックスが正しいか判断する
各画像に紐づいたバウンディングボックスとその正解データ、そのときのscoreを抽出し、IoUを計算します。
画像の中でもさらに複数のバウンディングボックスがあるため、for文が2つ組み込まれています。
bbox_ind=1; % index of bounding box
for i=1:size(detectionResults,1)
bboxes=detectionResults(i,1); % retrieve bounding boxes in i-th image
bboxes_i=bboxes.Boxes{1}; % cell2table
scores=detectionResults(i,2); % scoreを追加
scores_i=scores.Scores;
if size(bboxes_i,1)>0
for j=1:size(bboxes_i,1)
bbox_i=groundTruth.vehicle;
bboxes_j=bboxes_i(j,:);
score_j=scores_i{1};
catb=cat(1,bbox_i{i});
% calculate iou
overlapRatio = bboxOverlapRatio(bboxes_j,catb,'Union');
overlapRatioMax = max(overlapRatio);
if overlapRatioMax > thresh
all_score(bbox_ind)=score_j(j);
iscorrect(bbox_ind)=1;
else
all_score(bbox_ind)=score_j(j);
iscorrect(bbox_ind)=0;
end
bbox_ind=bbox_ind+1;
end
end
end
recallとprecisionを計算
バウンディングボックス自体は存在しても、そのIoUが0.5未満だと正解だとみなされないため注意が必要です。
recall=0; % initialization of recall
precision=1;% initialization of precision
[all_score,scoreInd] = sort(all_score,'descend'); % sort score
iscorrect=iscorrect(scoreInd); % sort by score
for k=1:bbox_ind-1
% see iscorrect to check if the i-th bbox is correct
if iscorrect(k)==1
recall(k+1)=recall(k)+1/numgt;
precision(k+1)=sum(iscorrect(1:k)/k);
else
recall(k+1)=recall(k);
precision(k+1)=sum(iscorrect(1:k)/k);
end
end
figure;plot(recall,precision);
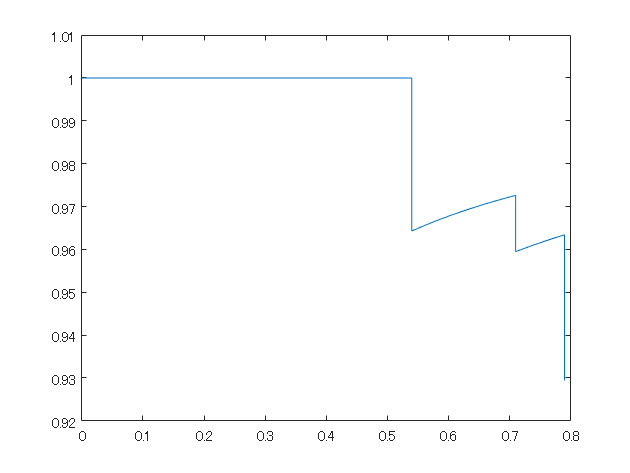
平均適合率を計算
MATLABの公式の関数で計算したときの値とおおよそ合致していることがわかります。
※補足にて説明した、右側での最大値での置き換えは行っていません。
v=1;ap=0;
for l=1:numel(precision)-1
precision_i=precision(l);
ap=ap+(recall(l+1)-recall(l))*precision_i;
end
ap
ap = 0.7816
まとめ
- この記事では、PR曲線から平均適合率を計算する手順について説明しました
- 前半では平均適合率を計算する方法について説明しました
- 後半では、実際に自分で簡単に実装してみて、MATLABの公式の関数で計算された値とおおよそ一致することを確かめました
- もし間違いやご質問などがございましたら、ご連絡いただければ幸いです
Directions API (Google Maps Platform) を jupyter notebookからコールしてルート間の距離と所要時間を取得する
この記事では、Directions API(Google Maps Platform) を jupyter notebookからコールして、京セラドームから大阪環状線の各駅までの距離と所要時間を自動的に取得する方法について勉強したのでここにまとめたいと思います。
例えばスマホにインストールしたGoogle Mapのアプリから手動で任意の2地点を入力すれば、そこまで移動するときの距離や時間がわかりますが、複数の地点があれば毎回入力するのは大変です。そこで、ここでは、任意のまでの距離や時間を自動的に計算すべく、Directions APIを利用します。
距離と時間を計算するコードはこちらの、kngsym2018さまのブログを参考にさせていただきました。
航空写真を取得するコードに関しては、こちらのSpooky_Maskmanさまのブログを参考にさせていただきました。
この記事は、上の二つの記事をもとに、大阪環状線の情報を用いて勉強したときのまとめになっていて、特に技術的には新たな情報はありませんが、下のページにコードやデータをアップロードしているので、何かの役に立てば幸いです。
APIキーの取得
まずはじめに、jupyter notebookからGoogle Maps PlatformにアクセスするためにAIPキーを取得する必要があります。その取得については、以下の記事がわかりやすかったです。こちらをご参照ください。
京セラドーム大阪 ~ 大阪環状線の各駅までの距離を調べるコードについて
モジュールのインポート
import numpy as np import pandas as pd import geocoder as ge from geopy import distance import csv import json import requests #import urllib.requests, json import urllib.parse import datetime import googlemaps import cv2 import matplotlib.pyplot as plt %matplotlib inline
目的地のリストを読み込み&簡単な後処理
インターネットから自動的に大阪環状線の駅名のリストを得ることも可能な気もしますが、ひとまずCSVファイルに駅名のリストを保存しています。
df = pd.read_csv('test.csv', encoding="shift-jis") # カラム名'loop_line_station'列を取り出す address = df['loop_line_station'] # Dtaframe⇒listに変換 address_list = address.to_list() print(address_list)
['天王寺', '寺田町', '桃谷', '鶴橋', '玉造', '森ノ宮', '大阪城公園', '京橋', '桜ノ宮', '天満', '大阪', '福島', '野田', '西九条', '弁天町', '大正', '芦原橋', '今宮', '新今宮']
Google Maps Platform Directions API endpointとAPIキーの設定
APIキーはご自身で取得したものを入力してください
endpoint = 'https://maps.googleapis.com/maps/api/directions/json?' api_key = 'aaaaaaaaaaaaaaa-BBBBBBBBBBBBBBBBBBB'
各駅の緯度経度をforループで取り出し、京セラドーム大阪からの運転距離と運転時間を求める
# 運転距離と運転時間の結果を入れる空の配列を作成 duration=[] distance=[] for i in range(len(address)): dep_time = '2022/1/6 6:00' origin='京セラドーム大阪' destination = address_list[i] + '駅 大阪' print(destination + " について検索中") # UNIX時間への変換 dtime = datetime.datetime.strptime(dep_time, '%Y/%m/%d %H:%M') unix_time = int(dtime.timestamp()) # 実行内容 nav_request = 'origin={}&destination={}&departure_time={}&key={}'.format(origin,destination,unix_time,api_key) nav_request = urllib.parse.quote_plus(nav_request, safe='=&') request = endpoint + nav_request # 上のrequestをもとに、google Maps Platform Directions APIを実行 response = urllib.request.urlopen(request).read() #結果(JSON)を取得 directions = json.loads(response) #所要時間を取得 for key in directions['routes']: # print(key) # titleのみ参照 # print(key['legs']) for key2 in key['legs']: duration_i=key2['duration_in_traffic']['text'] duration.append(duration_i) distance_i=key2['distance']['text'] distance.append(distance_i)
天王寺駅 大阪 について検索中
寺田町駅 大阪 について検索中
桃谷駅 大阪 について検索中
鶴橋駅 大阪 について検索中
玉造駅 大阪 について検索中
森ノ宮駅 大阪 について検索中
大阪城公園駅 大阪 について検索中
京橋駅 大阪 について検索中
桜ノ宮駅 大阪 について検索中
天満駅 大阪 について検索中
大阪駅 大阪 について検索中
福島駅 大阪 について検索中
野田駅 大阪 について検索中
西九条駅 大阪 について検索中
弁天町駅 大阪 について検索中
大正駅 大阪 について検索中
芦原橋駅 大阪 について検索中
今宮駅 大阪 について検索中
新今宮駅 大阪 について検索中
df_distance=pd.DataFrame(distance,columns=['distance']) df_duration=pd.DataFrame(duration,columns=['duration']) df_result = pd.concat([pd.DataFrame(address),df_distance,df_duration],axis=1) df_result.head(20)
| loop_line_station | distance | duration | |
|---|---|---|---|
| 0 | 天王寺 | 9.1 km | 14 mins |
| 1 | 寺田町 | 10.2 km | 17 mins |
| 2 | 桃谷 | 6.0 km | 19 mins |
| 3 | 鶴橋 | 5.1 km | 17 mins |
| 4 | 玉造 | 7.2 km | 14 mins |
| 5 | 森ノ宮 | 6.7 km | 12 mins |
| 6 | 大阪城公園 | 7.7 km | 15 mins |
| 7 | 京橋 | 7.9 km | 16 mins |
| 8 | 桜ノ宮 | 9.3 km | 17 mins |
| 9 | 天満 | 7.8 km | 14 mins |
| 10 | 大阪 | 4.9 km | 14 mins |
| 11 | 福島 | 4.4 km | 13 mins |
| 12 | 野田 | 3.9 km | 11 mins |
| 13 | 西九条 | 4.4 km | 12 mins |
| 14 | 弁天町 | 2.1 km | 6 mins |
| 15 | 大正 | 0.6 km | 3 mins |
| 16 | 芦原橋 | 2.6 km | 9 mins |
| 17 | 今宮 | 3.0 km | 10 mins |
| 18 | 新今宮 | 3.8 km | 12 mins |
結果を見てみる
何となく正しく検索できている気がします。ただ、大正駅までの距離がかなり近くて、数分で行けてしまうようですね。衛星画像を用いて正しそうか確認してみたいと思います。
下準備1: 大正駅の経度と緯度を取得する
gmaps = googlemaps.Client(key=api_key) address = u'大正駅' result = gmaps.geocode(address) lat = result[0]["geometry"]["location"]["lat"] lon = result[0]["geometry"]["location"]["lng"] print (lat,lon)
34.6657822 135.4792475
下準備2: 大正駅を中心とした衛星画像を取得する
こちらのコードは上の、Spooky_Maskmanさまのブログを参考にしています。
# 画像を保存する際のパラメータの設定 output_path = %pwd pixel = '640x480' scale = '16' # htmlの設定 html1 = 'https://maps.googleapis.com/maps/api/staticmap?center=' # maptypeで取得する地図の種類を設定 html2 = '&maptype=hybrid' # sizeでピクセル数を設定 html3 = '&size=' # sensorはGPSの情報を使用する場合にtrueとするので今回はfalseで設定 html4 = '&sensor=false' # zoomで地図の縮尺を設定 html5 = '&zoom=' # マーカーの位置の設定(マーカーを表示させてくなければ無でも大丈夫) html6 = '&markers=' # key="googleから取得したキーコード"となるように設定 html7 = '&key=' # 緯度経度の情報をセット axis = str(lat) + "," + str(lon) # url url = html1 + axis + html2 + html3 + pixel + html4 + html5 + scale + html6 + axis + html7 + api_key # pngファイルのパスを作成 dst_path = output_path + '\\' + "TaishoStation.png" # 画像を取得しローカルに書き込み data = urllib.request.urlopen(url).read() with open(dst_path, mode="wb") as f: f.write(data)
大正駅と京セラドーム大阪を可視化
確かに、大正駅と京セラドーム大阪はかなり近く、数分でいけてしまうのも納得です。
img = cv2.imread('TaishoStation.png') img2 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) fig = plt.figure(1, (12., 12.)) plt.imshow(img2)

まとめ
CNNのためのデータ拡張法を勉強&簡単に実装してみた (RandomErasing, CutOut, MixUp, Sample Pairing)
この記事はMATLAB/Simulink Advent Calendar 2021の9日目の記事として書かれています。
また、過去の記事はこちらのブログトップからアクセスいただけると幸いです。
はじめに
本記事では、畳み込み込みニューラルネットワーク(CNN)に役立つ、データ拡張の手法を勉強したので、簡単にまとめ、実装の例を示したいと思います。間違いなどがあれば教えていただけますと幸いです。
データ拡張では、分類や物体検出をする際に、回転や、反転、移動、せん断、色味の変更などを加えることで、訓練データのバリエーションを高め、認識精度を高めるために行います。
以下のページでは、その例が画像と共に紹介されているのでイメージがつきやすいです。
また、上のような多種多様なデータ拡張も、そのオプションを1行書き加えるだけで実行可能な場合が多く(以下の記事はMATLABの例)、非常に簡単にデータ拡張も試せるようになっています。
それ以外のデータ拡張の手法の例
上で述べたシンプルな方法に加えて、その他にも有効なデータ拡張の手法が知られています。ここでは、
1) random erasing や CutOut 2) Mix-upやSamplePairing の2つを紹介したいと思います。
Random Erasing について
ここで紹介する私の実装のコードについては、以下のページからダウンロードできます。
MATLABで行う場合、公式からも関数が提供されています。 jp.mathworks.com
Random Erasingの論文は以下のとおりです。
cutoutの論文は以下の通りです。
Random Erasingのイメージは、以下の論文の図がわかりやすいです。画像にグレーのマスクや、ランダムな色のマスクがかかっていますね。
rectangle region in the image and erase its pixels with random values or the ImageNet mean pixel value
ランダムな値や、ImageNet内の画像のピクセル値の平均値(おそらくグレーにちかい)でマスクをすると論文中にも書いています。

図出展:Zhongら (2017) [1] より
また、動画にすると以下のようなイメージです。

また、cutoutについても同様で、以下の図が論文中にあります。ひとまずこの記事では、特にrandom erasingとcutoutの区別はせず、訓練画像にマスクをかけてデータ拡張を行う方法を試します。

ここでのパラメータとしては、マスクをかけるときのマスクの大きさや縦横比の範囲、マスクの色(例:ランダムか、白か、グレーか黒か)、マスクの数(もしそのようなカスタマイズをしたい場合は)などが考えられます。論文中でも、そのような条件を変えて実験をしているので、詳しいパラメータと精度やデータセットの関係はもとの論文を参照いただけますと幸いです。
以下に、私の方で実装したコードで、CIFAR-10を用いて比較したときの結果です。左がRandom Erasingを行った場合、右がそうでない場合です。左のRandom Erasingがある場合は、テストデータによる分類精度は77.6%で、ない場合は73.1%と、確かに精度が高まりました。今回は非常にシンプルなネットワークで行っているということもあり、論文よりはずいぶんと精度が低いです。

random erasing/cutoutの効果について
論文中にもあるとおり、確かにこれらの方法を用いることで精度の向上を確認することができました。例えばcutoutの論文には、
cutoutの主なモチベーションは、物体が隠れてしまう(オクルージョン)問題への対処です。オクルージョンは物体認識、物体追跡、姿勢推定など、多くのコンピュータビジョンのタスクにおいて発生する問題です。マスクをかけて新しい画像を生成することで(データ拡張をすることで)、より多くの画像の文脈(規則性や連続性など)を考慮するよう学習させることができます。
とあります。
また、random erasingの論文でも、オクルージョンのあるテストデータには、CNNがうまく機能しないことが考えられ、オクルージョンは非常に悩ましいことである、との記述があります。実際に本文中で、テストデータにもマスクをかけて(オクルージョンを作って)分類精度を確認したところ、random erasingを用いて学習したモデルがうまく機能すると確認されています。
実際にオクルージョンがある画像セットを用意して、random erasing/cutoutの有無でどのようなテスト結果になるかを比べるとオクルージョン対策が成功し、分類精度が向上したのかどうかの確認につながりそうな気がしました。

Mix-up / SamplePairingについて
次に、Mix-up や SamplePairingについて紹介します。
もととなる論文は以下のとおりです。
私のほうで簡単に実装したコードはこちらになります。混ぜる比率を単純に一様分布からランダムに決めています。
これらの方法では、マスクをして一部を隠すのではなく、以下のように、画像どうしをブレンドします。以下の例では、自動車と梨の画像がブレンドされていることがわかります。そして、例えば色味を1:1でブレンドした場合は、正解データを0.5ずつ分け与えます。例えば、その分類では、犬、猫、牛を扱っていて、犬と猫の画像をブレンドした場合、正解ラベルは [0.5, 0.5, 0] とします。ブレンドする比率を変えることも可能です。
I1=imread('car2.jpg');
I2=imread('pears.png');
Iblend=imfuse(I1,imresize(I2,[size(I1,1),size(I1,2)]),'blend');
figure;montage({I1,I2,Iblend});

また、Inoue (2018) [4] から以下の図を引用しています。SamplePairingがある場合とない場合では、ある場合のほうが誤差が低く、分類の問題に対して効果的であると示されています。また、SamplePairingにおける、設定を複数試していますが、どの場合もbaselineの方法よりも性能がいいことがわかります。

図出展:Inoue (2018) [4] より
以下の右側の図(mixup)にあるとおり、画像どうしを混ぜ合わせて、それに応じてラベルの値も0と1の間を取るので、クラスどうしの境界面にグラデーションができていることがわかります。これにより、正則化の効果がうまれ、認識精度が向上するようです。正則化に関しては、dropoutとの比較も本文中にありました。

出展:Zhang, Hongyi et al. (2017) [3] より.
mix-upに関する考察に関してはこちらの記事が参考になりました。 www.inference.vc
次に読みたい論文
このmix-upと関連する論文の中で、特に次に読みたい論文と参考になる記事を挙げます。
- BC-learning: Mixupはただ2枚の異なる画像を混ぜるだけなのに対して、BC-Learningは異なるクラスの異なる2枚の画像を混ぜるのだそうです
www.slideshare.net
- Cutmix: cutoutとmixupを合わせたような方法
- Manifold mixup: Manifold Mixuでは、より特徴量が整理された中間層で混ぜるMIXUPを行うデータ拡張手法だそうです。